Redis笔记——技术点汇总
来源:互联网 发布:java实现iis域认证 编辑:程序博客网 时间:2024/06/11 03:12
目录
· 特点
· 安装
· 数据库
· 服务器命令
· 数据类型及其操作命令
· 数据结构
· string
· list
· set
· hash
· zset
· 发布与订阅
· 排序
· 事务
· pipeline
· 基准测试
· 键的过期
· 持久化
· 概况
· snapshoting
· AOF
· 主从复制
· HA
· Lua
· 示例:分布式日志
特点
1. Redis是一个开源的、C语言编写的、面向键值对类型数据的分布式NoSQL数据库系统。
2. 特点:高性能(内存数据库,随机读写非常快)、持久存储,适应高并发应用场景。
3. 对比:一些数据库和缓存服务器的特性与功能。
名称
类型
数据存储
查询类型
附加功能
Redis
使用内存存储(in-memory)的非关系数据库
字符串、列表、集合、散列、有序集合
每种数据类型都有自己的专属命令,另外还有批量操作(buld operation)和不完全(partial)事务支持
发布与订阅,主从复制(master/slave replication),持久化,脚本
memcached
使用内存存储的键值缓存
键值之间的映射
创建命令、读取命令、更新命令、删除命令以及其他几个命令
为提升性能而设的多线程服务器
MySQL
关系数据库
每个数据库可以包含多个表,每个表可以包含多个行;可以处理多个表的视图;支持空间和第三方扩展
SELECT、INSERT、UPDATE、DELETE、函数、存储过程
支持ACID(InnoDB),主从复制和主主复制
PostgreSQL
关系数据库
每个数据库可以包含多个表,每个表可以包含多个行;可以处理多个表的视图;支持空间(spatial)和第三方扩展;支持定制类型
SELECT、INSERT、UPDATE、DELETE、函数、存储过程
支持ACID(InnoDB),主从复制,由第三方支持的多主复制
MongoDB
使用硬盘存储(on-disk)的非关系数据库
每个数据库可以包含多个表,每个表可以包含多个无schema(schema-less)的BSON文档
创建命令、读取命令、更新命令、删除命令、条件查询命令等
支持map-reduce操作,主从复制,分片,空间索引(spatial index)
4. 性能测试结果:set操作每秒可达110000次,get操作每秒81000次(与服务器配置有关)。
安装
1. 安装。
tar zxvf redis-3.2.0.tar.gzcd redis-3.2.0.tar.gzyum install gcc # 安装依赖cd depsmake hiredis lua jemalloc linenoise geohash-intcd ..make # 编译
2. 配置。
vi redis.conf# bind 127.0.0.1 # 不绑定表示监听所有IPprotected-mode no # 无密码daemonize yes # 后台运行logfile "/opt/app/redis-3.2.0/logs/redis.log" # 日志文件路径dir "/opt/app/redis-3.2.0/data/" # 快照文件路径appendonly yes # 开启AOF
3. 启动、关闭。
src/redis-server redis.conf # 启动src/redis-cli # 客户端src/redis-cli shutdown # 关闭
数据库
1. Redis默认有16个数据库。
2. 数据库个数配置项:databases。
3. 切换数据库命令:
127.0.0.1:6379> select 0OK127.0.0.1:6379> select 15OK127.0.0.1:6379[15]>
服务器命令
命令
说明
dbsize
获取当前数据库中键的个数
info
获取服务器信息
select
切换数据库
config get
config get config-key,获取配置项config-key的值
数据类型及其操作命令
数据结构
1. 存储键与5种不同数据结构类型之间的映射。
2. 键是string类型。
3. 5种数据类型:string、list、set、hash、zset。
4. 命令:部分命令(如del、type、rename)对于5种类型通用;部分命令只能对特定的一种或者两种类型使用。另注:有很多命令尾部带“nx”表示不存在键时才执行。
5. 常用通用命令。
命令
说明
keys
keys pattern,获取满足pattern的所有键,支持通配符星号“*”
exists
exists key,判断键key是否存在
del
del key,删除键key
expire
设置键的过期时间(后面详细介绍)
move
move key database,将键key移动到数据库database
rename
rename old-key new-key,将键old-key重命名为new-key
type
type key,获取键的数据结构
string
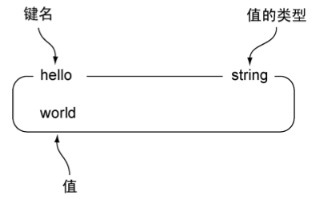
1. 可以是字符串、整数或浮点数。
2. Redis的字符串是由字节组成的序列。
3. 对于整数、浮点数的字符串可执行自增和自减;对无法解释成整数或浮点数的字符串执行自增或自减会返回错误。
4. 常用命令。
命令
说明
get
获取给定键的值
set
设置给定键的值
incr
incr key-name,将键存储的值加上1
decr
decr key-name,将键存储的值减去1
incrby
incrby key-name amount,将键存储的值加上整数amont
decrby
decrby key-name amount,将键存储的值减去整数amont
incrbyfloat
incrbyfloat key-name amount,将键存储的值加上浮点数amont
append
append key-name value,将值value追加到给定键key-name当前存储的值的末尾
getrange
getrange key-name start end,获取一个偏移量start至偏移量end范围内所有字符组成的子串,包括start和end在内
setrange
setrange key-name offset value,将从start偏移量开始的子串设置为给定值
