Burpsuite中protobuf数据流的解析
来源:互联网 发布:怎么抓取网页数据 编辑:程序博客网 时间:2024/05/21 15:46
0×00 前言
对于protobuf over-HTTP的数据交互方式Burpsuite不能正确的解析其中的数据结构,需要Burpsuite扩展才能解析,笔者使用mwielgoszewski的burp-protobuf-decoder【1】扩展实践了protobuf数据流的解析,供有需要的同学学习交流。笔者实践使用的环境: burpsuite+python2.7+protobuf2.5.0。
0×01 安装burp-protobuf-decoder扩展
burp-protobuf-decoder【1】扩展是基于protobuf库(2.5.x版本)开发的burpsuite python扩展,可用于解析、篡改 request/response中protobuf数据流。从https://github.com/mwielgoszewski/burp-protobuf-decoder下载该扩展源码,然后解压。
该扩展是基于protobuf和jython实现的。先下载protobuf 2.5.0【2】源码进行编译,编译方法请参考其README.txt文件。需求在burpsuite的Extender中配置Jython【3】的路径:

Burpsuite中添加扩展:
在Burpsuite的Extender窗口中点击“Add”按钮,弹出的“Load Burp Extension”窗口中选择如下信息:
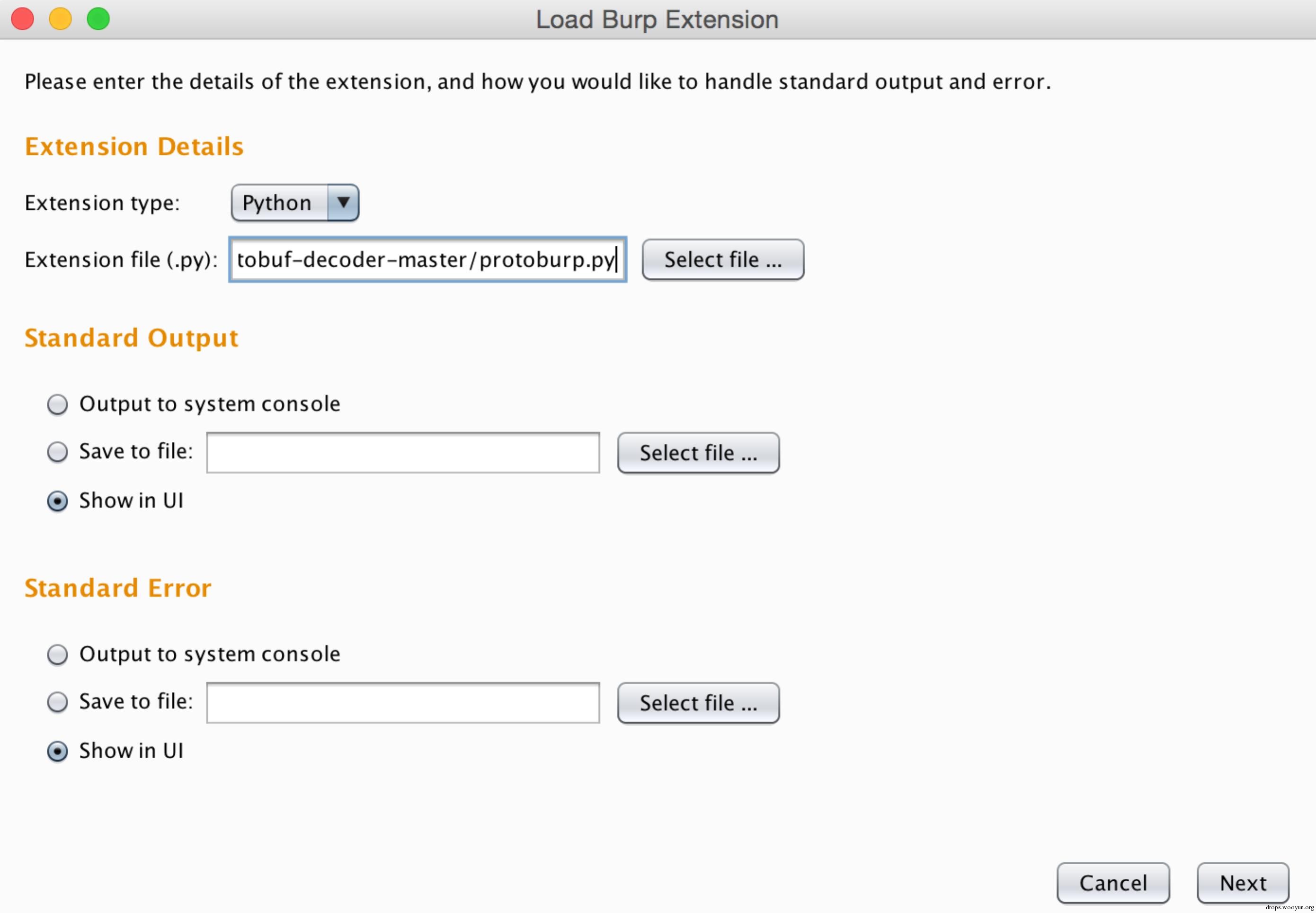
然后Next,当看到如下信息时表示扩展加载成功:
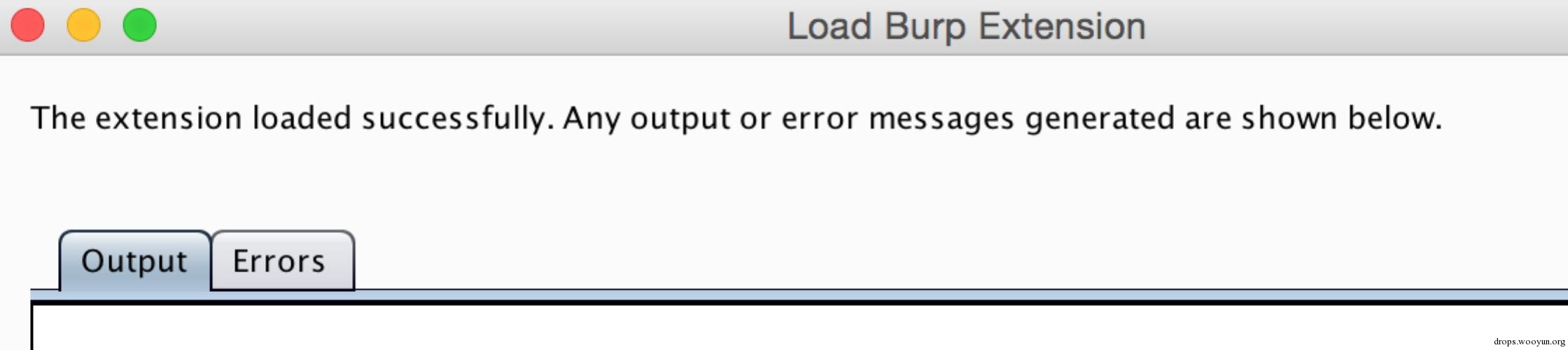
Tips:
加载扩展时提示
“Error calling protoc: Cannot run program "protoc" (in directory "******"): error=2, No such file or directory”错误解决办法:修改protoburp.py中调用protoc命令的路径,有多处,如:
将
