使用weka内置算法分析数据(图形界面操作)
来源:互联网 发布:emlog博客源码 编辑:程序博客网 时间:2024/05/29 18:19
原文
本文使用weka中内置的三种分类算法(naive bayes,SVM,Logistic Regression)根据收集到的鸢尾属植物的数据进行分类,通过精度和效率对三种算法进行比较。
1、鸢尾属植物的分类
数据中包含鸢尾属植物的四种属性。四种属性分别是萼片长度、萼片宽度、花瓣长度、花瓣宽度。数据中还包含鸢尾属植物的三种种类,分别是:Iris-setosa(山鸢尾)、Iris-Versicolous(杂色鸢尾)、Iris-Virginica(维吉尼亚鸢尾)。也就是说,每行数据有5个属性(花萼长度、花萼宽度、花瓣长度、花瓣宽度、所属种类)
通过weka图形界面的Experimenter模块添加三种算法,采用十折交叉验证来分析三种算法的结果。图1.1是三种算法分类的正确率对比。 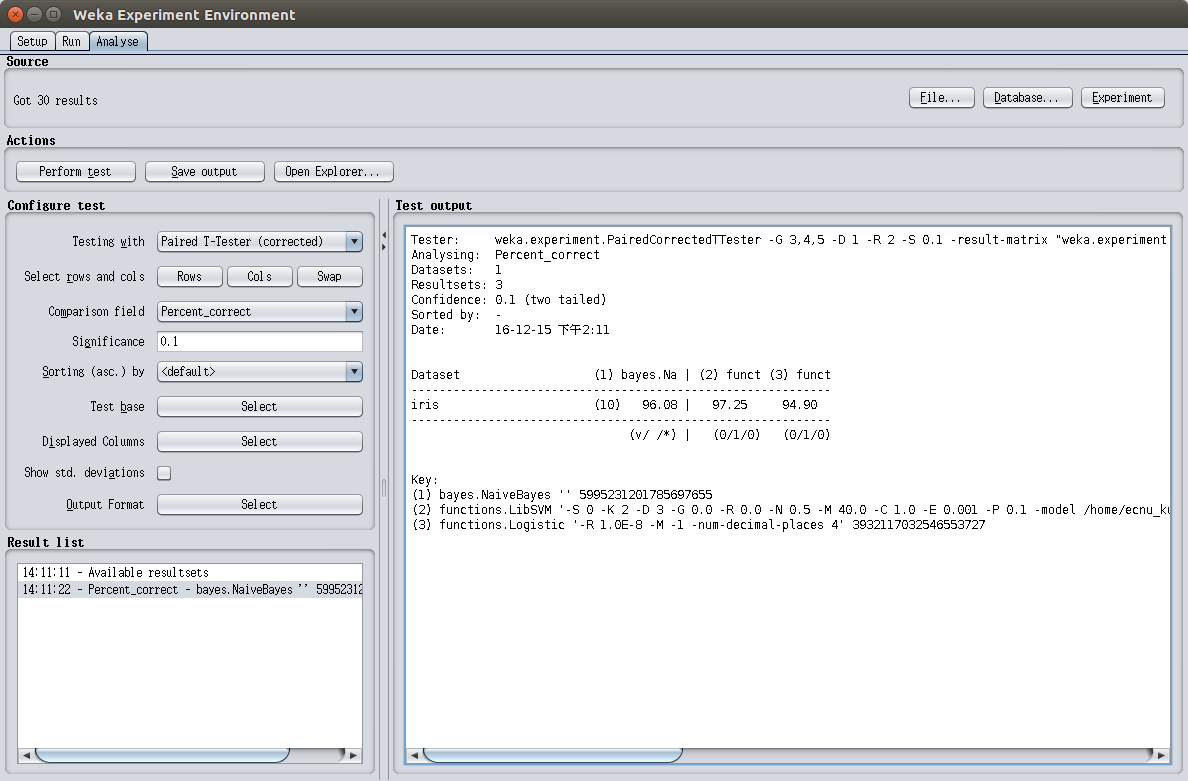
从图1.1的列表中可以看出,对于当前数据集的表现,三种算法在指定的显著性水平(significance level,这里设定是0.1)下可以认为正确率基本等同。
再比较三种算法正确分类个数的平均值,如图1.2所示,三种算法正确分类个数的平均值在显著性水平值为0.1的情况下可以认为是等同的。
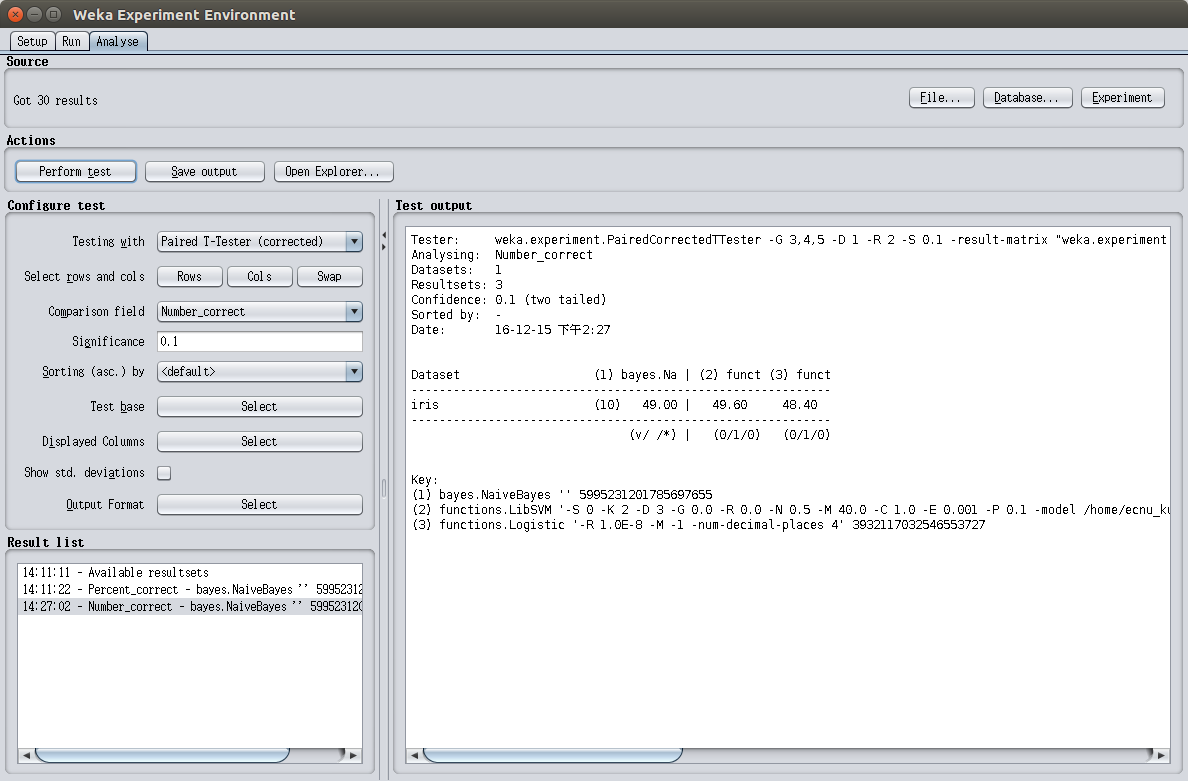
