Linux SPI框架(下)
来源:互联网 发布:2016电大数控编程技术 编辑:程序博客网 时间:2024/04/29 19:10
水平有限,描述不当之处还请之处,转载请注明出处http://blog.csdn.net/vanbreaker/article/details/7737833
本节以spidev设备驱动为例,来阐述SPI数据传输的过程。spidev是内核中一个通用的设备驱动,我们注册的从设备都可以使用该驱动,只需在注册时将从设备的modalias字段设置为”spidev”,这样才能和spidev驱动匹配成功。我们要传输的数据有时需要分为一段一段的(比如先发送,后读取,就需要两个字段),每个字段都被封装成一个transfer,N个transfer可以被添加到message中,作为一个消息包进行传输。当用户发出传输数据的请求时,message并不会立刻传输到从设备,而是由之前定义的transfer()函数将message放入一个等待队列中,这些message会以FIFO的方式有workqueue调度进行传输,这样能够避免SPI从设备同一时间对主SPI控制器的竞争。和之前一样,还是习惯先画一张图来描述数据传输的主要过程。
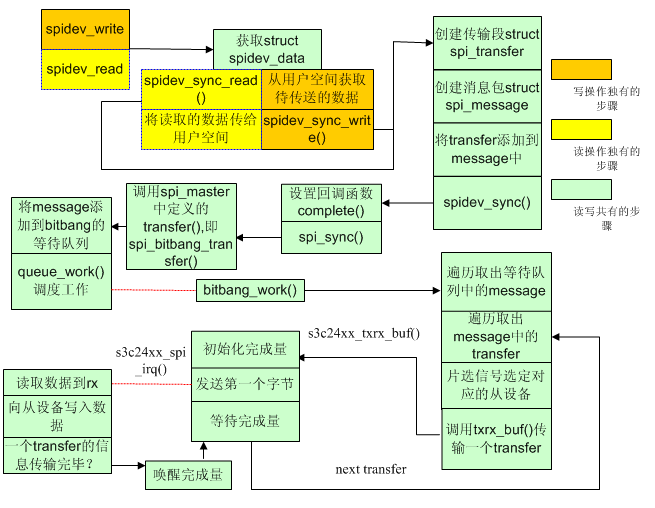
在使用spidev设备驱动时,需要先初始化spidev. spidev是以字符设备的形式注册进内核的。
- static int __init spidev_init(void)
- {
- int status;
- /* Claim our 256 reserved device numbers. Then register a class
- * that will key udev/mdev to add/remove /dev nodes. Last, register
- * the driver which manages those device numbers.
- */
- BUILD_BUG_ON(N_SPI_MINORS > 256);
- /*将spidev作为字符设备注册*/
- status = register_chrdev(SPIDEV_MAJOR, ”spi”, &spidev_fops);
- if (status < 0)
- return status;
- /*创建spidev类*/
- spidev_class = class_create(THIS_MODULE, ”spidev”);
- if (IS_ERR(spidev_class)) {
- unregister_chrdev(SPIDEV_MAJOR, spidev_spi.driver.name);
- return PTR_ERR(spidev_class);
- }
- /*注册spidev的driver,可与modalias字段为”spidev”的spi_device匹配*/
- status = spi_register_driver(&spidev_spi);
- if (status < 0) {
- class_destroy(spidev_class);
- unregister_chrdev(SPIDEV_MAJOR, spidev_spi.driver.name);
- }
- return status;
- }
static int __init spidev_init(void){ int status; /* Claim our 256 reserved device numbers. Then register a class * that will key udev/mdev to add/remove /dev nodes. Last, register * the driver which manages those device numbers. */ BUILD_BUG_ON(N_SPI_MINORS > 256); /*将spidev作为字符设备注册*/ status = register_chrdev(SPIDEV_MAJOR, "spi", &spidev_fops); if (status < 0) return status; /*创建spidev类*/ spidev_class = class_create(THIS_MODULE, "spidev"); if (IS_ERR(spidev_class)) { unregister_chrdev(SPIDEV_MAJOR, spidev_spi.driver.name); return PTR_ERR(spidev_class); } /*注册spidev的driver,可与modalias字段为"spidev"的spi_device匹配*/ status = spi_register_driver(&spidev_spi); if (status < 0) { class_destroy(spidev_class); unregister_chrdev(SPIDEV_MAJOR, spidev_spi.driver.name); } return status;}
与相应的从设备匹配成功后,则调用spidev中的probe函数
- static int spidev_probe(struct spi_device *spi)
- {
- struct spidev_data *spidev;
- int status;
- unsigned long minor;
- /* Allocate driver data */
- spidev = kzalloc(sizeof(*spidev), GFP_KERNEL);
- if (!spidev)
- return -ENOMEM;
- /* Initialize the driver data */
- spidev->spi = spi;//设定spi
- spin_lock_init(&spidev->spi_lock);
- mutex_init(&spidev->buf_lock);
- INIT_LIST_HEAD(&spidev->device_entry);
- /* If we can allocate a minor number, hook up this device.
