【NoSql】之Hbase
来源:互联网 发布:油画淘宝详情页模版 编辑:程序博客网 时间:2024/05/16 15:32
Hbase概述
· Hbase是构建在hdfs上的分布式列式存储系统
· Hbase内部管理的文件全部存储在HDFS上面,
· Hbase是基于google bigtable 模型开发的,典型的noSql-KeyValue数据库;
· Hbase是hadoop生态系统中的重要一员,主要用于海量结构化数据的存储;
· 从逻辑上讲,Hbase将数据按照表,行和列进行存储
· 与hadoop一样,Hbase目标主要依靠横向扩展,通过不断的增加廉价的商
用服务器来增加计算能力和存储能力。
Hbase表的特点
· 大:一个表可以有数十亿,上百万列;
· 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需求动态的增加,同一张表中不同的行包括了不同的列
· 面向列:面向列(族)的存储和权限控制,列(族)独立检索
· 稀疏:空(null并不占有存储空间)表可以设计的非常稀疏
· 数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本好自动
分配,是单元格插入的时间戳
· 数据类型单一:Hbase中的数据都是字符串.没有其他类型
HBase的数据模型
· Hbase的逻辑视图
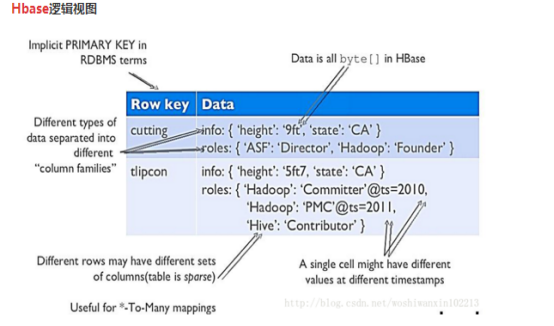
· Hbase的基本概念
RowKey:是byte array 是表中每条记录的主键,方便快速查找,rowkey的设计非常重要。
Columns Family:列族,拥有一个名称String,包含一个或多个相关列
Column :属于某一个ColumnsFamily familyName:columnname 每条记录动态添加
VersionNumber :类型为long ,默认值是系统时间戳,可由用户自定义
Value(cell)byte array
· Hbase的物理模型
每个colums family存储在HDFS上的一个单独文件中,空值不被保存
Key和version number 在每个column family 中均有一份
Hbase为每个值维护了多级索引
即<key,column family,column name ,timastamp>
· Hbase的物理存储
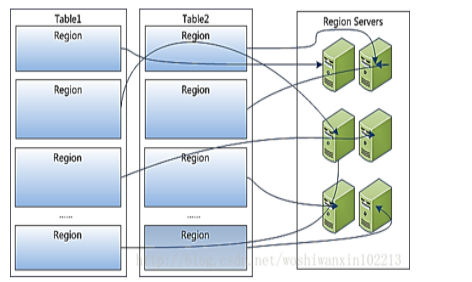
Table中所有的行都按照rowkey的字典顺序排序
Table 在行的方向上被分为多个Region
Region 按大小分割的.每个表开始只有一个Region 随着数据的增多,Region不断增大,当增大到一个阀值的时候,Region就会等分成两个新的Region,之后会越来越多的Region
Region是Hbase中分布式存储和负载均衡的最小单元,不同Region被分配到不同的RegionServer上。
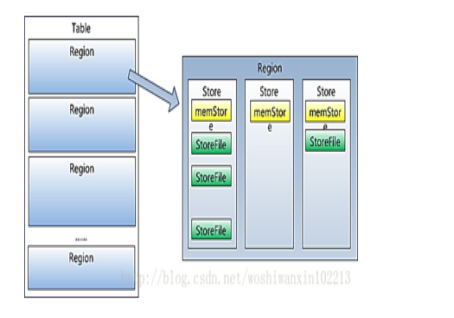
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由多个Store组成,每个store保存着一个columns family ;每个Store又由一个memStore和多个0个或多个StoreFile组成,StoreFile 包含HFile; memStore存储在内存中,StoreFile存储在HDFS上
· Hbase的架构及基本组件

基本组件说明
- Client
包含访问Hbase的接口,并维护cache来加快hbase的访问 比如Region的位置信息
- Master
为RegionServer 分配Region
负责RegionServer的负载均衡
发现失效的RegionServer并重新分配其上的Region
管理用户对table的增删改查
- RegionServer
RegionServer 维护Region 处理对这些Region的IO请求
RegionServer 负责切分在运行过程中变大的Region
- Zookeeper
通过选举,保证任何时候,集群当中只有一个Master.Master与RegionServer启动的时候会向Zookeeper注册
存储所有的Region的地址
实时监控RegionServer的上线和下线的信息。并适时通知给Master
存储着Hbase的schema和table元数据
默认情况下,Hbase管理Zookeeper实例,比如,启动或者停止Zookeeper
