order by、group by、distinct、having、group_concat、concat
来源:互联网 发布:淘宝怎么交保证金 编辑:程序博客网 时间:2024/05/23 17:59
select
from
where
group by
order by
注意:group by 比order by先执行,order by不会对group by 内部进行排序,如果group by后只有一条记录,那么order by 将无效。要查出group by中最大的或最小的某一字段使用 max或min函数。
例:
select sum(click_num) as totalnum,max(update_time) as update_time,count(*) as totalarticle from article_detail where userid =1 group by userid order by update_time desc
order by 从英文里理解就是行的排序方式,默认的为升序。 order by 后面必须列出排序的字段名,可以是多个字段名。
group by 从英文里理解就是分组。必须有“聚合函数”来配合才能使用,使用时至少需要一个分组标志字段。
什么是“聚合函数”?
像sum()、count()、avg()等都是“聚合函数”
使用group by 的目的就是要将数据分类汇总。
一般如:
select 单位名称,count(职工id),sum(职工工资) form [某表]
group by 单位名称
这样的运行结果就是以“单位名称”为分类标志统计各单位的职工人数和工资总额。
在sql命令格式使用的先后顺序上,group by 先于 order by。
select 命令的标准格式如下:
SELECT select_list
[ INTO new_table ]
FROM table_source
[ WHERE search_condition ]
[ GROUP BY group_by_expression ]
[ HAVING search_condition ]
1. GROUP BY 是分组查询, 一般 GROUP BY 是和聚合函数配合使用
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面(重要)
例如,有如下数据库表:
A B
1 abc
1 bcd
1 asdfg
如果有如下查询语句(该语句是错误的,配合聚合函数使用)
select A,B from table group by A
该查询语句的意图是想得到如下结果(当然只是一相情愿)
A B
abc
1 bcd
asdfg
右边3条如何变成一条,所以需要用到聚合函数,如下(下面是正确的写法):
select A,count(B) as 数量 from table group by A
这样的结果就是
A 数量
1 3
2. Having (对分组后的数据进行筛选,where是分组前)
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
having 子句被限制子已经在SELECT语句中定义的列和聚合表达式上。通常,你需要通过在HAVING子句中重复聚合函数表达式来引用聚合值,就如你在SELECT语句中做的那样。例如:
SELECT A COUNT(B) FROM TABLE GROUP BY A HAVING COUNT(B)>2
这种需求,我想很多人都遇到过。下面是我模拟我的内容表
CREATE TABLE `test` (
`id` INT(10) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL,
`category_id` INT(10) NOT NULL,
`date` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
ENGINE=MyISAM
ROW_FORMAT=DEFAULT;
INSERT INTO `test` (`id`, `name`, `category_id`, `date`)
VALUES
(1, 'aaa', 1, '2010-06-10 19:14:37'),
(2, 'bbb', 2, '2010-06-10 19:14:55'),
(3, 'ccc', 1, '2010-06-10 19:16:02'),
(4, 'ddd', 1, '2010-06-10 19:16:15'),
(5, 'eee', 2, '2010-06-10 19:16:35');
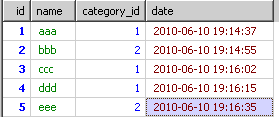
我现在需要取出每个分类中最新的内容
select * from test group by category_id order by `date`
结果如下
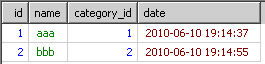
明显。这不是我想要的数据,原因是msyql已经的执行顺序是
写的顺序:select ... from... where.... group by... having... order by..
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
到group by时就得到了根据category_id分出来的多个小组
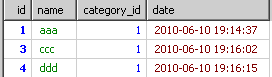
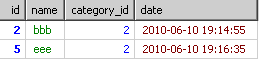
到了select的时候,只从上面的每个组里取第一条信息结果会如下
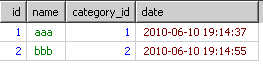
即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
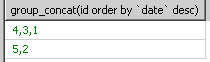
再改进一下
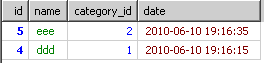
子查询解决方案
- order by、group by、distinct、having、group_concat、concat
- sql中Distinct、Group by、having、order by使用注意事项
- sql中Distinct、Group by、having、order by使用注意事项
- SQLite学习笔记五:Order By,Group By,Having,Distinct
- mysql关键字讲解(join 、order by、group by、having、distinct)
- group by 、 having 、 order by
- group by 、 having 、 order by
- having , group by , order by
- order by、group by、having语句
- order by、group by、having的区别
- group by,having,order by的用法
- group by ,order by ,having 简单用法
- oracle group by ,having ,order by
- group by , order by , having 的用法
- group by、having以及order by
- sql where group by having order by
- WHERE 、GROUP BY,HAVING、ORDER BY、LIME
- distinct、order by、 group by实现原理
- [转载]Android APK反编译就这么简单 详解(附图)
- C++ 运算符重载
- 【机器学习-西瓜书】九、聚类:性能度量;距离计算
- BACK按键流程
- 在Ubuntu下利用AndroidStudio查看源码
- order by、group by、distinct、having、group_concat、concat
- sql数据库操作
- 51Nod 1089 最长回文子串 V2(Manacher算法)
- centos 7.2 迁移 mysql 数据库文件
- 关于WSAEWOULDBLOCK错误
- 前端基础
- Shell脚本实现俄罗斯方块流程
- Android 支付宝调用测试版(沙箱环境)提示系统繁忙,请稍后再试(ALI40247)
- 常见PCB表面处理工艺简介


