【技术解密】SequoiaDB复制组选举原理说明
来源:互联网 发布:mac系统最大化快捷键 编辑:程序博客网 时间:2024/05/16 02:07
1、SequoiaDB介绍
SequoiaDB是国内一款自主研发的分布式文档型数据库。它与过去开发者所熟悉的关系型数据库不同,它的数据结构是BSON类型,一种与JSON结构非常相近的数据类型。
SequoiaDB与关系型数据库除了在数据类型上有比较明显的差异外,还原生支持分布式存储。用户在搭建一个能够应对海量数据以及包含高并发操作的系统时,不再需要像过去一样,在业务层面做复杂的分表分库工作,直接在定义数据表时,明确告诉数据库此表需要根据哪个字段以及何种规则进行分布式存储,数据分布式存储对于用户来说变得透明。用户可以更加专注以业务逻辑开发,而不是关注如何分表分库。
2、SequoiaDB总体架构介绍

SequoiaDB 总体架构示意图
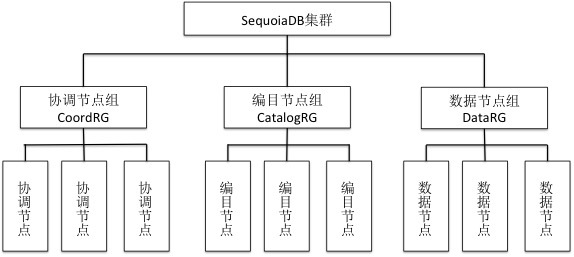
SequoiaDB整个集群中,主要角色构成是三个,协调节点,编目节点和数据节点。
1.协调节点
协调节点(英文称呼为Coord),是SequoiaDB的任务分发节点(一般用户成为Master节点),本身不存储任何数据,主要负责接收应用程序的访问请求。所以一般用户在与SequoiaDB打交道时,访问的都是协调节点,对于其他角色的节点,一般情况下是不建议用户去访问的。
在SequoiaDB老版本中,协调节点在数据库集群中是类似孤岛式部署的。怎么说呢,主要因为在老版本中,每个协调节点就是通过一个catalogaddr参数了解编目节点信息,协调节点之间没有任何的通讯方式,而且在编目节点中也不存储任何协调节点信息。
但是在新的版本中,协调节点已经找到了组织,称之为CoordRG。整个数据库集群中,所有的协调节点都属于CoordRG,并且该信息被保存在CatalogRG上。
2.编目节点
编目节点(英文称呼为Catalog),主要负责存储整个数据库的部署结构,节点状态信息,并且记录集合空间与集合的参数信息,还有集合中的索引信息以及主子表信息。同时编目节点还记录每个集合的数据切分状况,承担的功能与关系型数据库的Metastore类似。
编目节点属于编目节点组(CatalogRG)。在数据库集群中,肯定并且只能拥有一个编目节点组(CatalogRG),一个编目节点组中至少拥有一个编目节点,最多拥有7个编目节点。
3.数据节点
数据节点,负责数据存储、任务计算的工作,并且像索引的建立,数据备份与事务功能的提供,都是由数据节点负责。
数据节点是属于数据组(DataRG)的。在SequoiaDB集群中,至少拥有一个数据组,每个数据组中又至少包含一个数据节点。一个数据组中,最多可以拥有7个数据节点。SequoiaDB对数据组的数量没有明确的限制,用户可以根据自己服务器的多少进行对应的部署、配置。
4.SequoiaDB角色节点逻辑展示
3、SequoiaDB复制组?数据组?
在SequoiaDB中,由于有三种主要的角色组,所以很多的用户在理解SequoiaDB的概念时,会生产混淆。
在SequoiaDB中,一般统称编目节点组与数据组为复制组,但是由于编目组实在太少被用户所接触,所以逐渐地用户也将复制组与数据组划上了等号。
数据组,则是专指由数据节点构成的DataRG,它是用户在对集合做数据切分时最小的切分单位。数据组在数据库中没有明确的数量限制。
选举是什么
这里所说的选举,并非通常人们所理解的选总统,选美女,而是在一个大型的分布式环境下,根据选举算法选择一个进程作为该组的主节点。通常在分布式环境下,会有主节点和从节点两种角色,主节点的权限最高,能够执行任何的增删查改操作,而从节点的数据则是要求保证与主节点保持同步,从节点通常只为系统提供读服务,但在一些要求严格的场景下,从节点甚至只做数据备份使用。
一些用户可能会好奇,为什么在分布式环境下,需要区分主、从节点呢,大家都一视同仁不是最理想状态吗?
但是大家是否在分布式环境下,存储的方式已经和过去数据集中存储不同,数据是存储在多台服务器上,在网络良好的情况下,各个节点能够正常通信,像每个节点都能够完成数据写入和删除操作,理论上是没有任何问题的,但是一旦发生网络断开,如果继续让每个节点都能够继续负责数据写入和删除,就会发生数据不一致现象。
例如在一个银行场景里,用户A卡里只有100元,他通过应用A消费了100元,但是由于应用A只能够访问节点A和节点B,节点C是不知道卡里已经少了100元,所以他从应用B查找余额时发现,卡里钱没有发生变化,他还能通过应用B继续消费额外100元。
所以用户通过这个例子就明白,为什么在一个分布式环境下,节点的角色需要存在区分,就是为了保证数据的安全性。

