Kafka的定时消息/任务服务
来源:互联网 发布:mac如何查看文件大小 编辑:程序博客网 时间:2024/05/15 13:04
基于kafka的定时消息/任务服务
前言
定时任务,在很多业务场景中都会存在.一般,我们简单解决的话,就是使用数据库来存储数据供服务端周期获取执行.显然,对于数据库处理,如果多线程或者多机器处理,就会存在扩展的问题.比如:现在一个任务记录到时间了需要执行,同时被多个executor抓取来执行,就会浪费不必要的资源;并且,这种场景还非常常见. 因此, 需要额外状态处理,或者其他分库分表策略保证尽量一个executor来操作一个记录,并且如果executor失败了,其他的executor才会去执行分配给失败executor的任务. 整个设计相对而言,就相当复杂了.
基于上面的一些原因,这里我们设计了一个简单的基于kafka消息队列的定时任务方案.
这里,首先定义一下定时消息。所谓定时消息,就是业务方根据自己的业务需求,指定在接下来的大概某个时间点来发送某条消息,从而保证该消息在某个时间点之后可接受的时间区间内消费该消息。所以这里需要指出:
Note:
消息机制都是异步的,所以如果存在大量消息累积未消费,则无法保证定时消息指定的时间区间。因此,使用的时候,必须预计定时消息服务提供的服务能否满足业务的QPS要求。定时消息服务设计保证支持水平扩展,因此,可以根据业务性能需求,部署足够的服务。
kafka消息队列,所有触发都是基于消息机制的。所以,定时任务的设计必须要有定时消息服务来提供基础核心功能。首先,就需要设计一个基于kafka队列的定时消息服务。
定时消息服务总体设计
定时消息服务,这里主要是服务于定时任务设计的;但是,这不意味着它不能单独提供服务。相反,定时消息服务设计时,考虑是单独部署,单独提供服务的。而定时任务,是基于定时消息服务进行封装的client端,便于没有kafka或者其他消息队列的开发者,可以直接使用,而不需要额外学习kafka的使用,虽然其接口很简便。
首先,给出定时消息服务整体的交互图:

从以上的交互图可以看到,业务方produce的定时消息,其 topic 是让 定时消息服务单独consume的;然后kafka-dms 服务将业务方produce生成的消息进行解析处理,剥离出真实的topic和payload,以及可能有的partitioner。拿到真实业务的消息,kafka-dms就可以根据业务的要求,延迟到指定的时间去produce kafka消息。这样,真实的业务consumer就可以在指定时间后消费定时消息。
整个交互并不复杂,简洁满足需求,可以更容易的后期维护。
和很多同学一样,简洁的设计并不意味着实现起来就简单。在实现过程中,考虑到业务的需求,以及开发的成本,做了一些折中权衡。
定时消息服务具体设计与关键实现
在实现的时候,为了简单且满足需求,对于开发遇到的一些问题,进行了处理和简化。
定时时间限制
由于每个业务对于需要延迟多长时间来让消费者消费消息是多种多样的,此外,基于定时消息模式处理的业务,对于时间的精准性要求并不是很高。比如,存在一个业务场景,调用外部的异步接口,接口只会告知调用已接受并处理,但是处理结果一般是通过异步回调的方式来告知;但是由于回调未必会成功,但是业务一直处于中间状态,这个时候是需要通过查询机制来获取真实状态,完成状态调整的。这种场景,是不会对定时执行时间要求很高的,一般其只需要在约定业务处理时间后的某个时间触发即可。
基于很多上面类似场景的情况,这里我们对定时时间进行限制。也就是,业务方只能在指定的延迟时间来选择。当然,这里的延迟时间是可以根据具体使用来具体调整的。默认,我们的延迟时间级别如下:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748
public enum MsgDelayedLevel {// 1MS 主要服务异步任务ONE_MS_DELAYED(0,1L),// 1秒ONE_S_DELAYED(1, 1000L),// 5秒FIVE_S_DELAYED(2, 5 * 1000L),// 10秒TEN_S_DELAYED(3, 10 * 1000L),// 20秒TWENTY_S_DELAYED(4, 20 * 1000L),// 30秒THIRTY_S_DELAYED(5, 30 * 1000L),// 1分钟ONE_M_DELAYED(6, 60 * 1000L),// 5分钟FIVE_M_DELAYED(7, 5 * 60 * 1000L),// 10分钟TEN_M_DELAYED(8, 10 * 60 * 1000L),// 20分钟TWENTY_M_DELAYED(9, 20 * 60 * 1000L),// 30分钟THIRTY_M_DELAYED(10, 30 * 60 * 1000L),// 1小时ONE_H_DELAYED(11, 60 * 60 * 1000L),// 2小时TWO_H_DELAYED(12, 2 * 60 * 60 * 1000L),// 3小时THREE_H_DELAYED(13, 3 * 60 * 60 * 1000L),// 6小时SIX_H_DELAYED(14, 6 * 60 * 60 * 1000L),// 12小时TWELVE_H_DELAYED(15, 12 * 60 * 60 * 1000L),// 1天ONE_D_DELAYED(16, 24 * 60 * 60 * 1000L),// 2天TWO_D_DELAYED(17, 2 * 24 * 60 * 60 * 1000L),;private int level;private long delayedMs;MsgDelayedLevel(int level, long delayedMs) {this.level = level;this.delayedMs = delayedMs;}}