getbit
getbit key-name offset value,将字节串看作是二进制位串(bit string),并返回位串中偏移量为offset的二进制位的值
setbit
setbit key-name offset value,将字节串看作是二进制位串,并将位串中偏移量为offset的二进制位的值设置为value
bitcount
bitcount key-name [start end],统计二进制位串里面值为1的二进制位的数量,如果给定了可选的start偏移量和end偏移量,那么只对偏移量指定范围内二进制位进行统计
bitop
bitop operation dest-key key-name [key-name ...],对一个或多个二进制位串执行包括并and、或or、异或xor、非not在内的任意一种按位运算,并将计算结果保存在dest-key键里面
5. 举例。
127.0.0.1:6379> set hello worldOK127.0.0.1:6379> get hello"world"127.0.0.1:6379> del hello(integer) 1127.0.0.1:6379> get hello(nil)127.0.0.1:6379> set num 100OK127.0.0.1:6379> incrby num 10(integer) 110127.0.0.1:6379> append num abc(integer) 6127.0.0.1:6379> get num"110abc"127.0.0.1:6379> getrange num 2 4"0ab"
list
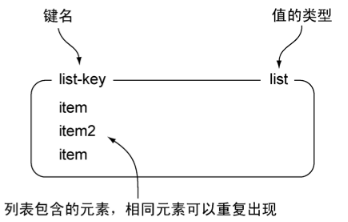
1. Redis的list是链表(linked-list)。
2. 应用:列表、栈、队列、消息队列MQ等。
3. 命令。
命令
说明
rpush
rpush key-name value [value ...],将一个或多个值推入列表的右端
lpush
lpush key-name value [value ...],将一个或多个值推入列表的左端
rpop
rpop key-name,移除并返回列表最右端的元素
lpop
lpop key-name,移除并返回列表最左端的元素
lindex
lindex key-name offset,返回列表中偏移量为offset的元素
lrange
lrange key-name start end,返回列表从start偏移量到end偏移量范围内的所有元素,其中偏移量为start和偏移量为end的元素也会包含在内
ltrim
ltrim key-name start end,对列表进行修剪,只保留从start偏移量到end偏移量范围内的元素,其中偏移量为start和偏移量为end的元素也会被保留
blpop
blpop key-name [key-name…] timeout,从第一个非空列表中弹出位于最左端的元素,或者在timeout秒之内阻塞并等待可弹出的元素出现
brpop
brpop key-name [key-name…] timeout,从第一个非空列表中弹出位于最右端的元素,或者在timeout秒之内阻塞并等待可弹出的元素出现
rpoplpush
rpoplpush source-key dest-key,从source-key列表中弹出位于最右端的元素,然后将这个元素推入dest-key列表的最左端,并向用户返回这个元素
brpoplpush
brpoplpush source-key dest-key timeout,从source-key列表中弹出位于最右端的元素,然后将这个元素推入dest-key列表的最左端,并向用户返回这个元素;如果source-key为空,那么在timeout秒之内阻塞并等待可弹出的元素出现
4. 举例。
127.0.0.1:6379> rpush list-key item1(integer) 1127.0.0.1:6379> rpush list-key item2 item1(integer) 3127.0.0.1:6379> lpush list-key item0(integer) 4127.0.0.1:6379> lrange list-key 0 -11) "item0"2) "item1"3) "item2"4) "item1"127.0.0.1:6379> lindex list-key 3"item1"127.0.0.1:6379> lpop list-key"item0"127.0.0.1:6379> ltrim list-key 0 1OK127.0.0.1:6379> lrange list-key 0 -11) "item1"2) "item2"
set
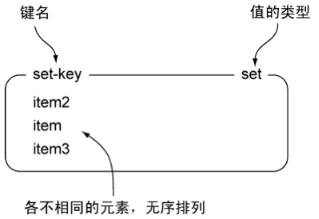
1. list允许有重复值,set不允许有重复值。
2. list是有序的,set是无序的。
3. set通过hash保证值不重复(这些hash表只有键,没有与键对应的值)。
4. 应用:去重列表、集合运算(交、并、差集)。
5. 命令。
命令
说明
sadd
sadd key-name item [item...],将一个或多个元素添加到集合里面,并返回被添加元素当中原本并不存在于集合里面的元素数量
srem
srem key-name item [item...],从集合里面移除一个或多个元素,并返回被移除元素的数量
sismember
sismember key-name item,检查元素item是否存在于集合key-name里
scard
scard key-anem,返回集合包含的元素数量
smembers
smembers key-name,返回集合包含的所有元素
srandmember
srandmember key-name [count],从集合里面随机地返回一个或多个元素。当count为正数时,命令返回的随机元素不会重复;当count为负数时,命令返回的随机元素可能会出现重复
spop
spop key-name,随机地移除集合中一个元素,并返回移除的元素
smove
smove source-key dest-key item,如果集合source-key包含元素item,那么从集合source-key里面移除元素item,并将元素item添加到集合dest-key中;如果item被成功移除,那么命令返回1,否则返回0