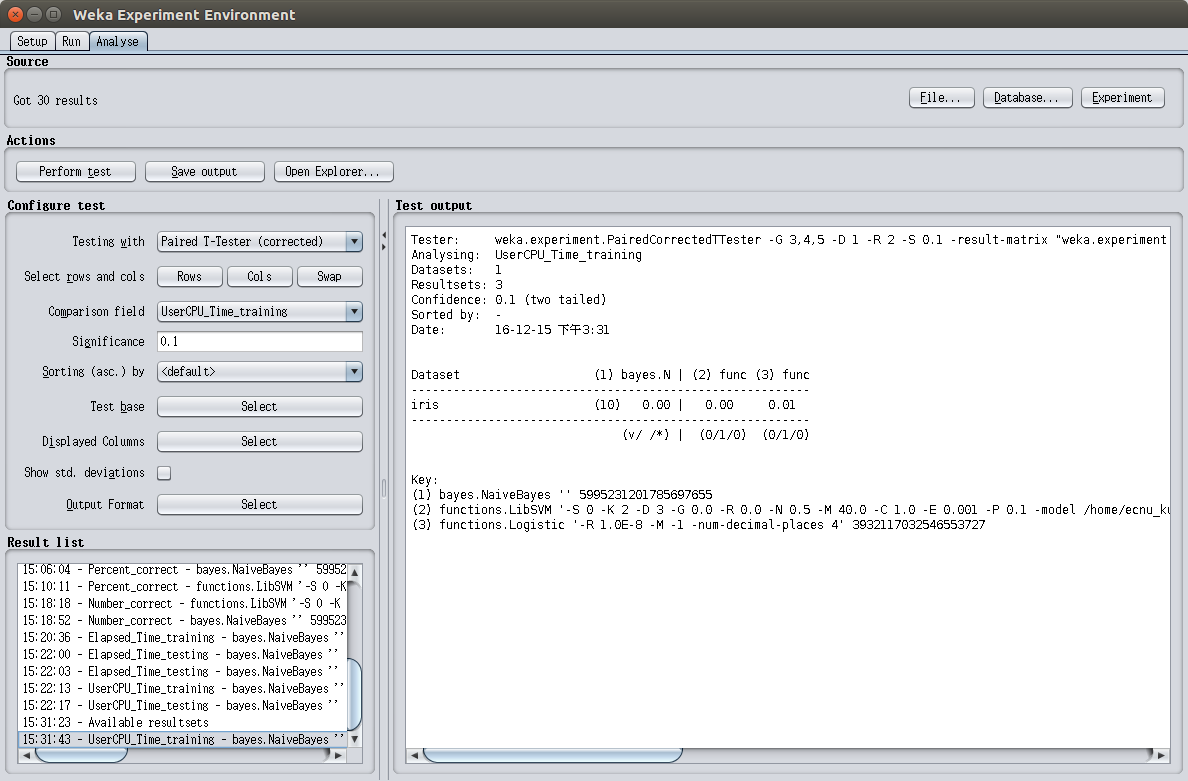
图1.3是CPU执行三种算法处理训练任务所花费的时间对比,可以看出,Logistic Regression和SVM在训练上所花费的总时间要多于Naive Bayes。也就是说,在处理这个数据集时,Naive Bayes的时间性能要比Logistic Regression和SVM要好
综上,三种算法在处理本数据集的对比如表1.1所示
2、甲状腺功能减退类型分类
数据集中包含一系列属性,这些属性是甲状腺功能减退患者自身的一些特征,比如年龄、性别等。除此之外,还有一个甲状腺功能减退类型的属性作为标签。使用三种不同的算法进行分析。得到如图2.1的结果。 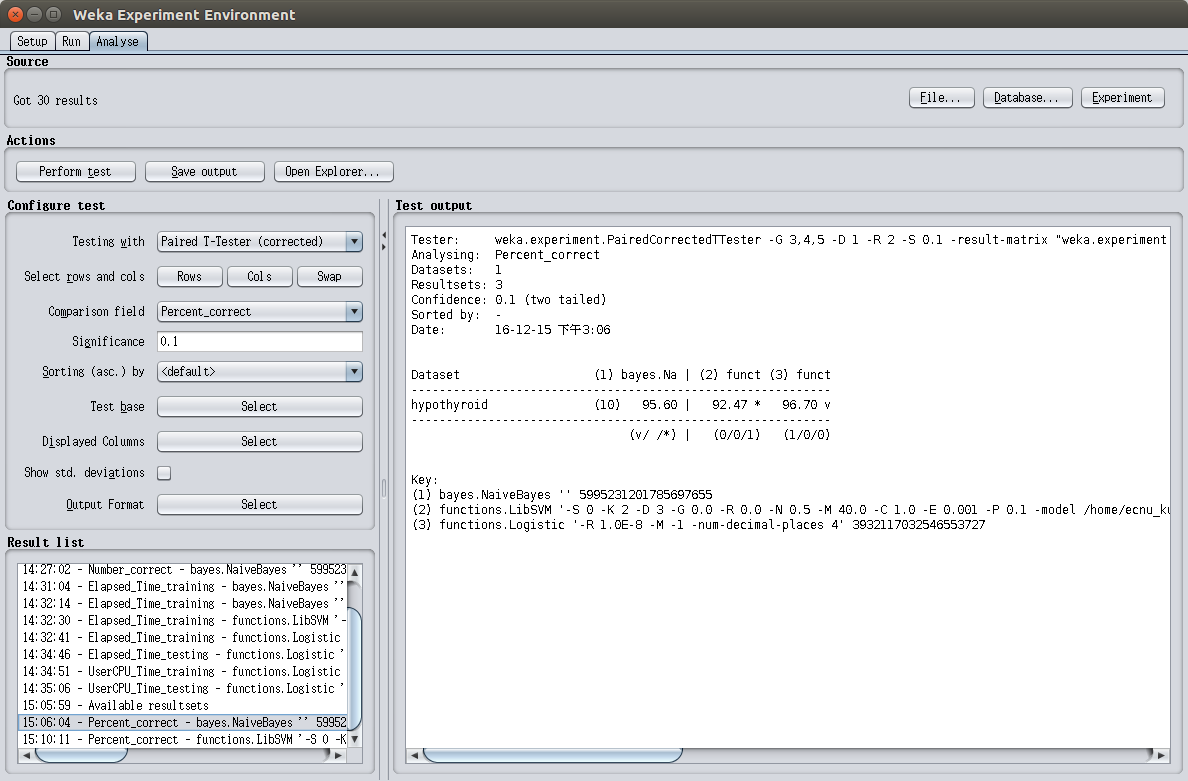