Topic 细分
延迟时间限制,很大的原因,是因为实现的时候,基于kafka的消息必须顺序消费,这就意味着,如果同一个topic的partitioner内,必须定时的时间都按照顺序排序的。否则,我们只能将所有队列的消息都拿出来消费,然后在内存中排序(万一down机就完了),或者保存在数据库中(又回到最初避免的问题上了)。
基于以上问题,我们对延迟时间进行了级别限制,然后这些级别反映到 Topic 上面。也就是,目前的设计中,我们对每个级别的延迟,都单独提供了一个 Topic 来处理。这就很好地规避了以上 kafka 特性而导致实现上的问题。
每个 topic 的对应的消息队列都是一个水平的超时时间,因此,后面进入到消息队列的消息,执行时间肯定是在前面消息之后的(不考虑不同服务器的网络差异问题)。这就意味着,如果前面消息未到处理时间,后面消息,肯定可以不需要处理。
Topic 生成规则:
123
public static final String DELAYED_MSG_PREFIX = "KAFKA_DELAYED_MSG_";String topic = KafkaConstants.DELAYED_MSG_PREFIX + delayedLevel.getLevel();
延迟消息处理
从 kafka 消息队列中 pull到消息,按照约定的格式进行解析,然后进行处理,produce 真实的业务消息,push 到kafka消息队列中。当我们pull到的消息还未到定时时间,则阻塞等待时间,交给schedulerThread来执行,执行完了之后,会手动触发commit offset,从而消费对应partitioner的下一条消息。这里可能性能有问题,不过通过多部署实例和多partitioner来扩展。
核心的定时消息处理:
123456789101112131415161718192021222324252627282930
private void processHandler(final String key, final MessageBody body, final ConsumerConnector connector) {long now = System.currentTimeMillis();if (body.getCurrentTime() > now || body.getCurrentTime() <= 0) {body.setCurrentTime(now);}long diff = now - body.getCurrentTime() - DELAYED_LEVEL_MS_TIMES.get(key);if (diff >= 0) {try {MsgProducerUtils.send(body.getTopic(), body.getPartitionNum(), body.getRealPayLoad());} catch (IllegalArgumentException e) {logger.error("producer params illegal. key:{},body:{},e:", key, body, e);}connector.commitOffsets();} else {schedulerExecutor.schedule(new Runnable() {public void run() {processHandler(key, body, connector);}}, -diff, TimeUnit.MILLISECONDS);}}
基于定时消息的定时任务总体设计
定时任务,实际上是基于定时消息封装的client客户端。业务方,引入对应的jar包后,调用相关的方法,就可以完成对某个类的某个方法进行调用。
由于定时任务主要是对调用方屏蔽掉使用生产kafka定时消息以及消费kafka消息带来的额外学习成本,因此,其主要提供两个方面的功能,produce 和 consume kafka消息。
基于定时消息的定时任务整体交互流程如下:
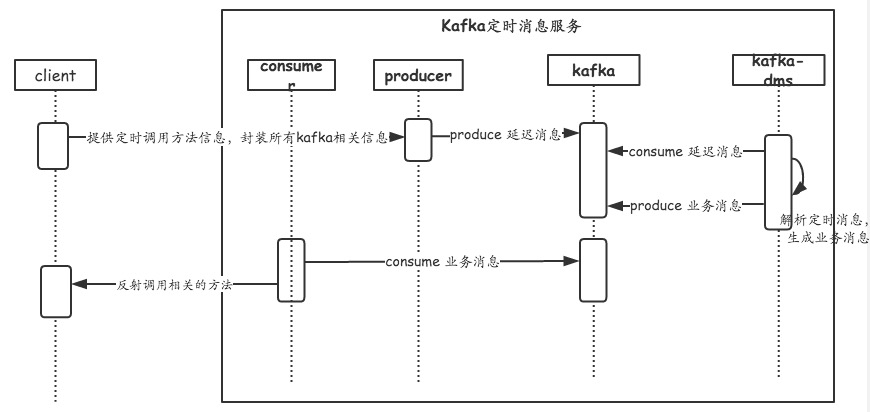
从交互图可以显然的看到,我们在client内定义了一个调用方法相关的数据结构,业务代码将该数据结构交给client,client根据该数据结构,构建topic,发送到kafka-dms服务上;然后client 根据业务配置的project.topic 来pull消息,反射执行方法,完成定时任务调用。
基于定时消息的定时任务具体设计与关键实现
定时任务client实现,其实质就是根据业务级别来封装处理kafka消息。一般的,对于这种需求,显然需要配置的kafka相关设置越少越好,因此为了使用简便,对于很多功能都省去。
Broker 获取和 partitioner 获取