sdiff
sdiff key-name [key-name…],返回那些存在于第一个集合但不存在于其他集合中的元素(数学上的差集运算)
sdiffstore
sdiffstore dest-key key-name [key-name…],将那些存在于第一个集合但不存在于其他集合中的元素(数学上的差集运算)存储到dest-key键里面
sinter
sinter key-name [key-name…],返回那些同时存在于所有集合的元素(数学上的交集运算)
sinterstore
sinterstore dest-key key-name [key-name…],将那些同时存在于所有集合的元素(数学上的交集运算)存储到dest-key键里面
sunion
sunion key-name [key-name…],返回那些至少存在于一个集合中的元素(数学上的并集运算)
sunionstore
sunionstore dest-key key-name [key-name…],将那些至少存在于一个集合中的元素(数学上的并集运算)存储到dest-key键里面
6. 举例。
127.0.0.1:6379> sadd set-key item0(integer) 1127.0.0.1:6379> sadd set-key item1 item2(integer) 2127.0.0.1:6379> sadd set-key item0(integer) 0127.0.0.1:6379> smembers set-key1) "item2"2) "item1"3) "item0"127.0.0.1:6379> sismember set-key item3(integer) 0127.0.0.1:6379> sismember set-key item0(integer) 1127.0.0.1:6379> srem set-key item2(integer) 1127.0.0.1:6379> srem set-key item2(integer) 0127.0.0.1:6379> smembers set-key1) "item1"2) "item0"
hash
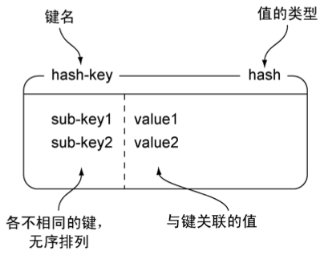
1. Redis的散列可以存储多个键值对之间的映射,在很多方面就像是一个微缩版的Redis。
2. 命令。
命令
说明
hset
在散列里面关联起给定的键值对
hget
获取指定散列键的值
hmget
hmget key-name key [key...],从散列里面获取一个或多个键的值
hmset
hmget key-name key value [key value...],为散列里面的一个或多个键设置值
hgetall
获取散列包含的所有键值对
hdel
如果给定键存在于散列里面,那么移除这个键
hlen
hlen key-name,返回散列包含的键值对数量
hexists
hexists key-name key,检查给定键是否存在于散列中
hkeys
hkeys key-name,获取散列包含的所有键
hvals
hvals key-name,获取散列包含的所有值
hincrby
hincrby key-name key increment,将键key保存的值加上整数increment
hincrbyfloat
hincrbyfloat key-name key increment,将键key保存的值加上浮点数increment
3. 举例。
127.0.0.1:6379> hset hash-key sub-key0 value0(integer) 1127.0.0.1:6379> hset hash-key sub-key1 value1(integer) 1127.0.0.1:6379> hmset hash-key sub-key2 value2 sub-key3 value3OK127.0.0.1:6379> hset hash-key sub-key0 value0(integer) 0127.0.0.1:6379> hgetall hash-key1) "sub-key0"2) "value0"3) "sub-key1"4) "value1"5) "sub-key2"6) "value2"7) "sub-key3"8) "value3"127.0.0.1:6379> hdel hash-key sub-key3(integer) 1127.0.0.1:6379> hmget hash-key sub-key0 sub-key11) "value0"2) "value1"127.0.0.1:6379> hget hash-key sub-key2"value2"127.0.0.1:6379> hkeys hash-key1) "sub-key0"2) "sub-key1"3) "sub-key2"127.0.0.1:6379> hvals hash-key1) "value0"2) "value1"3) "value2"
4. 应用:可以把hash看作关系数据库的行,hash中的key为字段名,hash中的value为字段值。以用户为例,新增/查询ID为1和2的两个用户:
127.0.0.1:6379> hmset user:1 name zhangsan age 18OK127.0.0.1:6379> hmset user:2 name lisi age 19OK127.0.0.1:6379> hgetall user:11) "name"2) "zhangsan"3) "age"4) "18"127.0.0.1:6379> hgetall user:21) "name"2) "lisi"3) "age"4) "19"
zset
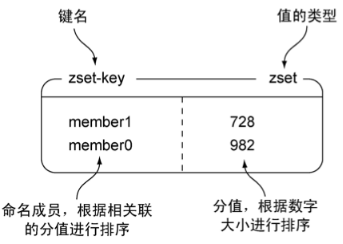
1. zset和hash一样,都用于存储键值对。
2. zset的键称为成员(member),不允许重复。
3. zset的值称为分值(score),必须是浮点数。
4. zset既可以根据member访问元素(与hash相同),也可以根据分值及分值的排序顺序来访问元素。
5. 应用:排序、去重。
6. 命令。
命令
说明
zadd
zadd key-name score member [score member...],将带有给定分值的成员添加到有序集合里面