- * Reusing minors is fine so long as udev or mdev is working.
- */
- mutex_lock(&device_list_lock);
- minor = find_first_zero_bit(minors, N_SPI_MINORS);//寻找没被占用的次设备号
- if (minor < N_SPI_MINORS) {
- struct device *dev;
- /*计算设备号*/
- spidev->devt = MKDEV(SPIDEV_MAJOR, minor);
- /*在spidev_class下创建设备*/
- dev = device_create(spidev_class, &spi->dev, spidev->devt,
- spidev, ”spidev%d.%d”,
- spi->master->bus_num, spi->chip_select);
- status = IS_ERR(dev) ? PTR_ERR(dev) : 0;
- } else {
- dev_dbg(&spi->dev, ”no minor number available!\n”);
- status = -ENODEV;
- }
- if (status == 0) {
- set_bit(minor, minors);//将minors的相应位置位,表示该位对应的次设备号已被占用
- list_add(&spidev->device_entry, &device_list);//将创建的spidev添加到device_list
- }
- mutex_unlock(&device_list_lock);
- if (status == 0)
- spi_set_drvdata(spi, spidev);
- else
- kfree(spidev);
- return status;
- }
static int spidev_probe(struct spi_device *spi){ struct spidev_data *spidev; int status; unsigned long minor; /* Allocate driver data */ spidev = kzalloc(sizeof(*spidev), GFP_KERNEL); if (!spidev) return -ENOMEM; /* Initialize the driver data */ spidev->spi = spi;//设定spi spin_lock_init(&spidev->spi_lock); mutex_init(&spidev->buf_lock); INIT_LIST_HEAD(&spidev->device_entry); /* If we can allocate a minor number, hook up this device. * Reusing minors is fine so long as udev or mdev is working. */ mutex_lock(&device_list_lock); minor = find_first_zero_bit(minors, N_SPI_MINORS);//寻找没被占用的次设备号 if (minor < N_SPI_MINORS) { struct device *dev; /*计算设备号*/ spidev->devt = MKDEV(SPIDEV_MAJOR, minor); /*在spidev_class下创建设备*/ dev = device_create(spidev_class, &spi->dev, spidev->devt, spidev, "spidev%d.%d", spi->master->bus_num, spi->chip_select); status = IS_ERR(dev) ? PTR_ERR(dev) : 0; } else { dev_dbg(&spi->dev, "no minor number available!\n"); status = -ENODEV; } if (status == 0) { set_bit(minor, minors);//将minors的相应位置位,表示该位对应的次设备号已被占用 list_add(&spidev->device_entry, &device_list);//将创建的spidev添加到device_list } mutex_unlock(&device_list_lock); if (status == 0) spi_set_drvdata(spi, spidev); else kfree(spidev); return status;}
然后就可以利用spidev模块提供的接口来实现主从设备之间的数据传输了。我们以spidev_write()函数为例来分析数据传输的过程,实际上spidev_read()和其是差不多的,只是前面的一些步骤不一样,可以参照上图。
- static ssize_t
- spidev_write(struct file *filp, const char __user *buf,
- size_t count, loff_t *f_pos)
- {
- struct spidev_data *spidev;
- ssize_t status = 0;
- unsigned long missing;
- /* chipselect only toggles at start or end of operation */
- if (count > bufsiz)
- return -EMSGSIZE;
- spidev = filp->private_data;
- mutex_lock(&spidev->buf_lock);
- //将用户要发送的数据拷贝到spidev->buffer
- missing = copy_from_user(spidev->buffer, buf, count);
- if (missing == 0) {//全部拷贝成功,则调用spidev_sysn_write()
- status = spidev_sync_write(spidev, count);
- } else