用户在明确一个组内需要区分节点角色后,那样就会产生另外一个疑问,组内应该在何种时候发起选举,发起选举是否存在门槛。
在SequoiaDB中,当一个复制组内已经存在了主节点时,数据库不会主动发起新一轮选举,但是用户可以通过强行切换主节点的命令要求数据组发起新一轮选举,从而产生新的主节点。
另外,在复制组发起选举前,会要求组内存活的节点数必须大于(组内总节点数/2+1),既当前组内可以参与选举的节点数必须超过半数,选举才会有效。这个限制又是什么呢?
大家试想以下,如果一个复制组内拥有四个节点,如果选举的规则不是要求超过半数而是满足半数即可,会有什么影响呢。当一个系统的网络环境突然发生异常时,假设系统两边各存在两个节点,由于网络不同,所以两变的节点都认为其余两个节点的进程已经退出,但是由于存活节点数满足总节点的半数,就能够选举新的主节点,那样在网络两边,会同时产生两个主节点。
刚才作者已经向用户介绍了如果发生网络两边都能够执行数据写入和删除,会在某些场景下发生数据不一致的情况,此时同时一样。这种情况在数据库中称之为“脑裂”。

数据库“脑裂”的情况应该是每个数据库开发者所极力避免的。
所以在分布式数据库中,选举制度的产生,是为了让用户在使用分布式环境操作数据时,保证数据一致性的重要举措。
SequoiaDB选举原理
在SequoiaDB数据库中涉及到选举的,就是编目节点组与数据节点组。两种角色组的选举机制与原理一致,为了让用户更加细致的了解,作者将以数据组为例,给大家讲解SequoiaDB的选举原理。
在SequoiaDB的选举中,有几个重要的准则:
准则1
数据组内如果已经存在了主节点,则其他从节点无法要求组内发起新一轮选举;
准则2
数据组内要进行选举,必须满足存活节点>=(组内总节点数/2+1)要求,才能够发起选举;
准则3
在数据组内,节点竞争当选主节点,有几个优先考虑,优先级从高到低排列如下:节点LSN>节点选举权重>节点NodeID
准则4
数据组内进行选举,遵循二段提交原则,保证选举的正确性
选举场景模拟
基于上文介绍的选举机制,我们也列出了一些常见的一些节点选举场景情况的模拟。
“假设数据组包含三个数据节点,A节点(主节点,NodeID=1000,weight=10)、B节点(NodeID=1001,weight=10)和C节点(NodeID=1002,weight=10),且在开始时磁盘、网络等客观资源都是充裕的。
如果有一个场景,当数据组的主节点(A节点)接收到写入数据请求后,主节点刚刚完成数据的写入操作,但是还没有来得及将此写入任务同步到B节点和C节点。由于外力因素,A节点的进程突然被强行关闭,那么此时该数据组中哪个节点会当选主节点?
如果有一个场景,当数据组的主节点(A节点)接收到写入数据请求后,主节点在完成数据的写入操作后,刚刚将写任务同步到B节点,但是还没有来得及将此写入任务同步到C节点上。由于外力因素,A节点的进程突然被强行关闭,那么此时该数据组中哪个节点会当选主节点?”
4、总结
在本文中,作者给使用SequoiaDB的用户介绍了数据库的基本架构以及在此架构中,数据库的选举原理,并且通过介绍多个模拟场景让用户能够更加直观地了解SequoiaDB复制组的选举机制。
SequoiaDB的选举机制比较特别,节点选主节点受节点的LSN、节点权重和NodeID三者混合影响,并且很多用户所猜想的随机选择,而是有规律的进行选举。用户了解SequoiaDB这些运行原理,就能够在使用SequoiaDB和运维SequoiaDB更加有把握,并且在数据库集群发生异常时,能够更加有针对性的定位问题,提出解决方案。
产品特性
解决方案与案例
数据库下载
技术文档
微信客服:
sequoiadb111

产品特性
解决方案与案例
数据库下载
技术文档
微信客服:
sequoiadb111
- 【技术解密】SequoiaDB复制组选举原理说明
- 【技术解密】SequoiaDB分布式存储原理
- 【技术解密】SequoiaDB分布式存储原理
- 【技术教程】SequoiaDB对接Kafka
- ZooKeeper 工作、选举 原理
- zookeeper选举原理讲解
- zookeeper选举原理
- SequoiaDB
- SequoiaDB版本在线升级介绍说明
- SequoiaDB版本在线升级介绍说明
- 【技术详解】SequoiaDB数据分区简介
- 【技术教程】MySQL to SequoiaDB数据迁移
- zookeeper核心原理(选举)
- kafka leader选举机制原理
- zookeeper原理(选举,应用)
- zookeeper核心原理(选举)
- 四种主流复制技术介绍,复制原理,优缺点分析
- 四种主流复制技术介绍,复制原理,优缺点分析
- String to Integer (atoi)---题解
- opencv3.0中的无缝克隆图像——seamless_cloning(Poisson Image Editing)
- 捕获异常消息Ctrl+C
- ANSI转UTF-8
- c# winform 添加dataGridView数据源
- 【技术解密】SequoiaDB复制组选举原理说明
- 用两个stack实现queue
- B
- 做Java编程开发需要具备哪些软实力
- HTTP数据抓包(Fiddler2) V2.2.0 绿色中文版 和 教程网址:fiddler2抓包工具使用图文教程
- 杂记数据库
- 如何通过思维导图进行计划安排的6种模板鉴赏
- xml的通讯录系统
- java保留两位小数4种方法


