Hadoop InputFormat介绍
来源:互联网 发布:淘宝网半身长裙 编辑:程序博客网 时间:2024/06/18 15:39
Hadoop InputFormat介绍
1 概述
我们在编写MapReduce程序的时候,在设置输入格式的时候,会调用如下代码:
job.setInputFormatClass(KeyVakueTextInputFormat.class)通过上面的代码来保证输入的文件是按照我们想要的格式被读取,所有的输入格式都继承于InputFormat,这是一个抽象类,其子类有专门用于读取普通文件的FileInputFormatt,用于读取数据库文件的DBInputFromat,用于读取HBase的TableInputFormat等等。如下图是InputFormat的图谱。
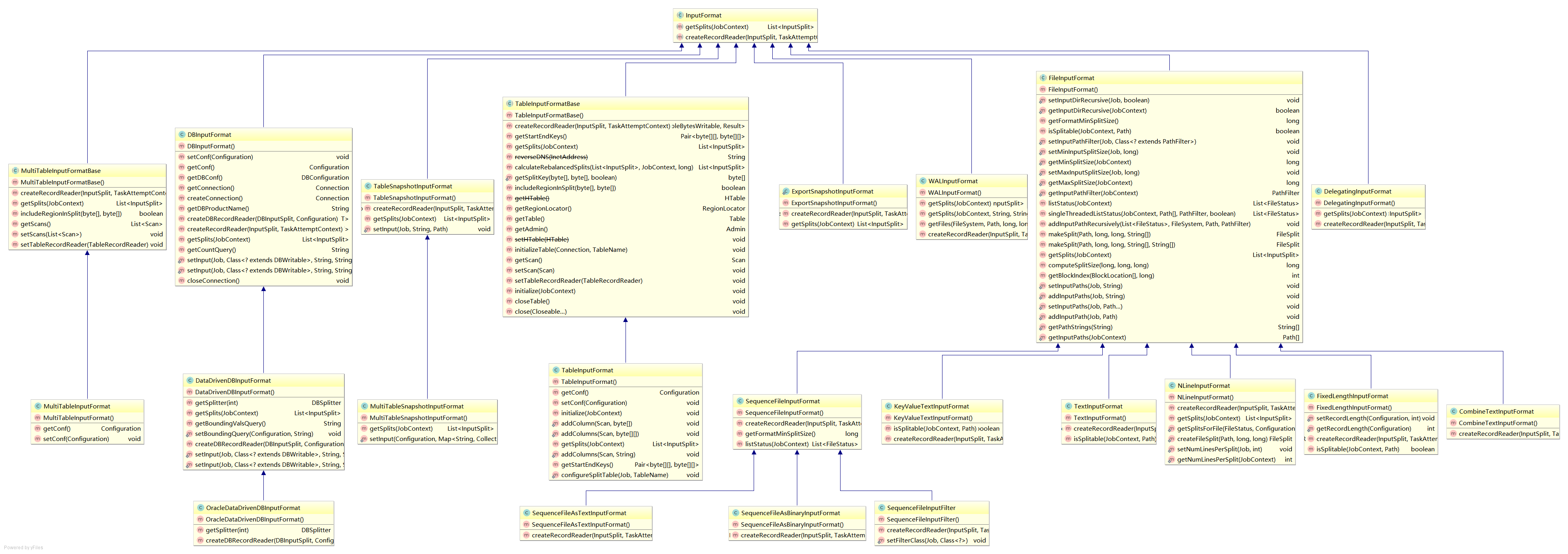
2 InputFormat方法
从类图中可以看出,InputFormat抽象类仅有两个抽象方法:
public abstract List<InputSplit> getSplits(JobContext context)public abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context)getSplits()方法是逻辑上拆分作业的输入文件集,然后将每个InputSplit分配给一个单独的Mapper进行处理
注意:拆分是按输入文件的逻辑分割,而输入文件不会被物理分割成块。每个切片都是一个<input-file-path,start,offset>的元组,InputFormat并创建相应的RecordReader读取这些切片。
createRecordReader()方法是为给定的切片创建一个记录阅读器。在切片被使用之前先调用RecordReader.initialize(InputSplit, TaskAttemptContext)方法。
通过InputFormat,MapReduce框架可以做到:
1. 验证作业输入的正确性
2. 将输入的文件切割成逻辑分片(InputSplit),一个InputSplit将会分配给一个独立的MapTask
3. 提供RecordReader实现,读取InputSplit中的Kv对供Mapper使用。
不同的InputFormat会各自实现不同的文件读取方法以及分片方式,每个输入分片会被单独的MapTask作为数据源。下面将介绍InputSplit和RecordReader。
3 InputSplit介绍
MapTask的输入是一个输入切片,称为InputSplit。InputSplit也是一个抽象类,它在逻辑上包含给处理这个InputSplit的Mapper的所有KV对。不同类型的输入格式对应不同类型的切片,下图是InputSplit的类图。

3.1 InputSplit方法
// 获取切片大小,并且根据size对切片排序public abstract long getLength()// 获取存储该分片的数据所在的节点位置,其中的数据是本地的,位置信息不需要序列号public abstract String[] getLocations()// 获取有关切片在那个节点上的信息,以及它是如何存储在每个位置的public SplitLocationInfo[] getLocationInfo()4 RecordReader
RecorderReader将读入到Map的数据拆分成KV对。RecorderReader也是一个抽象类。下面是RecordReader的类图:

接下来看一下RecordReader的源代码:
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable { /** * 由一个InputSplit初始化 */ public abstract void initialize(InputSplit split, TaskAttemptContext context ) throws IOException, InterruptedException; /** * 读取分片下一个KV */ public abstract boolean nextKeyValue() throws IOException, InterruptedException; /** * Get the current key */ public abstract KEYIN getCurrentKey() throws IOException, InterruptedException; /** * Get the current value. */ public abstract VALUEIN getCurrentValue() throws IOException, InterruptedException; /** * 跟踪读取分片的进度 */ public abstract float getProgress() throws IOException, InterruptedException; /** * Close the record reader. */ public abstract void close() throws IOException;}参考博文
http://www.cnblogs.com/shitouer/archive/2013/02/28/hadoop-source-code-analyse-mapreduce-inputformat.html
- Hadoop InputFormat介绍
- Hadoop InputFormat浅析
- Hadoop InputFormat分析
- hadoop InputFormat解析
- Hadoop InputFormat浅析
- Hadoop InputFormat浅析
- Hadoop InputFormat浅析
- Hadoop自定义InputFormat
- Hadoop InputFormat浅析
- hadoop自定义InputFormat
- Hadoop自定义InputFormat
- Hadoop InputFormat浅析
- 自定义hadoop的inputformat
- Spark with Hadoop InputFormat
- 自定义hadoop的InputFormat
- Hadoop InputFormat记录
- Hadoop InputFormat源码分析
- Hadoop InputFormat浅析
- ijkplayer编译 定NDK 路径
- 信号处理函数的返回sigsetjmp/siglongjmp
- AJAX学习详解
- Android开发小技巧系列(四)
- 讲特征工程的两个文章
- Hadoop InputFormat介绍
- [门户自用]JEECMS v5版标签之[@cms_content_list],重点看orderby排序
- 第一篇博客
- C# 调用带有输出参数的分页存储过程
- 图像语义分割之FCN和CRF
- sql语句记录
- JNI中文手册
- 操作系统复习要点总结
- mysql 数据库安装教程


