Machine Learning---4---Logistic回归
来源:互联网 发布:安捷伦34401a 编程 编辑:程序博客网 时间:2024/05/21 07:47
(1)写在前面的话:
机器学习算法一般是这样一个步骤:
1)对于一个问题,我们用数学语言来描述它,然后建立一个模型,例如回归模型或者分类模型等来描述这个问题;
2)通过最大似然、最大后验概率或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题。找到最优化问题的解,也就是能拟合我们的数据的最好的模型参数;
3)然后我们需要求解这个代价函数,找到最优解。这求解也就分很多种情况了:
a)如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为0的点
b)如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,也就互相依赖的情况。这时候我们 就需要借助迭代算法来一步一步找到最有解了。(2)Logistic回归 :
模型:
主要用于二分类,假设我们的样本是{x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:

这里θ是模型参数,也就是回归系数,σ是sigmoid函数。设输入数据x有n个特征,即n维,由以上知Sigmoid函数的输入z可表示为:
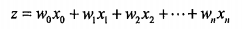
采用向量的写法,上式可以写成 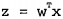 ,向量w就是我们要找的最佳系数。
,向量w就是我们要找的最佳系数。
优化:
梯度上升法
基本思想:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。
如果梯度记为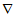 ,则函数 f(x,y) 的梯度表示为:
,则函数 f(x,y) 的梯度表示为:
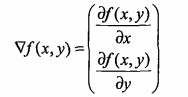
这个梯度意味着要沿x的方向移动 ,沿y的方向移动
,沿y的方向移动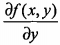 。可以看到梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记做α。用向量来表示的话,梯度算法的迭代公式如下:
。可以看到梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记做α。用向量来表示的话,梯度算法的迭代公式如下:
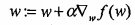
该公式将一直被迭代执行,直至达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
(3)Python代码实现:
## 用Logistic回归进行分类'''常用处理缺失值的做法: 使用可用特征的均值来填补缺失值; 使用特殊值来填补缺失值,如-1; 忽略有缺失值的样本; 使用相似样本的均值添补缺失值; 使用另外的机器学习算法预测缺失值'''import numpy as np#import math#改进的随机梯度上升算法def stocGradAscent1(dataMatrix, classLabels, numIter=500): dataMatrix =np. array(dataMatrix) m,n = np.shape(dataMatrix) weights = np.ones(n) #系数初始化为1 for j in range(numIter): # 指定迭代次数,默认为150 dataIndex = list(range(m)) for i in range(m): #alpha会随着迭代次数不断减小,但存在常数项,它不会小到0 #这种设置可以缓解数据波动 alpha = 4/(1.0+j+i)+0.0001 #通过随机选取样本来更新回归系数 randIndex = int(np.random.uniform(0,len(dataIndex))) h = sigmoid(sum(dataMatrix[randIndex]*weights)) error = classLabels[randIndex] - h weights = weights + alpha * error * dataMatrix[randIndex] del(dataIndex[randIndex]) return weights def classifyVector(inX, weights): ''' 分类函数 ''' prob = sigmoid(sum(inX*weights)) if prob > 0.5: return 1.0 else: return 0.0def colicTest(): frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt') trainingSet = []; trainingLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr =[] for i in range(21): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[21])) #数据的最后一列为类别标签 trainWeights = stocGradAscent1(trainingSet, trainingLabels, 1000) errorCount = 0; numTestVec = 0.0 for line in frTest.readlines(): numTestVec += 1.0 currLine = line.strip().split('\t') lineArr =[] for i in range(21): lineArr.append(float(currLine[i])) if int(classifyVector(np.array(lineArr), trainWeights))!= int(currLine[21]): errorCount += 1 errorRate = (float(errorCount)/numTestVec) print("the error rate of this test is: %f" % errorRate) return errorRatedef multiTest(): ''' 多次调用colicTest()函数,求结果的平均值 ''' numTests = 10; errorSum=0.0 for k in range(numTests): errorSum += colicTest() print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))) if __name__== "__main__": multiTest()阅读全文
0 0
- Machine Learning---4---Logistic回归
- Machine Learning---Logistic回归
- 【Machine Learning】逻辑回归 Logistic Regression
- Machine Learning逻辑回归(Logistic Regression)
- 3、Logistic Regression 逻辑回归 [Stanford - Machine Learning]
- Coursera-Machine Learning 之 Logistic Regression (逻辑回归)-0x01
- Coursera-Machine Learning 之 Logistic Regression (逻辑回归)-0x02
- Machine Learning - VI. Logistic Regression逻辑回归 (Week 3)
- [Machine Learning]4.逻辑回归(logistic regression)
- Machine Learning in Action 学习笔记-(5)Logistic回归
- [笔记]机器学习(Machine Learning) - 02.逻辑回归(Logistic Regression)
- Machine Learning第三讲[Logistic回归] --(三)多元分类
- Machine Learning——Logistic Regression(逻辑回归)
- Machine Learning第三讲[Logistic回归] --(二)Logistic回归模型
- Machine Learning:Logistic Regression
- [Machine Learning]--Logistic Regression
- Machine Learning--logistic regression
- Machine Learning:Logistic Regression
- chrome调试时遇到
- 【PAT】【Advanced Level】1085. Perfect Sequence (25)
- ffmpeg中tbr tbc tbn的含义解释
- redis缓存
- 微信小程序wx.navigateTo页面不跳转
- Machine Learning---4---Logistic回归
- GridView 的基础知识
- 通达oa破解版|通达oa破解补丁|通达oa破解版下载2017
- 【年终总结】终归平静
- 如何实现远程连接(SSH)iPhone/iPad?
- POJ 3281 Dining 网络流
- 从oracle中读取blob图片资源
- 2017.9.1 开学就考试
- C/C++文件操作函数使用总结


