HBase CURD之Put
来源:互联网 发布:怎么学习淘宝运营 编辑:程序博客网 时间:2024/06/04 22:13
HBase CURD之Put
HBase数据插入使用Put对象,Put对象在进行数据插入时,首先会向HBase集群发送一个RPC请求,得到相应之后将Put类中的数据通过序列化的方式传给HBase集群,集群节点接收到数据之后进行添加功能。
单行插入
单行插入即每次只插入一行数据,下面先看一个插入一条数据的代码:
@Testpublic void testPut() throws IOException { Connection conn = ConnectionFactory.createConnection(); HTable table = (HTable) conn.getTable(TableName.valueOf("ns1:t1")); Put put = new Put(Bytes.toBytes("row1")); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("id"), Bytes.toBytes(1)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"), Bytes.toBytes("tom")); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes(15)); table.put(put); table.close(); conn.close();}从上面的代码可以看出插入一条数据是使用HTable对象的put方法添加,put方法中的参数是Put对象。好下面就来讲讲Put对象。
Put的构造函数
public Put(byte [] row) // 只指定rowKeypublic Put(byte [] rowArray, int rowOffset, int rowLength) // 从一个字节数组中指定rowKeypublic Put(byte [] rowArray, int rowOffset, int rowLength, long ts) // 从一个字节数组中指定rowKey,并且设置时间戳public Put(byte[] row, long ts) // 指定rowKey和时间戳public Put(ByteBuffer row)public Put(ByteBuffer row, long ts)public Put(Put putToCopy) // 从其他put对象拷贝创建Put对象时用户必须指定rowKey,在HBase中每行数据都有一个唯一的行键(rowKey)作为标识,跟HBase的大多数数据类型一样,它是一个字节数组。用户可以按照自己的需求指定每行的行键。通常情况下,rowKey的含义与真实场景相关,例如他的含义可以是一个用户名或者订单号,它的内容可以是简单的数据,也可以是比较复杂的UUID(全局统一标识符)等。
HBase为用户提供了一个包含很多静态方法的辅助类,这个类可以将许多java数据类型转换为字节数组。
Bytes类中的静态方法
public static byte[] toBytes(ByteBuffer bb)public static byte[] toBytes(String s)public static byte[] toBytes(boolean b)public static byte[] toBytes(long val)public static byte[] toBytes(float f)public static byte[] toBytes(int val)创建Put对象之后,就可以向该对象中添加数据了,添加数据的方法如下:
public Put add(Cell kv)public Put addColumn(byte [] family, byte [] qualifier, byte [] value)public Put addColumn(byte [] family, byte [] qualifier, long ts, byte [] value)public Put addColumn(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value)每一次调用add()或者addColumn()方法都可以添加一行数据,如果再加上一个时间戳选项,就能成为一个数据单元格。注意,当不指定时间戳时,Put对象会使用来自构造函数中的可选时间戳,如果用户在构造Put对象的时候也没有指定时间戳,则时间戳将会由regionServer设定。
系统为一些用户提供了Cell实例的变种,这里说的高级用户是指知道怎样检索或创建这个内部类的用户。Cell实例代表了一个唯一的数据单元格,类似于一个协调系统,该系统使用行键、列族、列限定符、时间戳指向一个单元格的值,像一个三维立方体系统。
获取Put对象内部的Cell对象需要调用以下方法:
public List<Cell> get(byte[] family, byte[] qualifier)public NavigableMap<byte [], List<Cell>> getFamilyCellMap()以上两个方法可以查询用户之间添加的内容,同时将特定单元格的信息转换成Cell对象。用户可以选择获取整个列族的全部数据单元,一个列族中的特定列或者是全部数据。后面的getFamilyCellMap()方法可以遍历Put对象中的每个可用的Cell对象。
