Apriori算法
来源:互联网 发布:小企业网络循环贷款 编辑:程序博客网 时间:2024/06/19 00:15
从大规模数据集中寻找物品间的隐含关系被称作关联分析(association analysis)或者关联规则学习(association rule learning)。这里的主要问题在于,寻找物品的不同组合是一项十分耗时的任务,所需的计算代价很高,蛮力搜索方法并不能解决这个问题,所以需要用更智能的方法在合理的时间范围内找到频繁项集。
关联分析是在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:
- 频繁项集
- 关联规则
频繁项集(frequent item sets)是经常出现在一块儿的物品的集合,
关联规则(association rules)暗示两种物品之间可能存在很强的关系。
借用一个《机器学习实战》里的例子: 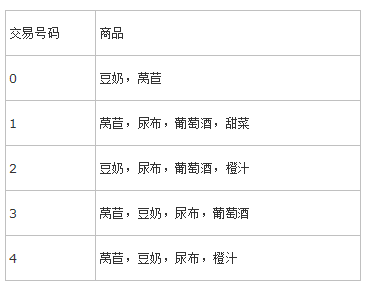
比如说 {尿布,豆奶} 就是一个频繁项集,因为这个组合在例子中经常出现;
然后我们从这个频繁项集出发分析,是不是买尿布的人就经常也买豆奶呢?
就得出了一个: 尿布
豆奶
再来两个概念 支持度(support) 和 可信度(confidence)
支持度:数据集中包含该项集的记录所占的比例
可信度:比如有两个集合 P,H; 则关联规则P
举几个简单的例子:
- {尿布,豆奶} 的 support 为 3/5,因为在 5 个交易中,{尿布,豆奶} 的组合出现了 3 次
- 那如果我们求 尿布
→ 豆奶 的 confidence 就是support({尿布,豆奶})support({尿布})=3/54/5=34 - 那么豆奶
→ 尿布 的 confidence 就是support({尿布,豆奶})support({豆奶})=3/54/5=34 ,…还是 3/4 ,很不幸的巧合,但是我们还是可以看出来,其实计算过程是不一样的
Apriori原理
频繁项集
支持度和可信度是用来量化关联分析是否成功的方法,假设想找到支持度大于 0.8 的所有项集,应该如何去做?一个办法是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度,但是当物品数量成千上万时,上述做法非常慢
我们可以这么想,如果一个项集是频繁的, 那么它的所有子集也都是频繁的;
接着:如果一个项集是非频繁的,那么它的所有超集也都是非频繁的。
这条结论就在于,之前我们说,列出所有可能的组合很麻烦,有了这个结论,我们如果找到一些非频繁项集,那么他们的超集就可以全部不用考虑了,这样就简化了很大一部分计算;这就是 Apriori原理
基于这样的思想,我们可以设计一个这样的算法,目标就是找到 support 大于等于一个阈值的所有频繁项集;
那么
Input: 最小support, 数据集
Output: 满足条件的所有频繁项集
主体思想就是:我们先算比较小的集合的support(最小就是单个元素的集合), 把计算过程中不满足support的集合去掉,以留下来的集合和元素组合成新的集合,然后继续筛选,直到留下的项集都满足最小support,返回结果。
所以我们可以看到核心部分就是,如何在一轮迭代之后生成新的数据集;因为每次迭代,我们的频繁项集都只加1,那么,我们生成新的候选的频繁项集的方法就是:用上一轮的项集中只相差1个元素的集合的并集作为新一轮候选的频繁项集。
明确这一点,代码就不难写了;
用一个python代码来表示:
def aprioriGen(Lk, k): retList = [] lenLk = len(Lk) for i in range(lenLk): for j in range(i + 1, lenLk): L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2] L1.sort(); L2.sort() if L1 == L2: retList.append(Lk[i] | Lk[j]) # 前k-2项相同时,将两个集合合并 return retList这里,是要生成集合中元素个数为 k 的候选频繁项集的,所以当前频繁项集元素个数为 k-1, 所以才有前k-2项相同时,将两个集合合并,来生成新的候选频繁项集;
关联规则
那么其实找规则也是类似的,找到confidence 大于等于一个阈值的所有关联规则;
在此使用Apriori算法,说到这样一句话:如果某条规则并不满足最小可信度要求,那么该规则的所有子集也不会满足最小可信度要求
怎么理解一条规则的子集?
假设项集为 {1,2,3,4},假设 0,1,2 -> 3 的 confidence 不满足最小可信度的要求,那么任意前件为{0,1,2}的子集的关联规则的 confidence 都不满足要求;
或者说 任何后件中包含 3 的关联规则的confidence都不满足要求。这就产生了一个问题….一个项集产生的关联规则中一定要包含项集里所有的元素吗?比如 {0,1,2,3} 产生的规则有没有可能是 {0,2}->{3} 。或者是说我们从这个项集中没有什么证据可以说明那条规则? 没有得到一些明确的解释,所以我暂且坚持自己的思考,即认可这样一个观点:
基于一个项集Y的信息,将 Y 分成两个互补的子集 X, Y-X ; 那么只能计算 X→ Y-X 或者 Y-X→ X 的confidence
基于上面的思想,我们可以这样生成关联规则,每次只让后件的元素个数加 1,可以有效快速的剪枝
我们可以看如下这幅图: 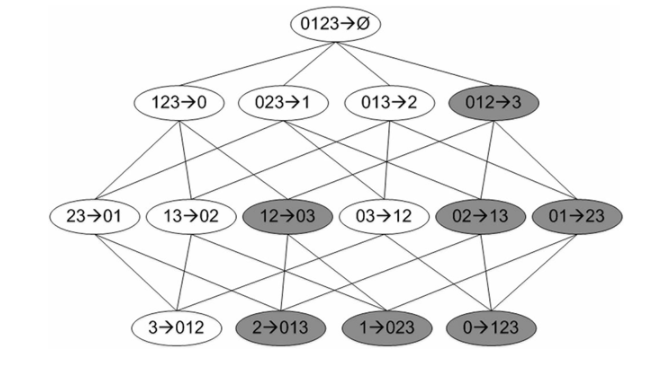
假设图中深色的关联规则为不符合要求的,那么我们在第二轮发现了一个不符合要求的规则,那么我们就可以把它的所有子节点(子孙节点)全部标为深色不用再考虑,意思就是,我们就不用在下一轮考虑这个结点生成的子节点了,这样就省掉了好多计算量。
- Apriori算法
- Apriori算法
- Apriori算法
- apriori 算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- Apriori算法
- iOS 手写键盘与触摸手势冲突,导致崩溃闪退
- Linux下安装Nginx
- 顺序表
- 如何看懂电路图
- elasticseach基础详解
- Apriori算法
- uiautomator:UiScrollable的用法
- JQuery 基本方法报错:... is not a function的问题
- oracle数据库表中数据删除的恢复方法
- 平面分割,空间分割问题(递推关系)(hdu1249、hdu1290、hdu2050)
- phpStudy+ThinkPHP配置的nginx环境出现404错误
- haproxy+keepalived 实现双主配置高可用负载均衡
- Django报错Exception Value: no such table xx
- Resnet-18-训练实验-warm up操作