- status = -EFAULT;
- mutex_unlock(&spidev->buf_lock);
- return status;
- }
static ssize_tspidev_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos){ struct spidev_data *spidev; ssize_t status = 0; unsigned long missing; /* chipselect only toggles at start or end of operation */ if (count > bufsiz) return -EMSGSIZE; spidev = filp->private_data; mutex_lock(&spidev->buf_lock); //将用户要发送的数据拷贝到spidev->buffer missing = copy_from_user(spidev->buffer, buf, count); if (missing == 0) {//全部拷贝成功,则调用spidev_sysn_write() status = spidev_sync_write(spidev, count); } else status = -EFAULT; mutex_unlock(&spidev->buf_lock); return status;}
- static inline ssize_t
- spidev_sync_write(struct spidev_data *spidev, size_t len)
- {
- struct spi_transfer t = {//设置传输字段
- .tx_buf = spidev->buffer,
- .len = len,
- };
- struct spi_message m;//创建message
- spi_message_init(&m);
- spi_message_add_tail(&t, &m);//将transfer添加到message中
- return spidev_sync(spidev, &m);
- }
static inline ssize_tspidev_sync_write(struct spidev_data *spidev, size_t len){ struct spi_transfer t = {//设置传输字段 .tx_buf = spidev->buffer, .len = len, }; struct spi_message m;//创建message spi_message_init(&m); spi_message_add_tail(&t, &m);//将transfer添加到message中 return spidev_sync(spidev, &m);}
我们来看看struct spi_transfer和struct spi_message是如何定义的
- struct spi_transfer {
- /* it’s ok if tx_buf == rx_buf (right?)
- * for MicroWire, one buffer must be null
- * buffers must work with dma_*map_single() calls, unless
- * spi_message.is_dma_mapped reports a pre-existing mapping
- */
- const void *tx_buf;//发送缓冲区
- void *rx_buf;//接收缓冲区
- unsigned len; //传输数据的长度
- dma_addr_t tx_dma;
- dma_addr_t rx_dma;
- unsigned cs_change:1; //该位如果为1,则表示当该transfer传输完后,改变片选信号
- u8 bits_per_word;//字比特数
- u16 delay_usecs; //传输后的延时
- u32 speed_hz; //指定的时钟
- struct list_head transfer_list;//用于将该transfer链入message
- };
struct spi_transfer { /* it's ok if tx_buf == rx_buf (right?) * for MicroWire, one buffer must be null * buffers must work with dma_*map_single() calls, unless * spi_message.is_dma_mapped reports a pre-existing mapping */ const void *tx_buf;//发送缓冲区 void *rx_buf;//接收缓冲区 unsigned len; //传输数据的长度 dma_addr_t tx_dma; dma_addr_t rx_dma; unsigned cs_change:1; //该位如果为1,则表示当该transfer传输完后,改变片选信号 u8 bits_per_word;//字比特数 u16 delay_usecs; //传输后的延时 u32 speed_hz; //指定的时钟 struct list_head transfer_list;//用于将该transfer链入message};
- struct spi_message {
- struct list_head transfers;//用于链接spi_transfer
- struct spi_device *spi; //指向目的从设备
- unsigned is_dma_mapped:1;
- /* REVISIT: we might want a flag affecting the behavior of the
- * last transfer … allowing things like “read 16 bit length L”
- * immediately followed by “read L bytes”. Basically imposing
- * a specific message scheduling algorithm.