用户可以采用以下方法检测是否存在特定的单元格,而不需遍历整个集合:
boolean has(byte[] family,byte[] qualifier)boolean has(byte[] family,byte[] qualifier,long ts)boolean has(byte[] family,byte[] qualifier,byte[] value)boolean has(byte[] family,byte[] qualifier,long ts,byte[] value)Put类的其它方法
客户端的写缓冲区
每一个put操作实际上都是一个RPC操作,它将客户端数据传送到服务器然后返回。这只适合小数据量的操作,如果有个应用程序需要每秒存储上千行数据到HBase表中,这样处理就不太合适了。
Tip
减少独立RPC调用的关键是限制往返时间,往返时间就是客户端发送一个请求到服务器,然后服务器通过网络进行相应的时间。这个时间不包含 数据实际传输的时间,它其实就是通过线路传送网络包的开销。一般情况下,在LAN网络中大约要花1ms的时间,这意味着在一秒的时间内只能完成1000次RPC往返相应。
另一个重要的因素就是消息大小。如果通过网络发送的请求内容较大,那么需要请求返回的次数相应较少,这是因为时间主要花费在数据传递上。不过如果传送的数据量很小,比如一个计数器递增操作,那么用户把多次修改的数据批量提交给服务器并减少请求次数,性能会有相应提升。
HBase的API配备了一个客户端的写缓冲区,缓冲区负责收集put操作,然后调用RPC操作一次性将put送往服务器。全局交换机控制着该缓冲区是否在使用,以下是其方法:
void setAutoFlushTo(boolean autoFlush)boolean isAutoFlush()默认情况下,客户端缓冲区是禁用的。可以通过将自动刷新设置为false来激活缓冲区,调用如下: table.setAutoFlushTo(false)
激活客户端缓冲区之后,将数据存储到HBase中。此时的操作不会产生RPC调用,因为存储Put实例保存在客户端进程中的内存中。当需要强制把数据写到服务器时,可以调用table.flushCommits()。
flushCommits()方法将所有的修改传送给远程服务器。被缓冲的Put实例可以跨多行。客户端能够批量处理这些更新,并把他们传送到对应regionServer。和调用单行put()方法一样,用户不需要担心数据分配到了哪里,因为对于用户来说,HBase客户端对这个方法的处理是透明的,下图展示了在客户端请求传送到服务器之前是怎样按regionServer排序分组,并通过每个regionServer的RPC请求将数据传送到服务器的。
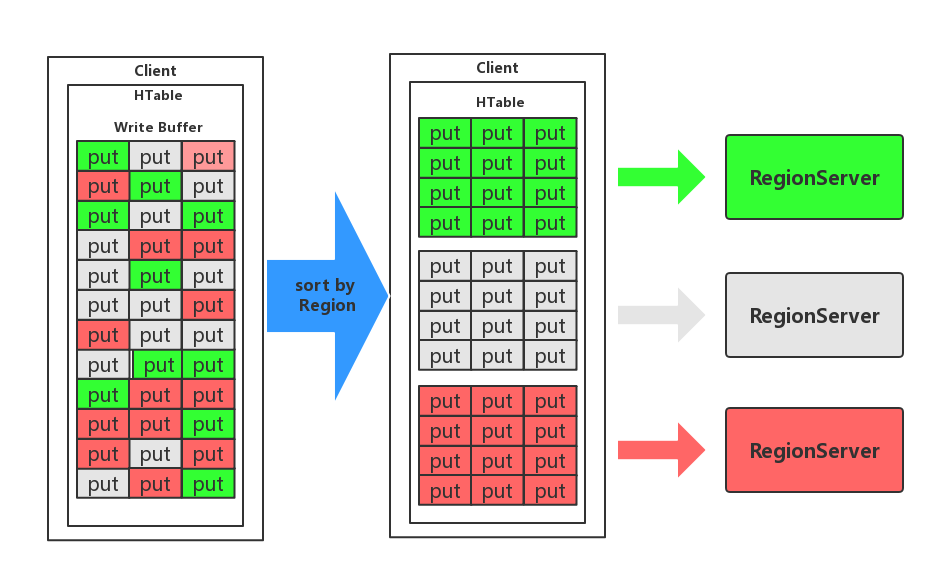
缓冲区仅在两种情况下会刷新
- 显示刷新
- 用户调用flushCommit()方法,把数据发送到服务器做永久存储。
- 隐式刷新
- 隐式刷新会在用户调用put或setWriteBufferSize()方法时触发。这两个方法都会将目前占用的缓冲区大小与用户配置的大小做比较,如果超出限制则会调用flushCommits()方法。如果缓冲区被禁用,可以设置setAutoFlushTo(true),这样用户每次调用put方法是都会触发刷写。
批量插入示例代码
/** * 批量添加100000条数据,每2000条一刷写 */@Testpublic void testBatchPut() throws IOException { Connection conn = ConnectionFactory.createConnection(); HTable table = (HTable) conn.getTable(TableName.valueOf("ns1:t1")); table.setAutoFlushTo(false); for (int i = 0; i < 100000; i++) { Put put = new Put(Bytes.toBytes("row" + i)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("id"), Bytes.toBytes(i)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"), Bytes.toBytes("tom" + i)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes(i % 100)); table.put(put); if (i % 2000 == 0){ table.flushCommits(); } } table.flushCommits(); table.close(); conn.close();}Put列表
客户端可以将一个Put实例的集合进行插入操作,实现代码如下:
/** * 批量插入1000条数据 */@Testpublic void testBatchPut2() throws IOException { Connection conn = ConnectionFactory.createConnection(); HTable table = (HTable) conn.getTable(TableName.valueOf("ns1:t1")); List<Put> puts = new ArrayList<Put>(); for (int i = 0; i < 1000; i++) { Put put = new Put(Bytes.toBytes("r" + i)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("id"), Bytes.toBytes(i)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"), Bytes.toBytes("tom" + i)); put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes(i % 100)); puts.add(put); } table.put(puts); table.close(); conn.close();}原子性操作compare-and-set
有一个特别的普通调用,其能保证自身操作的原子性,检查和写(check and put)方法如下:
public boolean checkAndPut(final byte [] row, final byte [] family, final byte [] qualifier, final byte [] value, final Put put)public boolean checkAndPut(final byte [] row, final byte [] family, final byte [] qualifier, final CompareOp compareOp, final byte [] value, final Put put)测试代码如下
Put put1 = new Put(Bytes.toBytes("row1"));put1.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"));boolean res1 = table.checkAndPut(Bytes.toBytes("row1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"), null, put1);System.out.println("Put applied: " + res1);table.put(put1);boolean res2 = table.checkAndPut(Bytes.toBytes("row1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"), null, put1);System.out.println("Put applied: " + res2);Put put2 = new Put(Bytes.toBytes("row2"));put2.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual2"), Bytes.toBytes("val2"));boolean res3 = table.checkAndPut(Bytes.toBytes("row1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"), null, put2);System.out.println("Put applied: " + res3);table.put(put2);Put put3 = new Put(Bytes.toBytes("row3"));put3.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual3"), Bytes.toBytes("val3"));boolean res4 = table.checkAndPut(Bytes.toBytes("row1"), Bytes.toBytes("qual1"), Bytes.toBytes("val1"), null, put3);System.out.println("Put applied: " + res4);- HBase CURD之Put
- HBase CURD之Get
- HBase CURD之Delete
- HBase分析之Put操作
- hbase源码学习之put操作
- HBase之HRegionServer处理put请求
- Java操作hbase CURD
- Hbase javaapi curd笔记
- HBase基础知识(1):CRUD操作之put方法
- hbase HTable之Put、delete、get等源码分析
- hbase-1.2.1之put操作源码学习
- HBase API Put
- HBASE PUT讲解
- hbase中Put源码分析
- hbase put regionserver处理分析
- HBase table Put 插入数据
- HBase使用Put插入数据
- HBase - 正确的Put方法
- 对javaBean简单的内省操作
- 学习笔记(逆向汇编)Day6-Day10
- Hibernate之对象的状态
- 2018搜狐内推笔试编程题2
- 分布式系统事务一致性解决方案
- HBase CURD之Put
- 面试常见问题
- SDOI 2013 直径
- C++ 同名隐藏和赋值兼容规则
- 基于Webkit的浏览器关键渲染路径介绍
- Android ADB常用命令有哪些?
- PAT乙级1042. 字符统计(20)
- activity跳转黑屏但不透明桌面问题
- 游戏物理数学之《四元数Quaternion》