zrem
zrem key-name member [member...],从有序集合里面移除给定的成员,并返回被移除成员的数量
zcard
zcard key-name,返回有序集合包含的成员数量
zincrby
zincrby key-name increment member,将member成员的分值加上increment
zcount
zcount key-name min max,返回分值介于min和max之间的成员数量
zrank
zrank key-name member,返回成员member在key-name中的排名
zscore
zscore key-name member,返回成员member的分值
zrange
zrange key-name start stop [withscores],返回有序集合中排名介于start和stop之间的成员,如果给定了可选的withscores选项,那么命令会将成员的分值也一并返回
zrevrank
zrevrank key-name member,返回有序集合里成员member所处的位置,成员按照分值从大到小排列
zrevrange
zrevrange key-name start stop [withscores],返回有序集合给定排名范围内的成员,成员按照分值从大到小排列
zrangebyscore
zrangebyscore key min max [withscores] [limit offset count],返回有序集合中,分值介于min和max之间的所有成员
zrevrangebyscore
zrevrangebyscore key max min [withscores] [limit offset count],获取有序集合中分值介于min和max之间的所有成员,并按照分值从大到小的顺序来返回它们
zremrangebyrank
zremrangebyrank key-name start stop,移除有序集合中排名介于start和stop之间的所有成员
zremrangebyscore
zremrangebyscore key-name min max,移除有序集合中分值介于min和max之间的所有成员
zinterstore
zinterstore dest-key key-count key [key...] [weights weight [weight...]] [aggregate sum|min|max],对给定的有序集合执行类似于集合的交集运算
zunionstore
zunionstore dest-key key-count key [key...] [weights weight [weight...]] [aggregate sum|min|max],对给定的有序集合执行类似于集合的并集运算
7. 举例。
127.0.0.1:6379> zadd zset-key 200 member1(integer) 1127.0.0.1:6379> zadd zset-key 300 member0 400 member2(integer) 2127.0.0.1:6379> zadd zset-key 100 member1(integer) 0127.0.0.1:6379> zcard zset-key(integer) 3127.0.0.1:6379> zcount zset-key 100 350(integer) 2127.0.0.1:6379> zrank zset-key member1(integer) 0127.0.0.1:6379> zrank zset-key member1(integer) 0127.0.0.1:6379> zscore zset-key member1"100"127.0.0.1:6379> zrange zset-key 1 21) "member0"2) "member2"127.0.0.1:6379> zrevrank zset-key member1(integer) 2127.0.0.1:6379> zrevrange zset-key 1 21) "member0"2) "member1"127.0.0.1:6379> zrangebyscore zset-key 100 3501) "member1"2) "member0"127.0.0.1:6379> zrevrangebyscore zset-key 100 350(empty list or set)127.0.0.1:6379> zrevrangebyscore zset-key 350 1001) "member0"2) "member1"
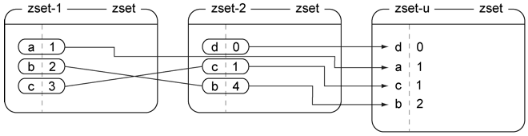
8. zinterstore交集举例。

9. zunionstore并集举例。
发布与订阅
1. 发布与订阅(pub/sub)的特点是订阅者(listener)负责订阅频道(channel),发送者(publisher)负责向频道发送二进制字符串消息(binary string message)。
2. 当有消息被发送至给定频道时,频道的所有订阅者都会收到消息。
3. 备注:将list作为队列,同时使用阻塞命令同样可以实现发布/订阅,具体代码参见“示例:分布式日志”。
4. 命令。
命令
说明
subscribe
subscribe channel [channel...],订阅给定的一个或多个频道
unsubscribe
unsubscribe [channel [channel...]],退订给定的一个或多个频道,如果执行时没有给定任何频道,那么退订所有频道
psubscribe
psubscribe pattern [pattern...],订阅与给定模式相匹配的所有频道
punsubscribe
punsubscribe [pattern [pattern...]],退订给定的模式,如果执行时没有给定任何模式,那么退订所有模式
publish
publish channel message,向给定频道发送消息
5. 举例。
127.0.0.1:6379> subscribe channel0 channel1Reading messages... (press Ctrl-C to quit)1) "subscribe"2) "channel0"3) (integer) 11) "subscribe"2) "channel1"3) (integer) 21) "message"2) "channel0"3) "hello"1) "message"2) "channel1"3) "world"
