Spark 调研报告
来源:互联网 发布:二次元衣服淘宝店 编辑:程序博客网 时间:2024/05/21 09:32
1.总结部分
什么是Spark?
Spark是个通用的集群计算框架
Spark用来做什么?
分发数据,分发计算
Spark的主要应用领域?
机器学习,最优化算法
为什么选择Spark?
- Spark对迭代应用的计算特别有效
- 可以类似Python REPL的命令行提示符交互式访问
- 快
Spark提供何种API?
Scala、Java和Python
Spark性能如何?
Hadoop,Spark速度对比 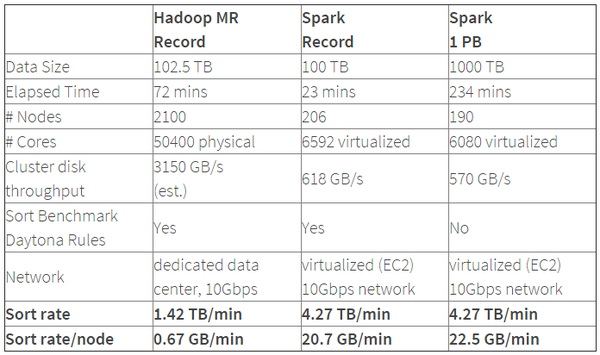
从表格中可以看出排序100TB的数据(1万亿条数据),Spark只用了Hadoop所用1/10的计算资源,耗时只有Hadoop的1/3。
Hadoop,Spark回归算法速度对比 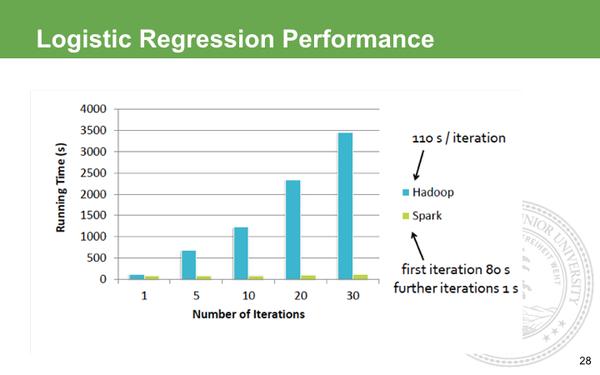
在Hadoop的世界里,做迭代计算是非常耗资源,它每次的IO序列代价很大,所以每次迭代需要差不多的等待。而Spark第一次启动需要载入到内存,之后迭代直接在内存利用中间结果做不落地的运算,所以后期的迭代速度快到可以忽略不计。
Spark的缺点?
由于代码质量问题,Spark长时间运行会经常出错,在架构方面,由于大量数据被缓存在RAM中,Java回收垃圾缓慢的情况严重,导致Spark性能不稳定,在复杂场景中SQL的性能甚至不如现有的Map/Reduce。
不能处理大数据,单独机器处理数据过大,或者由于数据出现问题导致中间结果超过RAM的大小时,常常出现RAM空间不足或无法得出结果。然而,Map/Reduce运算框架可以处理大数据,在这方面,Spark不如Map/Reduce运算框架有效。
内存断电后会丢失数据,Spark不能用于处理需要长期保存的数据。
不能支持复杂的SQL统计;目前Spark支持的SQL语法完整程度还不能应用在复杂数据分析中。在可管理性方面,SparkYARN的结合不完善,这就为使用过程中埋下隐忧,容易出现各种难题。
Spark的学习成本?
- 官方目前侧重Scala要优于Java与Python,所以建议学习Scala
学习spark, 推荐用scala. 首先了解rdd和dsstream, 用mllib从头到尾实现一下官网的决策树, 逻辑斯蒂回归, 线性回归, 找到成就感, 在这个过程中你也许会踩到不少坑, 也会学习到一些基础的也是核心的概念, 比如何时需要persist, 何时需要cache, 何时需要广播变量, 全局accumulator, rdd stage划分, 为什么需要避免在class内的函数的rdd里引用外部变量, driver和executor区别。
Spark的官方建议的部署要求(维护成本)
通常,在内存容量为8GB到数百GB的主机上,Spark都能很好地运行。在任何情况下,我们都推荐最多只把物理主机上75%的内存分配给Spark;剩下的留给操作系统和缓存。
你需要多少内存取决于你的应用程序。要确定你的应用程序在某个数据集上执行时需要多少内存,可以在Spark
RDD中加载一部分数据集,并借用Spark 监控UI(http://:4040)上的存储表格(Storage
tab)来查看其内存用量。要注意的是内存用量受存储级别和序列化格式的影响极大——解决方法详见Spark调优一文。请注意,配置了200GB以上内存的Java虚拟机并不能总是正常工作。如果你购买的主机配备的内存超过了这个数值,那么可以在每个主机上启动多个worker JVM来解决这个问题。在Spark Standalone集群上,你可以使用配置文件conf/spark-env.sh中的变量SPARK_WORKER_INSTANCES来设置每个节点上的worker数量,用变量SPARK_WORKER_CORES来设置每个worker上分配的CPU核数。
我们的经验表明,当数据加载到内存时,大多数Spark应用程序都将受制于网络。最好的办法就是使用10Gbps或更高带宽的网络来加快应用的执行速度。这个办法对于那些分布式reduce应用程序(如group-bys,reduce-bys,及SQL joins)特别有用。在任何一个应用程序中,你都可以从其监控UI(http://:4040)上看到Spark通过网络传输了多少数据量。
综上所述:相比Hadoop,Spark所需的硬件成本更高(内存比硬盘贵)
2.实践部分
在Python中应用Spark
环境:
- JAVA 6+
- Python 2.6+
1.配置环境变量
SPARK_HOME=/srv/sparkPATH=%SPARK_HOME%/bin2.建立一个Spark模板
from pyspark import SparkConf, SparkContext## Module ConstantsAPP_NAME = "My Spark Application"## Closure Functions## Main functionalitydef main(sc): passif __name__ == "__main__": # Configure Spark conf = SparkConf().setAppName(APP_NAME) conf = conf.setMaster("local[*]") sc = SparkContext(conf=conf) # Execute Main functionality main(sc)- Spark 调研报告
- Spark Shuffle 的调研
- Nutch使用调研报告
- 如何写调研报告
- 软件培训调研报告
- 调研报告的格式
- 软件培训调研报告
- 软件培训调研报告
- 软件培训调研报告
- 软件培训调研报告
- 机器翻译市场需求调研报告
- Nutch调研报告(1)
- Nutch调研报告(2)
- 即时通讯调研报告
- 网络爬虫调研报告
- 网络爬虫调研报告
- 网络爬虫调研报告
- 监控系统调研报告
- iOS 原生库对 https 的处理
- Redis集群:基于twemproxy的实现
- 项目中使用aar
- glide加载到自定义圆形imageview不显示的问题
- JDK1.8新特性
- Spark 调研报告
- HashMap 与 ConcurrentHashMap 的区别
- 第十五章 套接字和标准I/O
- Codeforces AIM Tech Round 4 (Div. 2) A. Diversity
- ECharts 实现甘特图实例(自定义生成)
- Android显示框架:Activity应用视图的创建流程
- redis设置开机自启动,redis注册到服务中
- 区块链共识机制概要扫描
- gsoap设置超时