- *
- * Some controller drivers (message-at-a-time queue processing)
- * could provide that as their default scheduling algorithm. But
- * others (with multi-message pipelines) could need a flag to
- * tell them about such special cases.
- */
- /* completion is reported through a callback */
- void (*complete)(void *context);//用于异步传输完成时调用的回调函数
- void *context; //回调函数的参数
- unsigned actual_length; //实际传输的长度
- int status;
- /* for optional use by whatever driver currently owns the
- * spi_message … between calls to spi_async and then later
- * complete(), that’s the spi_master controller driver.
- */
- struct list_head queue; //用于将该message链入bitbang等待队列
- void *state;
- };
struct spi_message { struct list_head transfers;//用于链接spi_transfer struct spi_device *spi; //指向目的从设备 unsigned is_dma_mapped:1; /* REVISIT: we might want a flag affecting the behavior of the * last transfer ... allowing things like "read 16 bit length L" * immediately followed by "read L bytes". Basically imposing * a specific message scheduling algorithm. * * Some controller drivers (message-at-a-time queue processing) * could provide that as their default scheduling algorithm. But * others (with multi-message pipelines) could need a flag to * tell them about such special cases. */ /* completion is reported through a callback */ void (*complete)(void *context);//用于异步传输完成时调用的回调函数 void *context; //回调函数的参数 unsigned actual_length; //实际传输的长度 int status; /* for optional use by whatever driver currently owns the * spi_message ... between calls to spi_async and then later * complete(), that's the spi_master controller driver. */ struct list_head queue; //用于将该message链入bitbang等待队列 void *state;};
继续跟踪源码,进入spidev_sync(),从这一步开始,read和write就完全一样了
- <span style=“font-size:12px;”>static ssize_t
- spidev_sync(struct spidev_data *spidev, struct spi_message *message)
- {
- DECLARE_COMPLETION_ONSTACK(done);
- int status;
- message->complete = spidev_complete;//设置回调函数
- message->context = &done;
- spin_lock_irq(&spidev->spi_lock);
- if (spidev->spi == NULL)
- status = -ESHUTDOWN;
- else
- status = spi_async(spidev->spi, message);//调用spi核心层的函数spi_async()
- spin_unlock_irq(&spidev->spi_lock);
- if (status == 0) {
- wait_for_completion(&done);
- status = message->status;
- if (status == 0)
- status = message->actual_length;
- }
- return status;
- }</span>
static ssize_tspidev_sync(struct spidev_data *spidev, struct spi_message *message){ DECLARE_COMPLETION_ONSTACK(done); int status; message->complete = spidev_complete;//设置回调函数 message->context = &done; spin_lock_irq(&spidev->spi_lock); if (spidev->spi == NULL) status = -ESHUTDOWN; else status = spi_async(spidev->spi, message);//调用spi核心层的函数spi_async() spin_unlock_irq(&spidev->spi_lock); if (status == 0) { wait_for_completion(&done); status = message->status; if (status == 0) status = message->actual_length; } return status;}
- static inline int
- spi_async(struct spi_device *spi, struct spi_message *message)
- {
- message->spi = spi;
- /*调用master的transfer函数将message放入等待队列*/
- return spi->master->transfer(spi, message);
- }
static inline intspi_async(struct spi_device *spi, struct spi_message *message){ message->spi = spi; /*调用master的transfer函数将message放入等待队列*/ return spi->master->transfer(spi, message);}
s3c24xx平台下的transfer函数是在bitbang_start()函数中定义的,为bitbang_transfer()