127.0.0.1:6379> publish channel0 hello(integer) 1127.0.0.1:6379> publish channel1 world(integer) 1
6. 订阅者读取速度。
a) 问题:如果订阅者读取消息速度不够快,那么不断积压的消息会使Redis输出缓冲区的体积越来越大,可能会导致Redis速度变慢,甚至崩溃。
b) 解决:自动断开不符合client-output-buffer-limit pubsub配置选项的订阅客户端。
7. 数据传输可靠性。
a) 问题:网络连接错误会使网络连接两端中的其中一端重新连接,导致客户端丢失在短线期间的所有消息。
b) 解决:TODO 第六章两个不同方法。
排序
1. 对list、set、zset排序。
2. 命令。
命令
说明
sort
sort source-key [by pattern] [limit offset count] [get pattern [get pattern...]] [asc|desc] [alpha] [store dest-key],根据给定的选项,对输入列表、集合或者有序集合进行排序,然后返回或者存储排序的结果
3. 举例。
127.0.0.1:6379> rpush sort-key v1 v0 v3 v4 v2(integer) 5127.0.0.1:6379> sort sort-key alpha1) "v0"2) "v1"3) "v2"4) "v3"5) "v4"127.0.0.1:6379> sort sort-key alpha desc1) "v4"2) "v3"3) "v2"4) "v1"5) "v0"
事务
1. Redis的基本事务(basic transaction)可以让一个客户端在不被其他客户端打断的情况下执行多个命令。
2. 与关系数据库不同,Redis的基本事务在执行完事务内所有命令后,才会处理其他客户端的命令。
3. 命令。
命令
说明
multi
标记一个事务开始。
exec
执行所有multi之后的命令
discard
丢弃所有multi之后的命令
watch
对指定键监视,直到执行exec命令结束。如果期间其他客户端对被监视的键执行写入命令,那么当前客户端执行exec命令时将报错。相当于乐观锁。
unwatch
取消监视。如果执行exec或discard命令,则无需再执行unwatch命令。
4. 举例。
127.0.0.1:6379> multiOK127.0.0.1:6379> set k0 v0QUEUED127.0.0.1:6379> set k1 v1QUEUED127.0.0.1:6379> exec1) OK2) OK
127.0.0.1:6379> watch k0 k1OK127.0.0.1:6379> multiOK127.0.0.1:6379> set k0 v0xQUEUED127.0.0.1:6379> set k1 v1xQUEUED127.0.0.1:6379> exec
5. Redis事务内有部分命令失败时,整个事务不会自动discard,导致事务内可能部分命令成功,部分失败。举例:
127.0.0.1:6379> set str-key haloOK127.0.0.1:6379> set num-key 100OK127.0.0.1:6379> multiOK127.0.0.1:6379> incr str-keyQUEUED127.0.0.1:6379> incr num-keyQUEUED127.0.0.1:6379> exec1) (error) ERR value is not an integer or out of range2) (integer) 101127.0.0.1:6379> get str-key"halo"127.0.0.1:6379> get num-key"101"
pipeline
1. 应用程序连接Redis执行事务及事务中所有命令(5个)时,一定要使用pipeline。
2. 由于pipeline会一次发送所有命令,可减少通信次数并降低延迟,在非事务时也推荐使用。
基准测试
1. Redis附带基准测试程序redis-benchmark。
2. 举例:模拟单个客户端。
src/redis-benchmark -c 1 -qPING_INLINE: 77399.38 requests per secondPING_BULK: 81566.07 requests per secondSET: 58513.75 requests per secondGET: 80840.74 requests per secondINCR: 57208.24 requests per secondLPUSH: 54229.93 requests per secondRPUSH: 55555.56 requests per secondLPOP: 55401.66 requests per secondRPOP: 57937.43 requests per secondSADD: 77459.34 requests per secondSPOP: 79113.92 requests per secondLPUSH (needed to benchmark LRANGE): 54495.91 requests per secondLRANGE_100 (first 100 elements): 37271.71 requests per secondLRANGE_300 (first 300 elements): 16537.13 requests per secondLRANGE_500 (first 450 elements): 11799.41 requests per secondLRANGE_600 (first 600 elements): 9273.00 requests per secondMSET (10 keys): 31735.96 requests per second
3. 应用程序在使用pipeline和连接池的情况下,基本与上面模拟的测试性能一致。
键的过期
1. 设置键的过期时间,让键在在给定的时限后自动被删除(相当于执行del命令)。