Zookeeper 的引入使得Master不再是单点故障
Hbase的容错与恢复机制
从架构中我们可以发现,每一个RegionServer中有一个HLog文件, 在每次用户操作写入MemStore的同时,也会先向Hlog中写一份,Hlog文件会定期更新,并删除旧的文件(已经持久化到StoreFile中的数据)。当RegionServer宕机以后,Master会通过Zookeeper感知到,Master首先会处理遗留的Hlog文件,将其不同的Region的log数据进行拆分,分别放到相应的Region目录上,然后再将失效的Region重新分配到其他RegionServers上,RegionServer在load Region过程中,会发现有历史Hlog需要处理,因此会replay Hlog中的数据到MemStore中然后flush进StoreFile中 完成数据的恢复
Hbase的容错性
- Master容错:zookeeper 重新选举一个Master
- RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未进行心跳,Master将该RegionServer上的Region重新分配到RegionServer上,失效服务器上 预写 hlog有Master分割并发送给其他的RegionServer上
- Zookeeper容错:Zookeeper是一个可靠的服务,一般配置3个或5个Zookeeper实例
Hbase的读写都要先经过先确定RegionServer的地址
过程大概如下:客户端先向ZK请求目标数据的地址
ZK保存了-ROOT-表的location,客户端根据location找到.META.表 其中包含了所有的用户空间Region列表,以及RegionSever地址,根据请求参数去表中查找,然后得到一个regionInfo列的数据 RegionServer
客户端根据RegionServer地址然后开始进行数据读和写
读:客户端发出读请求,客户端根据用户提供的表名,行键去客户端里的缓冲区进行查找,如果没有,就去Zookeeper进行查询,通过上面过程找到RegionServer地址和regioninfo信息,然后与RegionServer建立连接,将regioninfo列的数据提交给Regionserver
RegionServer接收到客户端的请求,然后创建一个RegionScanner对象,通过该对象定位到Region,然后Region创建StoreScanner,通过StoreScanner对定位到Store,Store创建一个MemStoreScanner对象,这个对象负责去MemStore中有没有数据,有就返回,没有就创建多个StoreFIleScanner对象,每个对象,负责去不同的HFile中查询数据。如果找到返回,找不到返回null
写:客户端发出写的请求,

当客户端进行put操作时,数据会自动保存到HRegion上,在HRegionServer中,找到对应要写入的HRegion之后,数据会写入到HLog中并同时写入到HStore的MemStore内存中,会在内存中按照行键对数据进行排序,当内存中的数据达到一定阈值后,会触发flush操作。Flush操作主要就是把MemStore内存中的数据写入到StoreFile中,当HDFS中的StoreFile个数达到一定的阈值后,会触发compact(合并)操作,将HDFS中所有的StoreFile合并成一个新的SotreFile,在合并的时候会按照行键进行排序,并且会进行版本合并和数据删除。当StoreFile通过不断的合并操作后,StoreFile文件会变得越来越大,当这个StoreFile达到一定的阈值后,会触发Split(切分)操作,同时把当前region拆分成两个新的region,原有的region会下线,新的两个region会被HMaster分配到相应的HRegionServer上,使得原来一个Region的压力得以分流到两个Region上,其实,HBase只是增加数据,更新和删除操作都是compact阶段做的,所以,客户端写入成功的标志是HLog和MemStore中都有数据。
先写HLog,但是如果显示MemSotre也是没问题的,因为MemStore的MVCC(多版本并发控制)不会向前滚动,这些变化在更新MVCC之前,Scan是无法看到的,所以在写入HLog之前,即使MemStore有数据,客户端也查询不到。
HBase的使用场景
- 大数据两存储.大数据两高并发操作
- 需要对数据随机读写操作