- int spi_bitbang_transfer(struct spi_device *spi, struct spi_message *m)
- {
- struct spi_bitbang *bitbang;
- unsigned long flags;
- int status = 0;
- m->actual_length = 0;
- m->status = -EINPROGRESS;
- bitbang = spi_master_get_devdata(spi->master);
- spin_lock_irqsave(&bitbang->lock, flags);
- if (!spi->max_speed_hz)
- status = -ENETDOWN;
- else {
- list_add_tail(&m->queue, &bitbang->queue);//将message添加到bitbang的等待队列
- queue_work(bitbang->workqueue, &bitbang->work);//调度运行work
- }
- spin_unlock_irqrestore(&bitbang->lock, flags);
- return status;
- }
int spi_bitbang_transfer(struct spi_device *spi, struct spi_message *m){ struct spi_bitbang *bitbang; unsigned long flags; int status = 0; m->actual_length = 0; m->status = -EINPROGRESS; bitbang = spi_master_get_devdata(spi->master); spin_lock_irqsave(&bitbang->lock, flags); if (!spi->max_speed_hz) status = -ENETDOWN; else { list_add_tail(&m->queue, &bitbang->queue);//将message添加到bitbang的等待队列 queue_work(bitbang->workqueue, &bitbang->work);//调度运行work } spin_unlock_irqrestore(&bitbang->lock, flags); return status;}这里可以看到transfer函数不负责实际的数据传输,而是将message添加到等待队列中。同样在spi_bitbang_start()中,有这样一个定义INIT_WORK(&bitbang->work, bitbang_work);因此bitbang_work()函数会被调度运行,类似于底半部机制
- static void bitbang_work(struct work_struct *work)
- {
- struct spi_bitbang *bitbang =
- container_of(work, struct spi_bitbang, work);//获取bitbang
- unsigned long flags;
- spin_lock_irqsave(&bitbang->lock, flags);
- bitbang->busy = 1;
- while (!list_empty(&bitbang->queue)) {//等待队列不为空
- struct spi_message *m;
- struct spi_device *spi;
- unsigned nsecs;
- struct spi_transfer *t = NULL;
- unsigned tmp;
- unsigned cs_change;
- int status;
- int (*setup_transfer)(struct spi_device *,
- struct spi_transfer *);
- /*取出等待队列中的的第一个message*/
- m = container_of(bitbang->queue.next, struct spi_message,
- queue);
- list_del_init(&m->queue);//将message从队列中删除
- spin_unlock_irqrestore(&bitbang->lock, flags);
- /* FIXME this is made-up … the correct value is known to
- * word-at-a-time bitbang code, and presumably chipselect()
- * should enforce these requirements too?
- */
- nsecs = 100;
- spi = m->spi;
- tmp = 0;
- cs_change = 1;
- status = 0;
- setup_transfer = NULL;
- /*遍历message中的所有传输字段,逐一进行传输*/
- list_for_each_entry (t, &m->transfers, transfer_list) {
- /* override or restore speed and wordsize */
- if (t->speed_hz || t->bits_per_word) {
- setup_transfer = bitbang->setup_transfer;
- if (!setup_transfer) {
- status = -ENOPROTOOPT;
- break;
- }
- }
- /*调用setup_transfer根据transfer中的信息进行时钟、字比特数的设定*/
- if (setup_transfer) {
- status = setup_transfer(spi, t);
- if (status < 0)
- break;
- }
- /* set up default clock polarity, and activate chip;
- * this implicitly updates clock and spi modes as
- * previously recorded for this device via setup().
- * (and also deselects any other chip that might be
- * selected …)
- */
- if (cs_change) {//使能外设的片选
- bitbang->chipselect(spi, BITBANG_CS_ACTIVE);
- ndelay(nsecs);
- }
- cs_change = t->cs_change;//这里确定进行了这个字段的传输后是否要改变片选状态
- if (!t->tx_buf && !t->rx_buf && t->len) {
- status = -EINVAL;
- break;
- }
- /* transfer data. the lower level code handles any
- * new dma mappings it needs. our caller always gave
- * us dma-safe buffers.
- */
- if (t->len) {
- /* REVISIT dma API still needs a designated
- * DMA_ADDR_INVALID; ~0 might be better.
