Elasticsearch之elasticsearch5.x 新特性
来源:互联网 发布:linux关闭nagle算法 编辑:程序博客网 时间:2024/05/23 10:48
转自:http://www.cnblogs.com/zlslch/p/6619089.html
1、首先看看跟性能有关的
1.1 aggregation 的改进也是非常大, Instant Aggregations。
Elasticsearch已经在Shard层面提供了Aggregation缓存,如果你的数据没有变化,ES能够直接返回上次的缓存结果,但是有一个场景比较特殊,就是 date histogram,大家kibana上面的条件是不是经常设置的相对时间,如:from:now-30d to:now,好吧,now是一个变量,每时每刻都在变,所以query条件一直在变,缓存也就是没有利用起来。经过一年时间大量的重构,现在可以做到对查询做到灵活的重写:
首先,now关键字最终会被重写成具体的值;
其次 , 每个shard会根据自己的数据的范围来重写查询为 match_all或者是match_none查询,所以现在的查询能够被有效的缓存,并且只有个别数据有变化的Shard才需要重新计算,大大提升查询速度。
1.2 Scroll相关
现在新增了一个:Sliced Scroll类型
用过Scroll接口吧,很慢?如果你数据量很大,用Scroll遍历数据那确实是接受不了,现在Scroll接口可以并发来进行数据遍历了。
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,利用Scroll重建或者遍历要快很多倍。
看看这个demo

可以看到两个 scroll 请求, id 分别是 0 和 1 , max 是最大可支持的并行任务,可以各自独立进行数据的遍历获取。
2、es在查询优化
新增了一个Profile API。
https://www.elastic.co/guide/en/elasticsearch/reference/master/search-profile.html#_usage_3
都说要致富先修路,要调优当然需要先监控啦,elasticsearch在很多层面都提供了stats方便你来监控调优,但是还不够,其实很多情况下查询速度慢很大一部分原因是糟糕的查询引起的,玩过SQL的人都知道,数据库服务的执行计划(execution plan)非常有用,可以看到那些查询走没走索引和执行时间,用来调优,elasticsearch现在提供了Profile API来进行查询的优化,只需要在查询的时候开启profile:true就可以了,一个查询执行过程中的每个组件的性能消耗都能收集到。
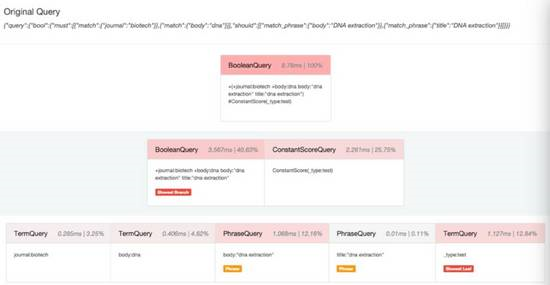
那个子查询耗时多少,占比多少,一目了然。
同时支持search和aggregation的profile。
还有一个和翻页相关的问题,就是深度分页 ,是个老大难的问题,因为需要全局排序( number_of_shards * (from + size) ),所以需要消耗大量内存,以前的 es 没有限制,有些同学翻到几千页发现 es 直接内存溢出挂了,后面 elasticsearch 加上了限制, from+size 不能超过 1w 条,并且如果需要深度翻页,建议使用 scroll 来做。
但是 scroll 有几个问题,第一个是没有顺序,直接从底层 segment 进行遍历读取,第二个实时性没法保证, scroll 操作有状态, es 会维持 scroll 请求的上下文一段时间,超时后才释放,另外你在 scroll 过程中对索引数据进行了修改了,这个时候 scroll接口是拿不到的,灵活性较差, 现在有一个新的 Search After 机制,其实和 scroll 类似,也是游标的机制,它的原理是对文档按照多个字段进行排序,然后利用上一个结果的最后一个文档作为起始值,拿 size 个文档,一般我们建议使用 _uid 这个字段,它的值是唯一的 id 。
Search After
https://github.com/elastic/elasticsearch/blob/148f9af5857f287666aead37f249f204a870ab39/docs/reference/search/request/search-after.asciidoc
来看一个Search After 的demo 吧,比较直观的理解一下: 
上面的 demo , search_after 后面带的两个参数,就是 sort 的两个结果。