一般,对于producer使用中,需要设置broker list来告知kafka的服务地址。在client中,我们不希望业务方去了解设置这些。因此,需要通过代码获取broker地址。由于kafka的获取是scala实现,因此,这里首先使用java来重写,对java来进行调用。
同样,对于分区逻辑,业务方也不会关心(如果想保证先后顺序,即在一个分区内,可以通过数据结构的key来实现),业务需要根据topic去获取对应的实际分区数来达到分区效果。对于分区,kafka定时消息是根据业务方的key直接push到对应的业务消息分区的。
获取broker实现如下:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108
public class KafkaZkUtils {private static final Logger logger = LoggerFactory.getLogger(KafkaZkUtils.class);private static final String BrokerIdsPath = "/brokers/ids";private static final String BrokerTopicsPath = "/brokers/topics";private static final String TopicConfigPath = "/config/topics";private static final String DeleteTopicsPath = "/admin/delete_topics";public static String getTopicPath(String topic) {return BrokerTopicsPath + "/" + topic;}public static String getTopicPartitionsPath(String topic) {return getTopicPath(topic) + "/partitions";}/*** 获取topic 分区. 由于构造CuratorFramework 成功很大,所以请缓存结果,或者使用下面的方法来获取** @param zkAddress* @param topic* @return*/public static List<String> getPartitionsForTopic(String zkAddress, String topic) {CuratorFramework client = CuratorFrameworkFactory.newClient(zkAddress, 6000, 6000, new RetryForever(1000));try {client.start();return getPartitionsForTopic(client, topic);} finally {client.close();}}public static List<String> getBrokers(String zkAddress) {CuratorFramework client = CuratorFrameworkFactory.newClient(zkAddress, 6000, 6000, new RetryForever(1000));try {client.start();return getBrokers(client);} finally {client.close();}}/*** 获取某个指定topic 的分区情况.** @param zkClient 已经start,并且close由其关闭* @param topic* @return*/public static List<String> getPartitionsForTopic(CuratorFramework zkClient, String topic) {try {return zkClient.getChildren().forPath(getTopicPartitionsPath(topic));} catch (Exception e) {logger.error("getPartitionsForTopic error.topic:{}, e:", topic, e);return null;}}/*** 简单需求的时候,可以使用,对应broker,一般使用zk的watch保存监听比较好** @param zkClient* @return*/public static List<String> getBrokers(CuratorFramework zkClient) {try {List<String> brokerIds = zkClient.getChildren().forPath(BrokerIdsPath);if (brokerIds == null || brokerIds.isEmpty()) {return null;}List<String> brokerHostInfo = Lists.newArrayList();for (String id : brokerIds) {String info = new String(zkClient.getData().forPath(BrokerIdsPath + "/" + id));Map<String, Object> data = JsonUtils.decode(info, Map.class);brokerHostInfo.add(data.get("host") + ":" + data.get("port"));}return brokerHostInfo;} catch (Exception e) {logger.error("getBrokers error. e:", e);return null;}}}