由图2.1可以看出,在显著性水平为0.1的情况下,SVM算法的表现要比Naive Bayes差,而Logistic Regression的表现要好于Naive Bayes。
图2.2是三种算法正确分类个数的平均值的情况。
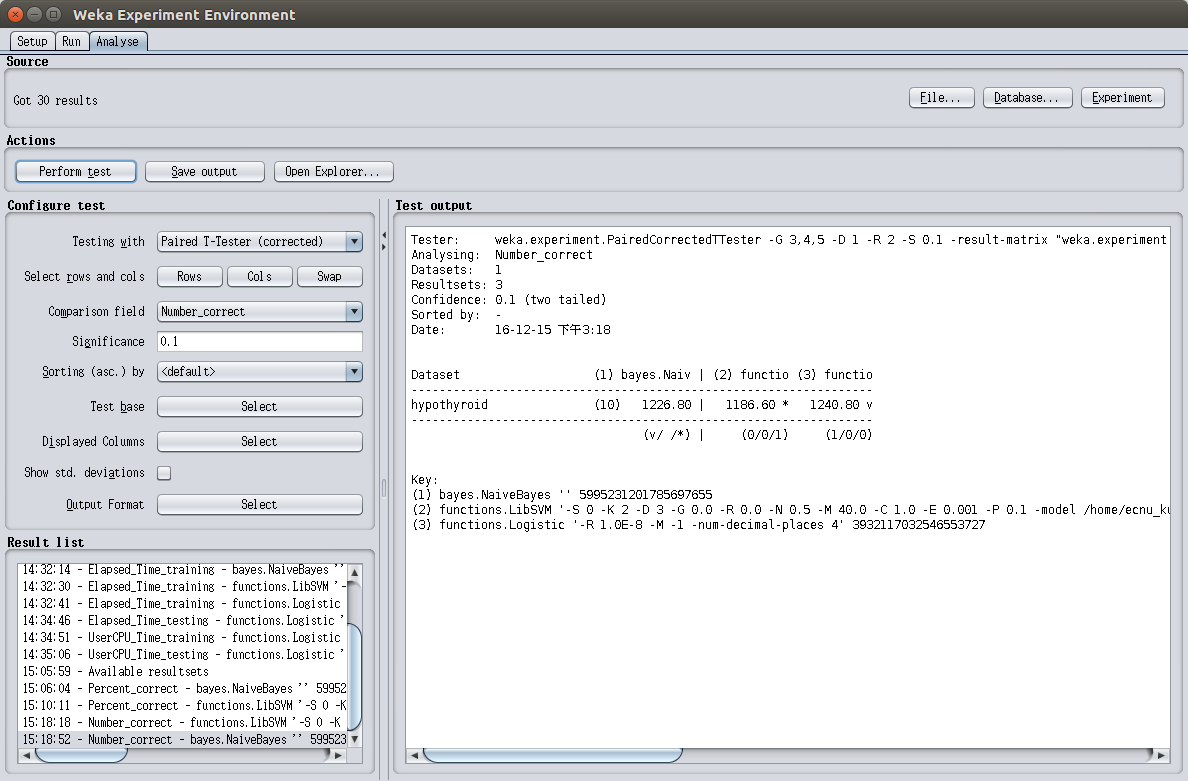
CPU执行三种算法训练模型所花费的时间如图2.2所示,测试所花费的时间如图2.3所示
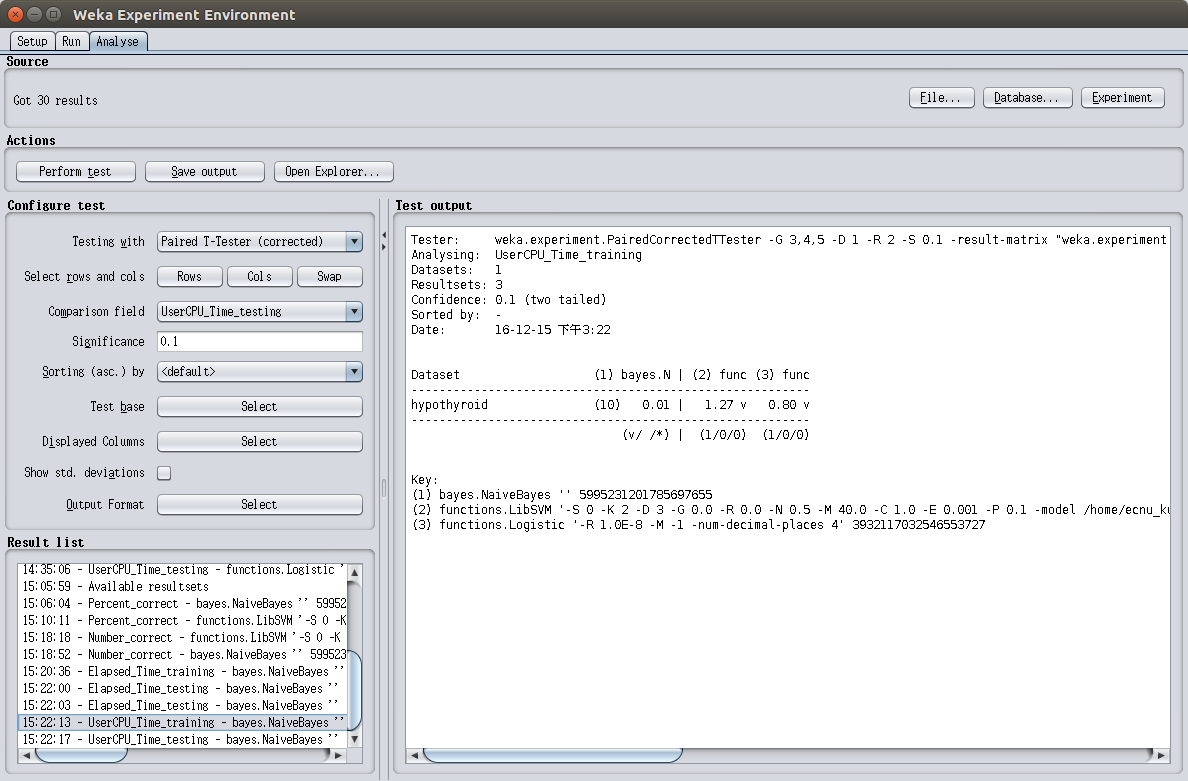
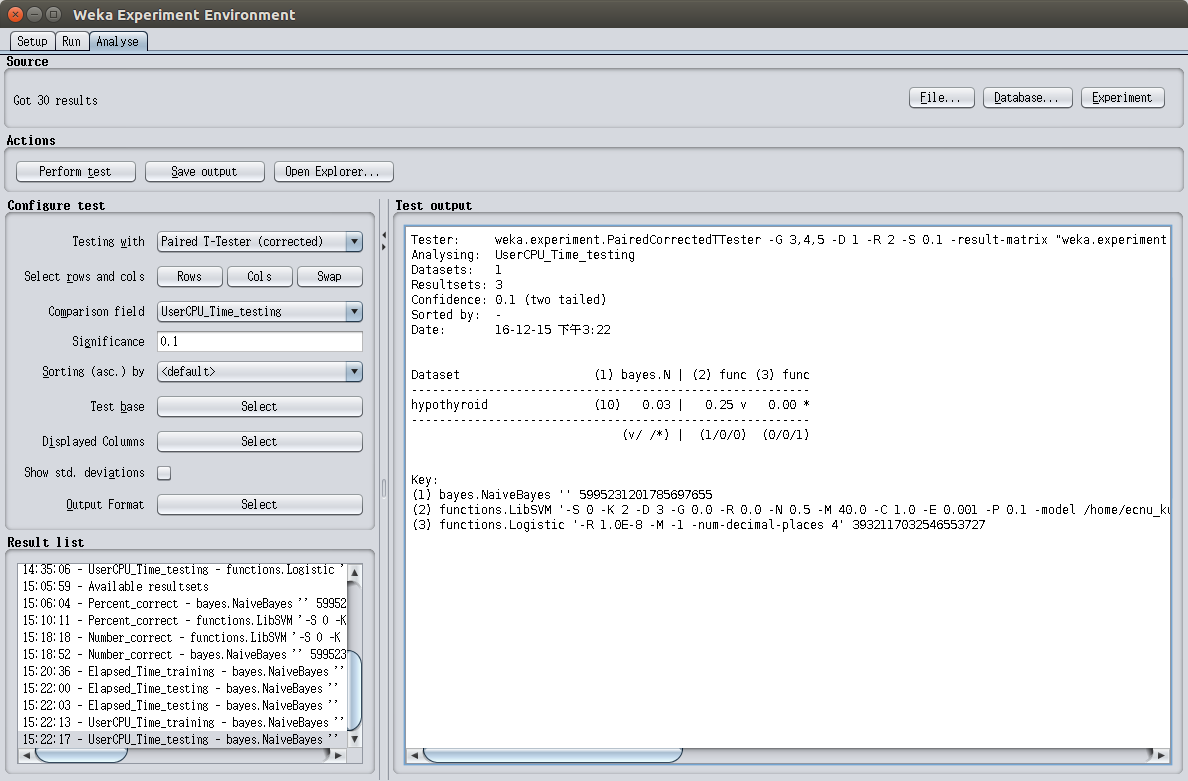
综上所述,三种算法在处理本数据集的表现对比如表2.1
阅读全文
0 0
- 使用weka内置算法分析数据(图形界面操作)
- weka:调用内置算法挖掘数据关联规则
- 使用Weka进行数据挖掘(Weka教程八)Weka分类评价Evaluation输出分析
- Weka数据采集操作
- weka数据挖掘分析
- 数据分析软件SPSS及数据挖掘软件WEKA使用
- Weka内置特征选择算法整理
- Weka介绍--使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 数据挖掘工具weka使用
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- 使用Weka进行数据挖掘
- Qt5注册全局热键
- Hadoop Left Join2
- Linux下C语言多线程学习之一——线程的创建
- 网页特效代码
- Codeforces
- 使用weka内置算法分析数据(图形界面操作)
- Atitit 个人 企业 政府 等组织 财政收入分类与提升途径attilax总结 v2
- Python(三)
- ubuntu 解决“无法获得锁 /var/lib/dpkg/lock -open”的方法
- js监控enter键触发函数提交数据或者登陆
- 梯度下降
- Mybatis之Mapper动态代理方式
- Java语言匿名对象
- html-css练习题(系统提示)


