集成学习
来源:互联网 发布:软件销售网站 编辑:程序博客网 时间:2024/05/29 10:12
注:本文中各个算法的部分借鉴
1 个体与集成
集成学习通过构建并结合多个学习器来完成学习任务,有时也被称为多分类系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。
两种集成:1)集成中只包含同种类型的个体学习器,这样的集成是同质的,同质集成中的个体学习器被称为“基学习器”;2)集成中可包含不同类型的个体学习器,这样的集成是异质的,集成中的个体学习器被称为“组件学习器”或直接称为个体学习器。
另一个概念:
弱学习器:常指泛化性能略优于随机猜测的学习器。
个体学习器的选择准则:好而不同,即个体学习器的准确性越高、多样性越大,则集成越好。
2 Boosting
Boosting是一族可将弱学习器提升为强学习器的算法。工作机制:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到实现指定的T,最终将这T个基学习器进行加权结合。
2.1 Adaboost
adaboost算法原理及推导可以查看本人的AdaBoost 算法原理及推导(该算法是串行式集成)
3 Bagging与随机森林
Bagging是并行式的集成学习方法最著名的代表,算法框架:基于自助法(参见本人的
训练集和测试集的产生方法
),假设训练集有m个样本,我们可以采样出T个含m个训练样本的采样集,然后基于每个训练集训练出一个基学习器,再将这些学习器进行结合。在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时出现两个类收到同样票数的情形,则最简单的做法是随机选择一个。从偏差-方差分解的角度看,Bosting主要关注降低偏差,Bagging主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更为明显。
3.1 随机森林(Random Forest, RF)
RF是Bagging集成上的一个扩展变体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练时引入随机属性选择。具体说,传统决策树在选择划分属性时是在当前属性结点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
RF简单,容易实现、计算开销小,在很多现实任务中展现出强大的性能,被誉为“代表集成学习技术水平的方法”。
4 结合策略
假定集成包含T个基学习器 ,其中
,其中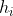 在示例
在示例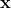 上的输出为
上的输出为 。
。
4.1平均法
对于数值型输出,最常见的结合策略就是平均法。
1)简单平均法
2)加权平均法
其中wi是个体学习器相应的权重。
一般而言,在个体学习器性能相差较大时宜用加权平均法,而在个体学习性能相近时宜用简单平均法。
4.2 投票法
分类任务输出为一个标记时,常用投票法(voting)
1)绝对多数投票法:某标记得票过半,则预测为该标记,否则拒绝预测;
2)相对多数投票法:预测为得票最多的标记,若同时又多个标记获得最高票,则从中随机选取一个。
3)加权投票法:与加权平均法类似
4.3学习法
当训练数据很多时,常采用“学习法”,即通过另一个学习器来进行结合。个体学习器称为初级学习器,用于结合的学习器称为次级学习器或元学习器。
Stacking是学习法的的典型代表:先从初始数据集中训练出初级学习器,然后生成一个新数据集用于训练次级学习器。在这个新训练数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。
5 多样性度量
5.1 多样性度量
声明:最近实在实在不想敲公式(懒病。。。),就上传了一页。。。

5.2 多样性增强
1)数据样本扰动
给定初始数据集,可以从中产生不同的数据子集,再利用不同的数据子集训练出不同的个体学习器,数据样本扰动通常是基于采样法。
2)输入属性扰动
训练样本通常由一组属性描述,不同的“子空间”提供了观察数据的不同视角,显然,从不同子空间训练出的个体学习器必然是不同的。著名的随机子空间算法就依赖于输入属性扰动,该算法从初始属性集中抽取出若干个属性子集,在基于每个属性子集训练一个基学习器。
3)输出表示扰动
基本思路是对输出表示进行操纵以增强多样性。
4)算法参数扰动
基学习器一般都有参数需进行设置,例如神经网络的隐层神经元数、初始连接权值等,通过随机设置不同的参数,往往可以产生差别较大的个体学习器。
阅读全文
0 0
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 集成学习
- 使用spring的test模块模拟MVC请求的方法
- Could not write content: No serializer found for class org.hibernate.proxy.pojo.javassist.JavassistL
- 爬取豆瓣的战狼影评(cookies 云词)
- 安装、使用 Mysql
- 实例展示elasticsearch集群生态,分片以及水平扩展
- 集成学习
- 最大公约数
- sudo:无法解析主机
- 矩阵旋转
- Laravel 框架 自动加载实现分析
- 媒体格式分析之flv -- 基于FFMPEG
- VBA msgbox用法
- Boost智能指针——shared_ptr
- ubuntu Removing nvidia cuda toolkit and installing new one