client 调用业务接口
在业务调用接口的时候,它需要把定时任务执行的方法和相关参数序列化,然后client pull到消息后,将这些信息通过反射机制来执行。
首先看一下,业务调用异步任务接口时,需要提供的数据结构:
1234567891011121314151617
public class DelayedTaskProperty implements Serializable {private static final long serialVersionUID = 6227226019751603874L;private String classFullName;private String methodName;private Object[] args;/*** 路由规则的key,如果不设置,则随机路由到不同的分区*/private int routeKey;}
然后根据上面数据结构的信息,client的consumer端就可以来执行相应的方法了:
12345678910111213141516171819202122232425262728293031323334353637
/*** 处理的核心逻辑,反射方式调用方法** @param property* @param connector*/private void processHandler(DelayedTaskProperty property, ConsumerConnector connector) {Class clazz = CLASS_MAP.get(property.getClassFullName());if (clazz == null) {synchronized (LOCK) {try {clazz = ClassUtils.getClass(property.getClassFullName());} catch (ClassNotFoundException e) {logger.error("class reflect error.class:{} not find.e:", property.getClassFullName(), e);connector.commitOffsets();return;}CLASS_MAP.putIfAbsent(property.getClassFullName(), clazz);}}// FIXME: 16/1/2 这里的异常等处理后续需要细化,确保有些额外异常不进行commit?try {Object target = clazz.newInstance();Reflection.invokeN(clazz, property.getMethodName(), target, property.getArgs());} catch (Exception e) {logger.error("e:", e);} finally {connector.commitOffsets();}}
遗留问题和总结
显然,这个基于kafka消息队列的定时消息,还可以完成其他一些需求。
目前的设计,还处在使用kafka完成我们需要的定时消息的功能,以及基于此的定时任务;其性能和设计上的优化,还有很多进步的空间,代码还没有进行优化和统一等等。
此外,对于client的使用,显然需要封装成jar包,然后给业务方引入。
- Kafka的定时消息/任务服务
- 消息系统定时任务的实现
- apache kafka消息服务
- apache kafka消息服务
- kafka 消息服务
- 定时发送消息任务
- 消息推送,定时任务
- 定时任务服务
- 服务的应用-后台执行的定时任务
- python定时任务windows服务
- 短信消息通知服务-spring定时计划任务quartz(一)
- 短信消息通知服务-spring定时计划任务quartz(二)
- 非root用户 如何创建linux 服务的定时任务
- 【Linux】Cron服务,定时任务的设置和详解
- linux的定时任务crond(crontab)服务
- JEESZ-kafka消息服务平台实现
- JEESZ-kafka消息服务平台实现
- Celery消息队列----配置定时任务
- 详细介绍Spring Data JPA
- CSS绘制简单图形
- ArrayList简单的源码分析
- 命名实体识别的两种方法
- Android改变图片属性之饱和度
- Kafka的定时消息/任务服务
- 单缓冲和双缓冲的时间计算
- 分页封装类
- 我的博客即将入驻“云栖社区”,诚邀技术同仁一同入驻。
- PageHelper集成SpringBoot
- 工具
- 树形DP初步(2)补充例题
- 合理分析竞争对手,有效提升关键词排名
- 隐藏android中EditText中的下划线