根据你的排序条件来的,三个排序条件,就传三个参数。
3、索引与分片管理相关
新增了一个 Shrink API
https://www.elastic.co/guide/en/elasticsearch/reference/master/indices-shrink-index.html#_shrinking_an_index
相信大家都知道elasticsearch索引的shard数是固定的,设置好了之后不能修改,如果发现shard太多或者太少的问题,之前如果要设置Elasticsearch的分片数,只能在创建索引的时候设置好,并且数据进来了之后就不能进行修改,如果要修改,只能重建索引。
现在有了Shrink接口,它可将分片数进行收缩成它的因数,如之前你是15个分片,你可以收缩成5个或者3个又或者1个,那么我们就可以想象成这样一种场景,在写入压力非常大的收集阶段,设置足够多的索引,充分利用shard的并行写能力,索引写完之后收缩成更少的shard,提高查询性能。
这里是一个API调用的例子
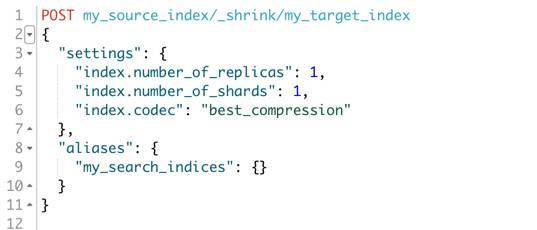
上面的例子对 my_source_index 伸缩成一个分片的 my_targe_index, 使用了最佳压缩。
有人肯定会问慢不慢?非常快! Shrink的过程会借助操作系统的Hardlink进行索引文件的链接,这个操作是非常快的,毫秒级Shrink就可收缩完成,当然windows不支持hard link,需要拷贝文件,可能就会很慢了。
新增了一个Rollover API。
https://www.elastic.co/guide/en/elasticsearch/reference/master/indices-rollover-index.html#indices-rollover-index
前面说的这种场景对于日志类的数据非常有用,一般我们按天来对索引进行分割(数据量更大还能进一步拆分),我们以前是在程序里设置一个自动生成索引的模板,大家用过logstash应该就记得有这么一个模板logstash-[YYYY-MM-DD]这样的模板,现在es5.0里面提供了一个更加简单的方式:Rollover API
API调用方式如下:

从上面可以看到,首先创建一个 logs-0001 的索引,它有一个别名是 logs_write, 然后我们给这个 logs_write 创建了一个 rollover 规则,即这个索引文档不超过 1000 个或者最多保存 7 天的数据,超过会自动切换别名到 logs-0002, 你也可以设置索引的 setting 、 mapping 等参数 , 剩下的 es 会自动帮你处理。这个特性对于存放日志数据的场景是极为友好的。
新增:Reindex
另外关于索引数据,大家之前经常重建,数据源在各种场景,重建起来很是头痛,那就不得不说说现在新加的Reindex接口了,Reindex可以直接在Elasticsearch集群里面对数据进行重建,如果你的mapping因为修改而需要重建,又或者索引设置修改需要重建的时候,借助Reindex可以很方便的异步进行重建,并且支持跨集群间的数据迁移。
比如按天创建的索引可以定期重建合并到以月为单位的索引里面去。
当然索引里面要启用_source。
来看看这个demo吧,重建过程中,还能对数据就行加工。

5.0里面提供了第一个Java原生的REST客户端SDK,相比之前的TransportClient,版本依赖绑定,集群升级麻烦,不支持跨Java版本的调用等问题,新的基于HTTP协议的客户端对Elasticsearch的依赖解耦,没有jar包冲突,提供了集群节点自动发现、日志处理、节点请求失败自动进行请求轮询,充分发挥Elasticsearch的高可用能力,并且性能不相上下。
4、其他特性
4.1 新增了一个 Wait for refresh 功能。
简单来说相当于是提供了文档级别的Refresh: https://www.elastic.co/guide/en/elasticsearch/reference/master/docs-refresh.html。
索引操作新增refresh参数,大家知道elasticsearch可以设置refresh时间来保证数据的实时性,refresh时间过于频繁会造成很大的开销,太小会造成数据的延时,之前提供了索引层面的_refresh接口,但是这个接口工作在索引层面,我们不建议频繁去调用,如果你有需要修改了某个文档,需要客户端实时可见怎么办?