2. 只能设置整个键的过期时间(支持5中数据结构),无法设置list、set、hash和zset中单个元素的过期时间。
3. 命令。
命令
说明
persist
persist key-name,移除键的过期时间
ttl
ttl key-name,返回给定键距离过期还有多少秒
expire
expire key-name seconds,让键key-name在给定的seconds秒之后过期
expireat
expireat key-name timestamp,将给定键的过期时间设置为给定的UNIX时间戳
pttl
pttl key-name,返回给定键距离过期时间还有多少毫秒,这个命令在Redis 2.6或以上版本可用
pexpire
pexpire key-name milliseconds,让键key-name在milliseconds毫秒之后过期
pexpireat
pexpireat key-name timestamp-milliseconds,将一个毫秒级精度的UNIX时间戳设置为给定键的过期时间
4. 举例。
127.0.0.1:6379> set expire-key vOK127.0.0.1:6379> ttl expire-key(integer) -1127.0.0.1:6379> expire expire-key 10(integer) 1127.0.0.1:6379> ttl expire-key(integer) 7127.0.0.1:6379> get expire-key(nil)
持久化
概况
1. 两种持久化方式:
a) snapshoting(快照):将某一时刻内存中所有数据写入硬盘;
b) AOF(append-only file):执行写入命令时,将命令追加到硬盘文件。
2. 两种持久化方式可同时使用,也可单独使用,某些情况下也可以两种都不使用。
3. 配置。
save 60 1000 # snapshoting配置stop-writes-on-bgsave-error nordbcompression yesrdbchecksum yesdbfilename dump.rdb
appendonly no # AOF配置appendfilename "appendonly.aof"appendfsync everysecno-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yes
dir ./ # 共用配置snapshoting
1. 创建snapshoting的方法/时机。
a) 执行bgsave命令。Redis会调用fork创建一个子进程,子进程负责将快照写入硬盘,父进程继续处理命令请求。
b) 执行save命令。Redis在创建快照完成之前不再响应任何其他命令。不常用,通常只会在内存不足时使用。
c) 设置save配置。“save 60 100000”表示当满足“60秒之内有10000次写入”条件时,自动触发bgsave命令。如果有多个save配置,那么任意一个条件满足时都会触发。
d) 执行shutdown命令或收到标准term信号时,会先触发save命令(不再响应任何客户端请求)。
e) 一个Redis服务器连接另一个Redis服务器,并向对方发送sync命令开始一次复制时,如果主服务器目前没有执行bgsave命令,或主服务器并非刚刚执行完bgsave命令,那么主服务器会执行gbsave命令。
2. snapshoting注意:如果系统真的发生崩溃,将丢失最近一次生成快照后更新的所有数据。
3. snapshoting与大数据:如果Redis内存占用高达几十GB,并且空闲内存不多,或者硬件性能较差时,执行bgsave命令可能会导致长时间停顿(几秒,甚至几十分钟),也可能引发系统大量使用虚拟内存,从而导致Redis性能降低至无法使用。
AOF
1. appendfsync同步频率。
a) always。每个写命令都同步写入硬盘。严重降低Redis性能。降低固态硬盘SSD寿命。
b) everysec。每秒同步一次,将多个写命令同步到硬盘。兼顾数据安全和写入性能。
c) no。让操作系统决定何时同步。一般不影响性能,但崩溃将导致不定数量的数据丢失。不推荐。
2. 重写AOF文件:移除AOF文件中的冗余命令,压缩AOF文件体积。
3. 重写AOF文件解决的问题。
a) 随着Redis不断运行,AOF文件不断增大,极端时甚至用完硬盘空间。
b) Redis重启后需要重新执行AOF文件中的写命令还原数据,如果AOF文件非常大,那么还原时间可能会非常长。
4. 重写AOF文件的方法/时机。
a) 执行bgrewriteaof命令。与bgsave命令相似,Redis会创建一个子进程负责AOF文件重写,也存在影响性能的问题。
b) 设置auto-aof-rewrite-percentage和auto-aof-rewrite-min-size配置。“auto-aof-rewrite-percentage 100”和“auto-aof-rewrite-min-size 64mb”表示当AOF文件大于64MB且AOF文件比上次重写后至少大一倍(100%)时,触发bgrewriteaof命令。
主从复制
1. 解决:虽然Redis性能优秀,但也会有无法快速处理请求的情况。伸缩(scalability)。
2. 客户端效果:客户端每次向主服务器执行写入命令时,从服务器都会实时更新,客户端就可以向任意一个服务器执行读取命令。
3. 配置:
a) 主服务器设置dir和dbfilename配置。保证从服务器连接主服务器时,主服务器能执行bgsave操作。
b) 从服务器设置slaveof host port配置,或执行slaveof host port命令。让从服务器复制主服务器。slaveof no one命令可终止复制。
4. 从服务器连接主服务器的过程。
步骤
主服务器
从服务器
1
(等待命令进入)
连接(或重连)主服务器,发送sync命令
2
开始执行bgsave命令,并使用缓冲区记录bgsave之后执行的所有写命令
根据配置决定继续使用现有数据(如果有)来处理客户端请求,还是向发送请求的客户端返回错误
3
bgsave执行完毕,向从服务器发送快照文件,并在发送期间继续使用缓冲区记录被执行的写命令
丢弃所有旧数据(如果有),开始载入主服务器发来的快照文件
4
快照文件发送完毕,开始向从服务器发送缓冲区中的写命令