- 读写访问都是非常简单的操作
HBase的优化
1.RowKey的设计
Hbase是通过RowKey进行检索的,系统通过找到某个RowKey(或者某个RowKey范围)所在的Region。然后将查询数据的请求由该Region获取数据 Hbase支持3中检索方式
A)通过单个Rowkey访问,按照某个RowKey键值进行get操作获取唯一一条记录
B)通过RowKey的range进行scan即通过设置startRowkey和endRowKey,可以按指定的条件获取一批记录
C)全表扫描,即直接扫描整张表中所有行的数
设计原则:
·长度原则:不要超过16个字节
原因:如果rowKey长度过长,会极大影响HFile的存储效率
Memstore将缓冲的部分数据加载到内存,如果rowKey过长,内存的有效利用率会降低,从而降低检索效率
·唯一原则:保证唯一性
·散列原则:项目中的设计,因为我们的查找数据的时候,是按照时间戳进行查找的,所以时间戳应该是rowkey的一部分,把rowkey的低位放时间字段,
高位是用CRC32算法将eventName+uuid+memberid压缩保证唯一性
HBase和Hive的整合
整合的原理:
Hive和hbase的整合的实现是利用两者本身对外的API接口互相进行通信,主要是依靠hive/lib下的hive-hbase-handler-0.9.0.jar 他负责通信
整合的好处:
Hive方便的提供了Hql类sql语句接口来简化mapreduce的使用,而Hbase提供了低延迟的数据库访问。两者相结合就可以用mapreduce来对hbase中的数据进行离线的计算和分析
缺点:性能的损失
1.创建一个指向Hbase的hive表
create external table event_logs(
row string,
pl string,
en string,
s_time string,
p_url string,
u_ud string,
u_sd string)
row format serde 'org.apache.hadoop.hive.hbase.HBaseSerDe'
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
With serdeproperties('hbase.columns.mapping'=':key,info:pl,info:en,info:s_time,info:p_url,
info:u_ud,info:u_sd')
tblproperties('hbase.table.name'='event_logs');
**** 为了数据的安全,将表创建成外部表,防止删除表的时候将hbase表中的数据删除
2.添加数据的时候只能用insert....select....
3.两端的数据是同步的
4.Hive多列和hbase的多列出了行键和hive第一个字段不对应外,一一对应
5.Hive就是读取hbase的数据
HBase的过滤器

- NOSQL之旅---HBase
- NOSQL之旅---HBase
- NOSQL之旅---HBase
- NoSQL之HBase
- NOSQL之旅---HBase
- NOSQL之旅-----HBase
- NOSQL之旅-----HBase
- NoSql之初识HBase
- NOSQL之旅---HBase
- 【NoSql】之Hbase
- 主流NoSQL数据库评测之HBase
- NoSQL:列存储数据库之HBase
- NoSQL:列存储数据库之HBase介绍
- (NoSql之HBase)Hbase原理、基本概念、基本架构
- (NoSql之HBase)HBase简介(很好的梳理资料)
- NoSQL:列存储数据库之HBase超详细解读
- python模块系列 (二)之操作NoSQL数据库hbase
- NoSQL和HBase
- 基于Lock对象的Condition接口实现的有界队列
- 14. Longest Common Prefix(最长公共前缀) —— Java
- butterknife注解框架源码解析
- maven struts
- Shell脚本笔记
- 【NoSql】之Hbase
- 回文数问题
- 手机淘宝app这是怎么了,这是什么bug,还真没有见过。
- 遇到一个全新的需求项目,怎么办?
- input框中的文字加下划线
- Hive创建表
- LeetCode-75. Sort Colors
- Spring Boot将WAR文件部署到Tomcat
- 最小的K个数的多种解法


