http://www.cnblogs.com/pinard/p/5970503.html
来源:互联网 发布:自动编程 编辑:程序博客网 时间:2024/06/16 07:58
梯度下降法的代数方式描述
1. 先决条件: 确认优化模型的假设函数和损失函数。
比如对于线性回归,假设函数表示为 
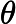

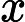
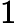
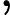
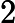
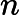


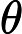
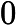

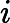
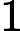
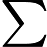

同样是线性回归,对应于上面的假设函数,损失函数为:
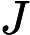
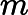

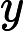
2. 算法相关参数初始化:主要是初始化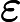
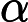
3. 算法过程:
1)确定当前位置的损失函数的梯度,对于
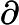
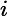
2)用步长乘以损失函数的梯度,得到当前位置下降的距离,即
3)确定是否所有的
4)更新所有的
:
下面用线性回归的例子来具体描述梯度下降。假设我们的样本是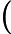
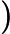
则在算法过程步骤1中对于
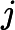
由于样本中没有
步骤4中
从这个例子可以看出当前点的梯度方向是由所有的样本决定的,加
阅读全文
0 0
- http://www.cnblogs.com/pinard/p/5970503.html
- 转载自http://www.cnblogs.com/pinard/p/5970503.html---梯度下降讲解
- http://www.cnblogs.com/flylovesky/p/3274869.html
- http://www.cnblogs.com/ada-zheng/p/3284660.html
- http://www.cnblogs.com/zhanghaiba/p/3548602.html
- http://www.cnblogs.com/scy251147/p/3566638.html
- http://www.cnblogs.com/amosli/p/3577645.html
- http://www.cnblogs.com/VisualImage/p/3594973.html
- http://www.cnblogs.com/kuangbin/p/3164106.html
- http://www.cnblogs.com/wengzilin/p/3530712.html
- http://www.cnblogs.com/qingjoin/p/3549325.html
- http://www.cnblogs.com/interdrp/p/3785164.html
- http://www.cnblogs.com/ruiati/p/3930732.html
- http://www.cnblogs.com/knowledgesea/p/3491214.html
- http://www.cnblogs.com/ganganloveu/p/3755191.html
- http://www.cnblogs.com/kenshincui/p/3885689.html
- http://www.cnblogs.com/lanxuezaipiao/p/3440471.html
- http://www.cnblogs.com/wangfupeng1988/p/4001284.html
- C#day2
- Python continue 语句
- Linux文件权限
- maven-小白入门学习笔记2
- java提高篇(四)-----抽象类与接口
- http://www.cnblogs.com/pinard/p/5970503.html
- 鼠标事件
- 顺序表实验--数组法
- 微信公众号支付开发中所遇到的坑
- 动态代理VS静态代理
- 关于对象序列化与反序列化的那些事
- 数据库事务的四大特性以及事务的隔离级别
- 过滤器Filter
- Redis-初始