process = subprocess.Popen(['protoc', '--version']中'protoc'改为'/home/name/protobuf/src/protoc'。加载扩展碰到
cannot import name symbol_database错误可能是你使用的protoc与扩展所使用protobuf python库版本不一致原因,一种解决办法是下载protobuf 2.5.0源码编译后,修改protoburp.py中对应的路径,再加载扩展。
扩展加载成功了,但不能解析protobuf数据流
该扩展通过判断头部“content-type”是否为“
'application/x-protobuf'”来决定是否解析数据,你可以修改protoburp.py中的isEnabled()方法让其工作。
0×02 protobuf简介
protobuf是Google开源的一个跨平台的结构化数据存储格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
protobuf通过定义“.proto”文件来描述数据的结构。.proto文件中用 “Message”来表示所需要序列化的数据的格式。Message由Field组成,Field类似Java或C++中成员变量,通常一个Field的定义包含修饰符、类型、名称和ID。下面看一个简单的.proto文件的例子:
#!cppsyntax = "proto2";package tutorial;message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4;}message AddressBook { repeated Person person = 1;}使用下面的python代码生成二进制数据流:
#!pythonimport addressbook_pb2address_book = addressbook_pb2.AddressBook()person = address_book.person.add()person.id = 9person.name = 'Vincent'person.email = 'Vincent@test.com'phone = person.phone.add()phone.number = '15011111111'phone.type = 2f = open('testAb', "wb")f.write(address_book.SerializeToString())f.close()序列化后的二进制数据流如下:

有关Protobuf的语法网上已有很多文章了,你可以网上搜索或参考其官网【4】说明。
2.1Varint编码
Protobuf的二进制使用Varint编码。Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010。
下图演示了protobuf如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为protobuf 字节序采用 little-endian 的方式。
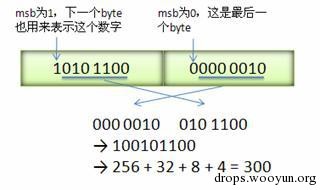 (图片来自网络)
(图片来自网络)
2.2数值类型
Protobuf经序列化后以二进制数据流形式存储,这个数据流是一系列key-Value对。Key用来标识具体的Field,在解包的时候,Protobuf根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 Field。
Key 的定义如下:
(field_number << 3) | wire_type
Key由两部分组成。第一部分是 field_number,比如消息 tutorial .Person中 field name 的 field_number 为 1。第二部分为 wire_type。表示 Value 的传输类型。Wire Type 可能的类型如下表所示:
以数据流:08 96 01为例分析计算key-value的值:
#!bash08 = 0000 1000b => 000 1000b(去掉最高位) => field_num = 0001b(中间4位), type = 000(后3位) => field_num = 1, type = 0(即Varint)96 01 = 1001 0110 0000 0001b => 001 0110 0000 0001b(去掉最高位) => 1 001 0110b(因为是little-endian) => 128+16+4+2=150最后得到的结构化数据为:
1:150