完成对快照文件的解释操作,像往常一样开始接收请求
5
缓冲区的写命令发送完毕,从此,每执行一个写命令,就向从服务器发送相同的写命令
执行主服务器发送来的缓冲区中的写命令,从此,接收并执行主服务器传来的每个写命令
5. 优化:实际中最好让主服务器只使用50%~65%的内存,剩余30%~45%内存用于执行bgsave命令和创建记录写命令的缓冲区。
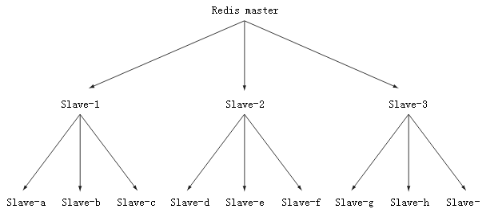
6. 主从链:从服务器也可以拥有自己的从服务器,由此形成主从链(master/slave chaning)。
7. 主从链解决问题。
a) 读请求远多于写请求。
b) 负荷上升,主服务器无法快速更新所有从服务器。
8. 主从链结构:不一定是树状结构。
9. 更换故障主服务器步骤:
a) 从服务器执行save命令,生成最新快照文件;
b) 将快照文件复制到新主服务器;
c) 配置并启动新主服务器;
d) 从服务器连接新主服务器。
HA
1. Redis-Sentinel是Redis的Master-Slave高可用方案。
2. Master宕机时,自动完成主备切换。
3. 资料:http://redis.cn/topics/sentinel.html。
Lua
1. Redis中的Lua类似关系数据库中的存储过程,可封装逻辑。
2. Lua脚本跟单个Redis命令以及“multi/exec”事务一样,都是原子操作,因此可替代事务。
3. 命令。
命令
说明
eval
eval script numkeys key [key...] arg [arg...],执行脚本script,numkeys表示要使用的键个数,key表示键,arg表示参数。脚本内部通过KEYS数组获取键,如KEYS[1]获取第1个键;通过ARGV数组获取参数,如ARGV[1]获取第1个参数
evalsha
evalsha sha1 numkeys key [key...] arg [arg...],根据SHA1校验码执行脚本
script load
script load script,加载脚本script,返回SHA1校验码
script exists
script exists sha1,根据SHA1校验码判断脚本是否已加载
script flush
清除全部脚本
script kill
停止当前正在执行的脚本
4. 举例(第3个证明脚本中Redis命令执行失败时不会discard已执行过的命令,即“事务”提到的第5点)。
$ redis-cli eval "return 'Hello World'" 0"Hello World"
$ redis-cli eval "return {KEYS[1], KEYS[2], ARGV[1], ARGV[2]}" 2 key1 key2 arg1 arg21) "key1"2) "key2"3) "arg1"4) "arg2"
$ vi test.lualocal ret = redis.call("set", KEYS[1], ARGV[1])if redis.call("exists", KEYS[2]) == 1 then redis.call("incr", KEYS[2])else redis.call("set", KEYS[2], ARGV[2])endreturn ret$ redis-cli script load "$(cat test.lua)""07aa590946287d9ae0c3df41dd9ba06a64280d85"$ redis-cli evalsha 07aa590946287d9ae0c3df41dd9ba06a64280d85 2 mykey1 mykey2 myarg1 myarg2OK$ redis-cli evalsha 07aa590946287d9ae0c3df41dd9ba06a64280d85 2 mykey1 mykey2 myarg1111111 myarg2(error) ERR Error running script (call to f_07aa590946287d9ae0c3df41dd9ba06a64280d85): @user_script:3: ERR value is not an integer or out of range$ redis-cli get mykey1"myarg1111111"$ redis-cli get mykey2"myarg2"
示例:分布式日志
1. 生产者-消费者模式。
2. 多台机器将日志保存到Redis队列,一个线程从该队列取出日志并保存到日志文件。个数比:生产者:消费者=N:1。
3. 代码(使用Jedis API):
1 import static gz.redis.DistributedLog.HOST; 2 import static gz.redis.DistributedLog.LOG_QUEUE_KEY; 3 import static gz.redis.DistributedLog.PORT; 4 import static gz.redis.DistributedLog.connection; 5 6 import java.io.BufferedWriter; 7 import java.io.FileWriter; 8 import java.io.IOException; 9 import java.util.Date; 10 import java.util.List; 11 import java.util.UUID; 12 import java.util.concurrent.ExecutorService; 13 import java.util.concurrent.Executors; 14 15 import redis.clients.jedis.Jedis; 16 import redis.clients.jedis.JedisPool; 17 import redis.clients.jedis.JedisPoolConfig; 18 19 public class DistributedLog { 20 21 static final String HOST = "centos1"; 22 23 static final int PORT = 6379; 24 25 private static JedisPool jedisPool; 26 27 static final