在 5.0中,Index、Bulk、Delete、Update这些数据新增和修改的接口能够在单个文档层面进行refresh控制了,有两种方案可选,一种是创建一个很小的段,然后进行刷新保证可见和消耗一定的开销,另外一种是请求等待es的定期refresh之后再返回。
调用例子:
4.2 # 新增: Ingest Node #
#https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html#
再一个比较重要的特性就是IngestNode了,大家之前如果需要对数据进行加工,都是在索引之前进行处理,比如logstash可以对日志进行结构化和转换,现在直接在es就可以处理了,目前es提供了一些常用的诸如convert、grok之类的处理器,在使用的时候,先定义一个pipeline管道,里面设置文档的加工逻辑,在建索引的时候指定pipeline名称,那么这个索引就会按照预先定义好的pipeline来处理了;
Demo again:

上图首先创建了一个名为my-pipeline-id的处理管道,然后接下来的索引操作就可以直接使用这个管道来对foo字段进行操作了,上面的例子是设置foo字段为bar值。
上面的还不太酷,我们再来看另外一个例子,现在有这么一条原始的日志,内容如下:
{
“message”: “55.3.244.1 GET /index.html 15824 0.043”
}
google之后得知其Grok的pattern如下:)
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
那么我们使用Ingest就可以这么定义一个pipeline:
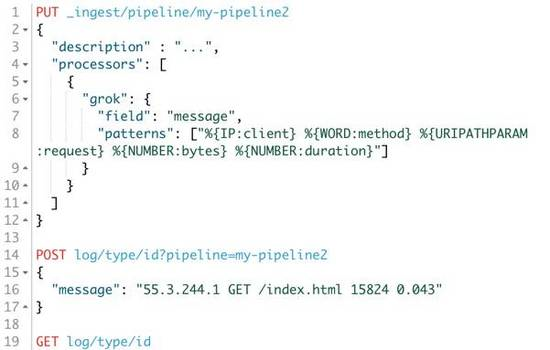
那么通过我们的 pipeline 处理之后的文档长什么样呢,我们获取这个文档的内容看看:
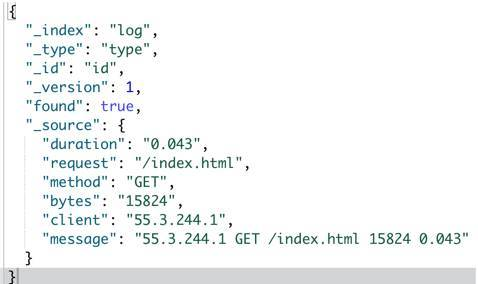
很明显,原始字段 message 被拆分成了更加结构化的对象了。
- Elasticsearch之elasticsearch5.x 新特性
- Elasticsearch之elasticsearch5.x 新特性
- elasticsearch 版本 2xx和5xx 及 elasticsearch5.x 新特性
- ElasticSearch之—— ElasticSearch5.x安装中一些问题的解决办法
- elasticsearch5.x之Slice scroll
- cocos2d-x 2.1新特性之CCClippingNode
- cocos2d-x 2.1新特性之CCClippingNode
- cocos2d-x新特性之CCClippingNode
- cocos2d-x 2.1新特性之CCClippingNode
- cocos3.x之C++11新特性
- Android5.x新特性之RecyclerGridView
- Android5.x新特性之RecyclerViewHorizontal、Vertical
- ruby 2.x.x之新特性散谈
- Android5.X新特性
- Unity5.x新特性
- Servlet3.x新特性
- .NET 3.x新特性之Lambda表达式
- .NET 3.x新特性之Lambda表达式
- hibernate中核心接口Query的用法简介
- python3的递归深度
- [python]leetcode(315). Count of Smaller Numbers After Self
- 字符串排序先导 键索引计数法 (c++ )
- GitChat · 运维 | 深入了解 Azure 云平台容器技术服务
- Elasticsearch之elasticsearch5.x 新特性
- 跳转语句,如果是pc访问就127.0.0.1
- 【Audio】耳机错误/频繁插入造成的无法识别
- 博客园 首页 新随笔 联系 订阅 管理 Ubuntu 16.04搭建LAMP开发环境 1. 配置网络环境 略 2. 设置ROOT密码 sud
- echarts2-网络动态攻击(带涟漪效果)
- 经验分享 | 【PDF下载】大数据峰会之MaxCompute数据上云与生态
- Android使用共享元素实现转场动画 错误:Unable to create layer for LinearLayout
- [转] 如何把书上的字弄到电脑上
- 在编译期,获得函数参数个数