其中1表示为field_num,150为value。
2.3手动反序列化

以上面例子中序列化后的二进制数据流进行反序列化分析:
#!bash0A = 0000 1010b => field_num=1, type=2;2E = 0010 1110b => value=46;0A = 0000 1010b => field_num=1, type=2;07 = 0000 0111b => value=7;读取7个字符“Vincent”;
#!bash10 = 0001 0000 => field_num=2, type=0;09 = 0000 1001 => value=9;1A = 0001 1010 => field_num=3, type=2;10 = 0001 0000 => value=16;读å–10个å—符“Vincent@test.comâ€;
#!bash22 = 0010 0010 => field_num=4, type=2;0F = 0000 1111 => value=15;0A = 0000 1010 => field_num=1, type=2;0B = 0000 1011 => value=11;读取11个字符“15011111111”;
#!bash10 = 0001 0000 => field_num=2, type=0;02 = 0000 0010 => value=2;最后得到的结构化数据为:
#!bash1 { 1: "Vincent" 2: 9 3: "Vincent@test.com" 4 { 1: "15011111111" 2: 2 }}手工反序列化最大难点是类型2,这个类型有的时候代表字符串,有的时候代表子元素,什么时候代表字符串什么时候代表子元素从已经经序列化的流里面不好分析(在没有.proto文件的情况下),有的时候会混乱,推测远原程序decode_raw是先测试下类型2下面的内容是否可以被解析为protobuf的子结构,如果可以则解析,如果不可以则解析为字符串,由此造成解析的不稳定性。(红字标注的是自己的想法,并非原作者的话,正确性有待讨论)2.4使用protoc反序列化
实现操作经常碰到较复杂、较长的流数据,手动分析确实麻烦,好在protoc加“decode_raw”参数可以解流数据,我实现了一个python脚本供使用:
#!pythondef decode(data): process = subprocess.Popen(['/usr/local/bin/protoc', '--decode_raw'], stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE) output = error = None try: output, error = process.communicate(data) except OSError: pass finally: if process.poll() != 0: process.wait() return outputf = open(sys.argv[1], "rb")data = f.read()print 'data:\n',decode(data)f.close()使用python decode.py <proto.bin>即可反序列化,其中proto.bin为protobuf二进制数据流文件。得到结构化的数据后我们可以逐步分析,猜测每个Field的名称,辅助协议、数据结构等逆向分析。
0×03 burpsuite+protobuf实战
用webpy模拟protobuf over-HTTP的web app。
服务端overHttp_server.py内容如下:
#!python#!/usr/bin/env python#coding: utf8#author: Vincentimport webimport timeimport osurls = ( "/", "default", )app = web.application(urls, globals())class default: def GET(self): return 'hello world.' def POST(self): reqdata = web.data() print 'client request:'+reqdata resdata = reqdata.split(':')[-1] web.header('Content-type', 'application/x-protobuf') return resdataif __name__ == "__main__":app.run()客户端overHttp_client.py内容如下:
#!python#!/usr/bin/env python#coding: utf8#author: Vincentimport urllibimport urllib2import jsonimport addressbook_pb2import sysproxy = 'http://<ip>:8888'target = "http://<ip>:8080/"enable_proxy = True proxy_handler = urllib2.ProxyHandler({"http" : proxy}) null_proxy_handler = urllib2.ProxyHandler({}) if enable_proxy: opener = urllib2.build_opener(proxy_handler) else: opener = urllib2.build_opener(null_proxy_handler) urllib2.install_opener(opener)def doPostReq(): url = target address_book = addressbook_pb2.AddressBook() f = open('testAb', "rb") address_book.ParseFromString(f.read()) ad_serial = address_book.SerializeToString() f.close() data = ad_serial opener = urllib2.build_opener(proxy_handler, urllib2.HTTPCookieProcessor()) req = urllib2.Request(url, data, headers={'Content-Type': 'application/x-protobuf'}) response = opener.open(req) return response.read()resp = doPostReq()print 'response:',resp3.1proto文件逆向分析
启动服务端:python overHttp_server.py <ip>:8080