String LOG_QUEUE_KEY = "log-queue"; 28 29 public static void main(String[] args) { 30 initConnectionPoll(); 31 32 ExecutorService threadPool = Executors.newFixedThreadPool(50); 33 for (int index = 0; index < 500000; index++) { 34 threadPool.execute(new Writer()); 35 } 36 new Thread(new Processor()).run(); 37 threadPool.shutdown(); 38 } 39 40 private static void initConnectionPoll() { 41 if (jedisPool == null) { 42 JedisPoolConfig config = new JedisPoolConfig(); 43 config.setMaxTotal(51); 44 config.setMinIdle(51); 45 config.setMaxIdle(51); 46 config.setMaxWaitMillis(60 * 1000); 47 config.setTestOnCreate(true); 48 config.setTestOnReturn(true); 49 config.setTestOnBorrow(true); 50 config.setTestWhileIdle(true); 51 jedisPool = new JedisPool(config, HOST, PORT); 52 } 53 } 54 55 static Jedis connection() { 56 return jedisPool.getResource(); 57 } 58 59 } 60 61 class Writer implements Runnable { 62 63 @Override 64 public void run() { 65 String log = new Date() + " - " + UUID.randomUUID() + "\n"; 66 Jedis jedis = null; 67 try { 68 jedis = connection(); 69 // 队尾追加 70 jedis.rpush(LOG_QUEUE_KEY, log); 71 } finally { 72 if (jedis != null) { 73 jedis.close(); 74 } 75 } 76 } 77 78 } 79 80 class Processor implements Runnable { 81 82 @Override 83 public void run() { 84 BufferedWriter writer = null; 85 Jedis jedis = null; 86 try { 87 writer = new BufferedWriter(new FileWriter("D:/movie/MyTest.log")); 88 jedis = new Jedis(HOST, PORT); 89 int count = 0; 90 while (true) { 91 // 队头取出,无限时间阻塞,直至取出 92 List<String> logs = jedis.blpop(0, LOG_QUEUE_KEY); 93 if (logs != null && logs.size() >= 2) { 94 writer.write(logs.get(1)); 95 if (++count > 100) { 96 writer.flush(); 97 } 98 } 99 }100 } catch (IOException e) {101 e.printStackTrace();102 } finally {103 if (jedis != null) {104 jedis.close();105 }106 if (writer != null) {107 try {108 writer.close();109 } catch (IOException e) {110 e.printStackTrace();111 }112 }113 }114 }115 116 }
作者:netoxi
出处:http://www.cnblogs.com/netoxi
本文版权归作者和博客园共有,欢迎转载,未经同意须保留此段声明,且在文章页面明显位置给出原文连接。欢迎指正与交流。
- Redis笔记——技术点汇总
- Spark笔记——技术点汇总
- Storm笔记——技术点汇总
- JVM笔记——技术点汇总
- JVM笔记——技术点汇总
- Netty笔记——技术点汇总
- ActiveMQ笔记——技术点汇总
- ActiveMQ笔记——技术点汇总
- Spark SQL笔记——技术点汇总
- Spark Streaming笔记——技术点汇总
- Spark Streaming笔记——技术点汇总
- Spark SQL笔记——技术点汇总
- 技术点汇总
- 网站技术点汇总
- redis技术点
- 常见项目技术点汇总
- android 小技术点汇总
- android学习技术点汇总
- java.io.IOException: Expected at least 2 bytes
- hadoop安装,并配置单节点hadoop集群
- 4.S5PV210看门狗定时器相关寄存器描述
- Hadoop 及 Hive 压缩应用
- ArrayList源码解析
- Redis笔记——技术点汇总
- hdu 2473
- 判断当前所使用python的版本和来源
- Akka(22): Stream:实时操控:动态管道连接-MergeHub,BroadcastHub and PartitionHub
- 利用ida python 实现复原函数调用的参数 (仅对数据被简单硬编码有效)
- spring boot整合Cucumber(BDD)
- 分布式缓存集群方案特性使用场景(Memcache/Redis(Twemproxy/Codis/Redis-cluster))优缺点对比及选型
- gitignore文件的添加
- 素数对--腾讯2017校招编程