客户端请求:python overHttp_client.py
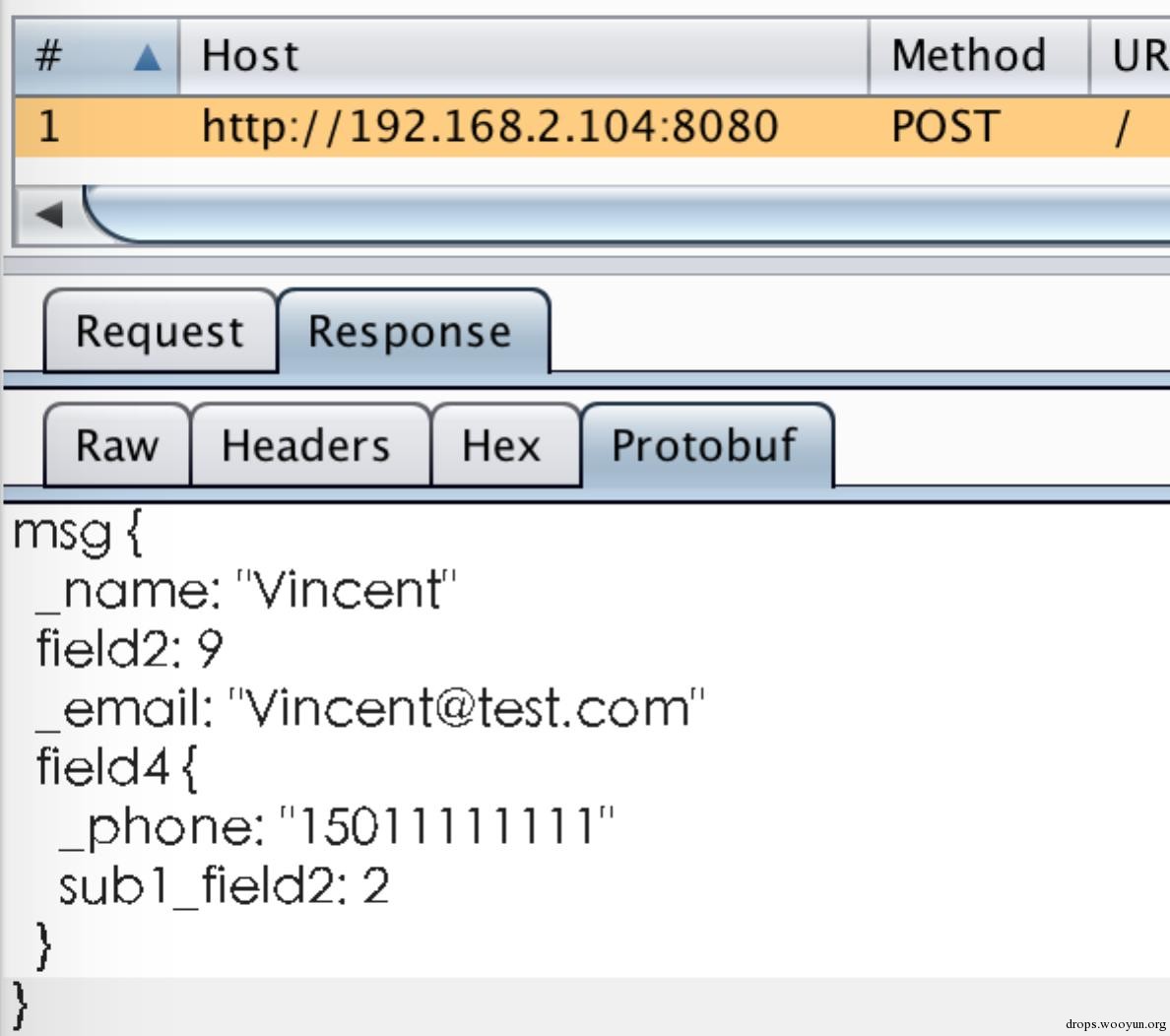
此时burp中已解析出protobuf数据,如下图:
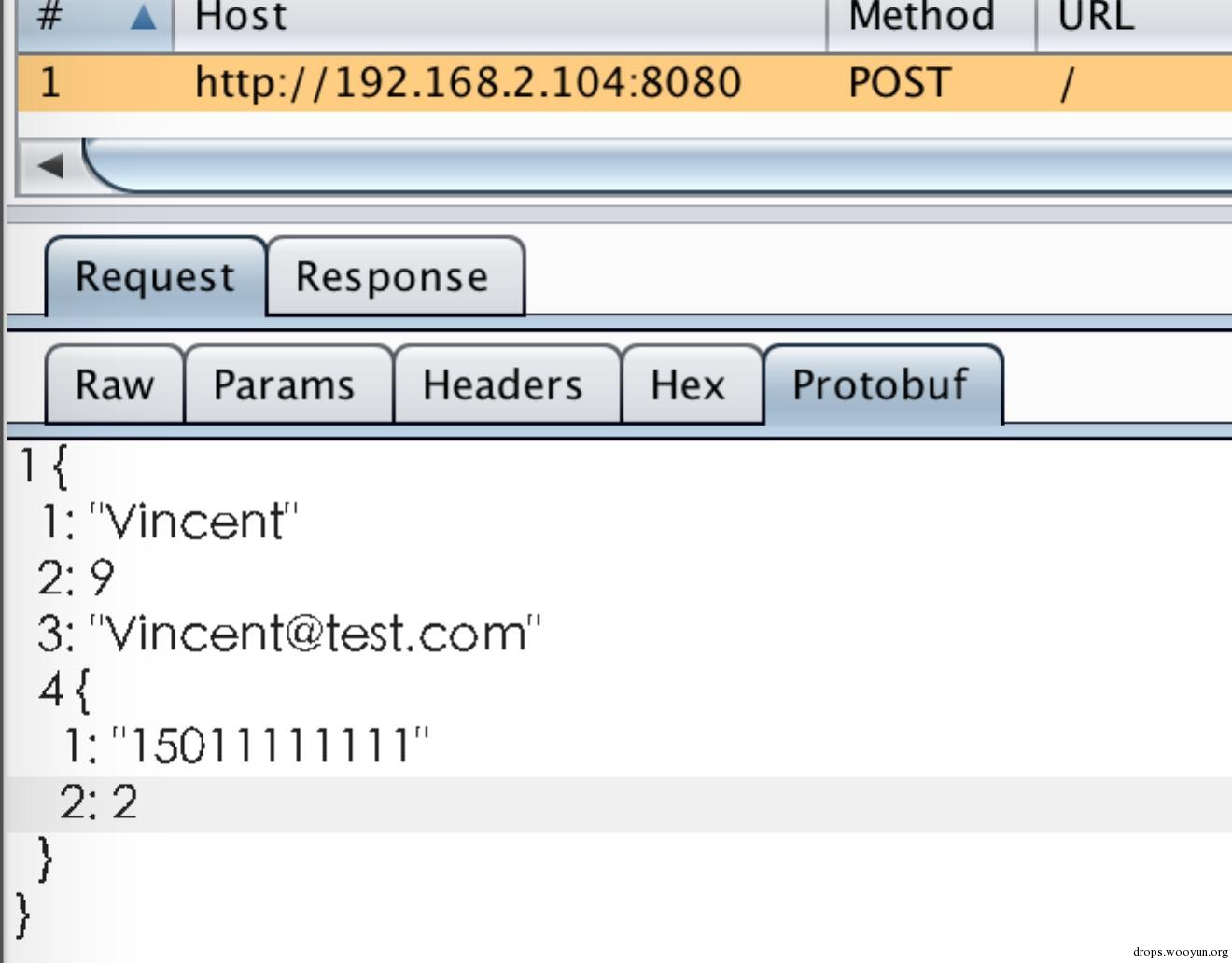
但是这个结构的可读性还是比较差,我们可以通过逆向分析逐步猜测字段名称、类型,然后再解析,方便实现协议的逆向、安全测试等。
对这个结构我们可以还原成以下proto文件:
#!cppsyntax = "proto2";package reversed.proto1;message Msg { optional string _name = 1; optional int32 field2 = 2; optional string _email = 3; message subMsg1 { required string _phone = 1; optional int32 sub1_field2 = 2; } repeated subMsg1 field4 = 4;}message Root { repeated Msg msg = 1;}然后使用右键的“Load .proto”加载该文件:
再看解析结果:
3.2数据篡改
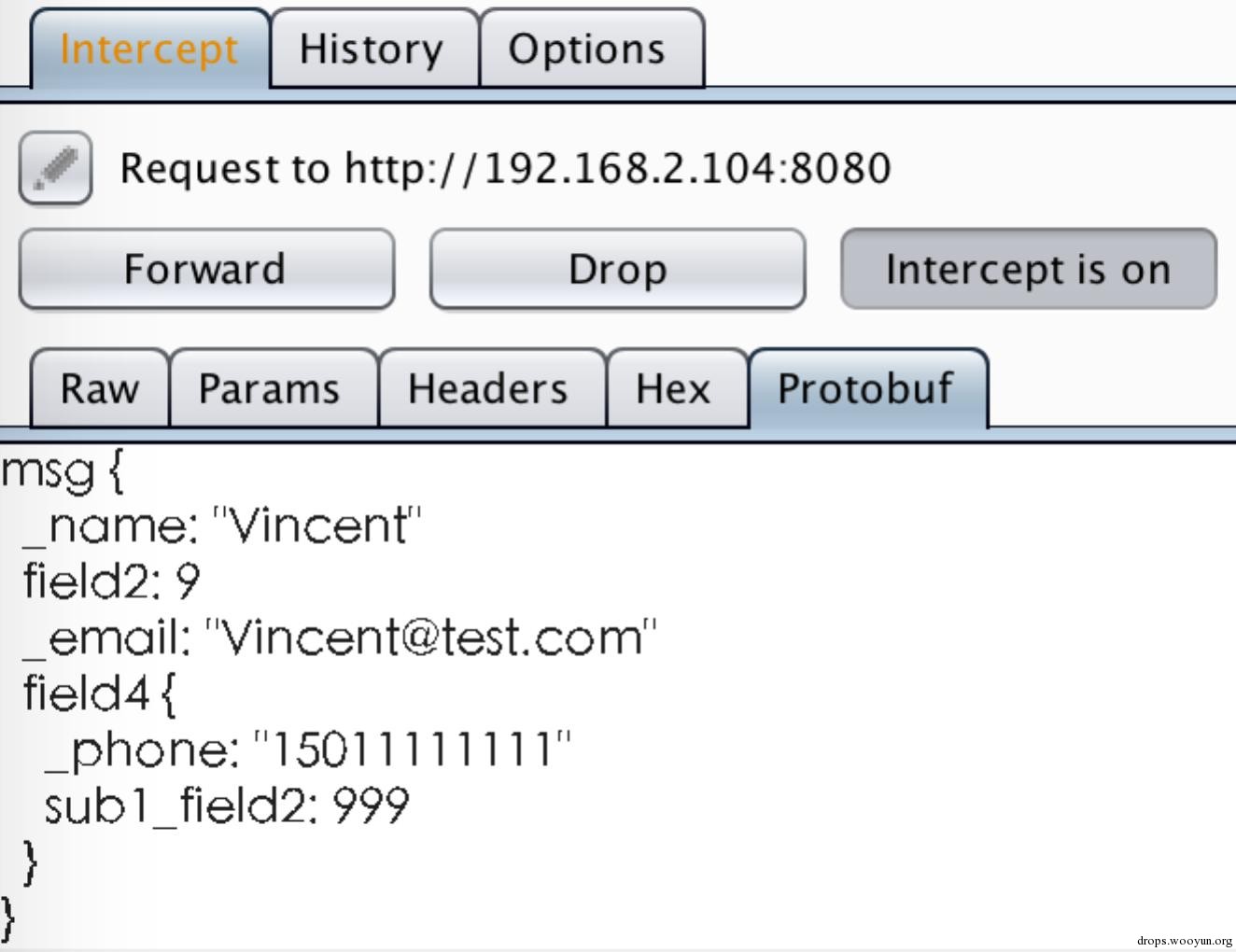
打开request拦截:

运行python overHttp_client.py发送请求。拦截到request后,把sub1_field2改为999。
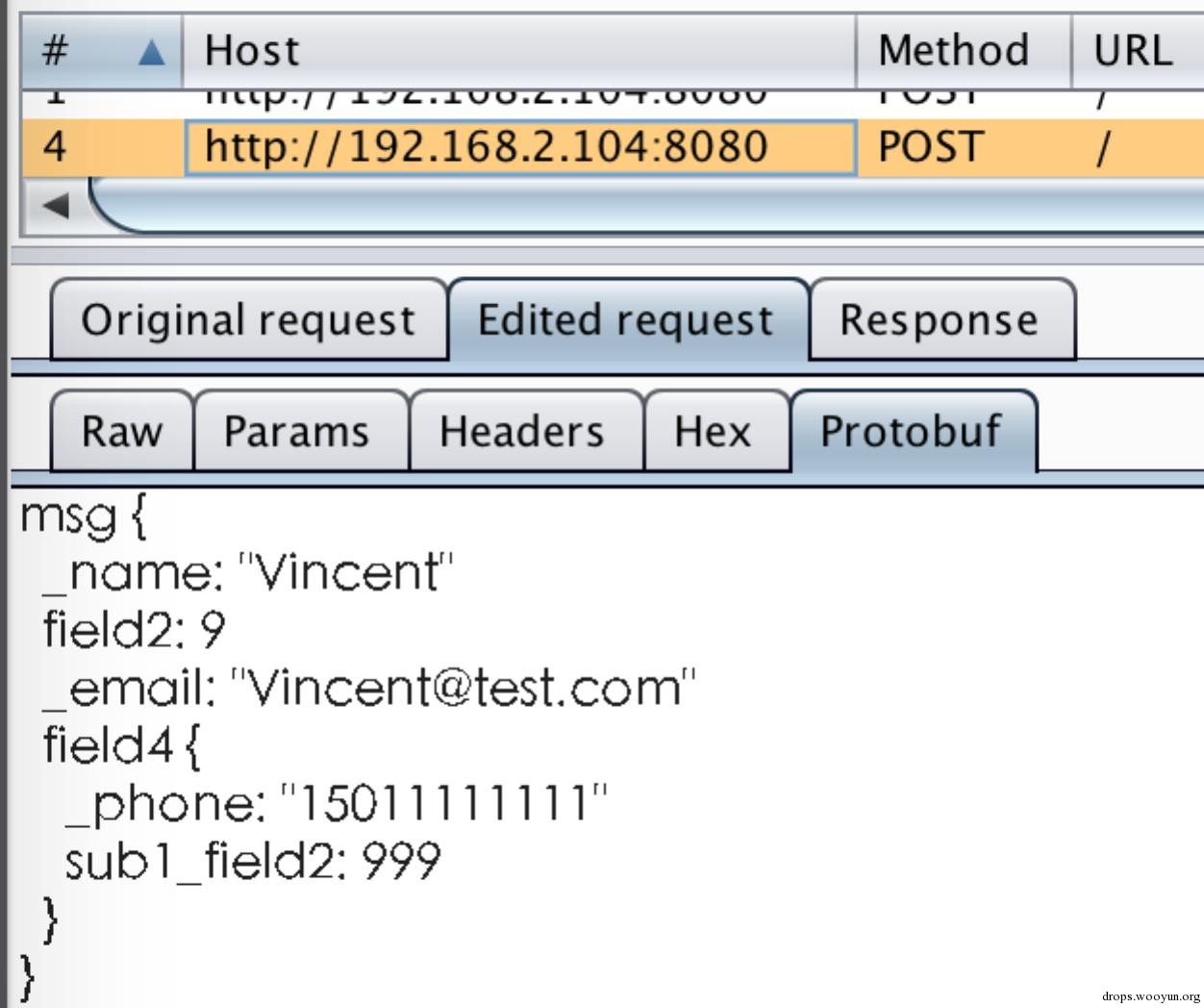
“Forward”后看request数据,已被篡改:
0×04 参考
- 【1】https://github.com/mwielgoszewski/burp-protobuf-decoder
- 【2】https://github.com/google/protobuf/tree/v2.5.0
- 【3】https://wiki.python.org/jython/InstallationInstructions
- 【4】https://developers.google.com/protocol-buffers/docs/proto
- 【5】https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
- 【6】https://developers.google.com/protocol-buffers/docs/overview
- 【7】http://www.tssci-security.com/archives/2013/05/30/decoding-and-tampering-protobuf-serialized-messages-in-burp/
- Burpsuite中protobuf数据流的解析
- Burpsuite中protobuf数据流的解析
- 经验分享 | Burpsuite中宏的使用
- 在quick cocos2dx中增加解析protobuf的扩展
- cocos creator: js中实现protobuf的打包和解析
- 如何解析超长的protobuf
- Burpsuite视频教程(更新中)
- 解析protobuf
- burpsuite的字体设置
- Burpsuite的简单配置
- Hadoop 中MapReduce的数据流
- protobuf的ParseFromArray 解析失败的问题
- Unity中protobuf的使用方法
- Unity中protobuf的使用方法
- Unity中protobuf的使用方法
- 用JS解析file数据流的问题
- 接口中数据流的格式发送请求和解析流请求
- Burpsuite
- 强制获取焦点
- git add;遇到 LF will be replaced by CRLF in .....
- apache.commons.lang的EqualsBuilder和HashCodeBuilder用法
- Echarts插件使用
- 动态规划——地铁里的间谍
- Burpsuite中protobuf数据流的解析
- 插入排序
- Delphi执行SQL提示“不正常地定义参数对象”,“提供了不一致或不完整的信息”错误
- rman 在线复制
- 第十篇 编写一个简单的注册页面
- matplotlib如何改变legend的字号
- Spring之注入类型(DI:dependency injection)
- HDU 3952(计算几何)
- protobuf流的反解析Message