- */
- if (!m->is_dma_mapped)
- t->rx_dma = t->tx_dma = 0;
- /*调用针对于平台的传输函数txrx_bufs*/
- status = bitbang->txrx_bufs(spi, t);
- }
- if (status > 0)
- m->actual_length += status;
- if (status != t->len) {
- /* always report some kind of error */
- if (status >= 0)
- status = -EREMOTEIO;
- break;
- }
- status = 0;
- /* protocol tweaks before next transfer */
- /*如果要求在传输完一个字段后进行delay,则进行delay*/
- if (t->delay_usecs)
- udelay(t->delay_usecs);
- if (!cs_change)
- continue;
- /*最后一个字段传输完毕了,则跳出循环*/
- if (t->transfer_list.next == &m->transfers)
- break;
- /* sometimes a short mid-message deselect of the chip
- * may be needed to terminate a mode or command
- */
- ndelay(nsecs);
- bitbang->chipselect(spi, BITBANG_CS_INACTIVE);
- ndelay(nsecs);
- }
- m->status = status;
- m->complete(m->context);
- /* restore speed and wordsize */
- if (setup_transfer)
- setup_transfer(spi, NULL);
- /* normally deactivate chipselect … unless no error and
- * cs_change has hinted that the next message will probably
- * be for this chip too.
- */
- if (!(status == 0 && cs_change)) {
- ndelay(nsecs);
- bitbang->chipselect(spi, BITBANG_CS_INACTIVE);
- ndelay(nsecs);
- }
- spin_lock_irqsave(&bitbang->lock, flags);
- }
- bitbang->busy = 0;
- spin_unlock_irqrestore(&bitbang->lock, flags);
- }
static void bitbang_work(struct work_struct *work){ struct spi_bitbang *bitbang = container_of(work, struct spi_bitbang, work);//获取bitbang unsigned long flags; spin_lock_irqsave(&bitbang->lock, flags); bitbang->busy = 1; while (!list_empty(&bitbang->queue)) {//等待队列不为空 struct spi_message *m; struct spi_device *spi; unsigned nsecs; struct spi_transfer *t = NULL; unsigned tmp; unsigned cs_change; int status; int (*setup_transfer)(struct spi_device *, struct spi_transfer *); /*取出等待队列中的的第一个message*/ m = container_of(bitbang->queue.next, struct spi_message, queue); list_del_init(&m->queue);//将message从队列中删除 spin_unlock_irqrestore(&bitbang->lock, flags); /* FIXME this is made-up ... the correct value is known to * word-at-a-time bitbang code, and presumably chipselect() * should enforce these requirements too? */ nsecs = 100; spi = m->spi; tmp = 0; cs_change = 1; status = 0; setup_transfer = NULL; /*遍历message中的所有传输字段,逐一进行传输*/ list_for_each_entry (t, &m->transfers, transfer_list) { /* override or restore speed and wordsize */ if (t->speed_hz || t->bits_per_word) { setup_transfer = bitbang->setup_transfer; if (!setup_transfer) { status = -ENOPROTOOPT; break; } } /*调用setup_transfer根据transfer中的信息进行时钟、字比特数的设定*/ if (setup_transfer) { status = setup_transfer(spi, t); if (status < 0) break; } /* set up default clock polarity, and activate chip; * this implicitly updates clock and spi modes as * previously recorded for this device via setup(). * (and also deselects any other chip that might be * selected ...) */ if (cs_change) {//使能外设的片选 bitbang->chipselect(spi, BITBANG_CS_ACTIVE); ndelay(nsecs); } cs_change = t->cs_change;//这里确定进行了这个字段的传输后是否要改变片选状态 if (!t->tx_buf && !t->rx_buf && t->len) { status = -EINVAL; break; } /* transfer data. the lower level code handles any * new dma mappings it needs. our caller always gave * us dma-safe buffers. */ if (t->len) { /* REVISIT dma API still needs a designated * DMA_ADDR_INVALID; ~0 might be better. */ if (!m->is_dma_mapped) t->rx_dma = t->tx_dma = 0; /*调用针对于平台的传输函数txrx_bufs*/ status = bitbang->txrx_bufs(spi, t); } if (status > 0) m->actual_length += status; if (status != t->len) { /* always report some kind of error */ if (status >= 0) status = -EREMOTEIO; break; } status = 0; /* protocol tweaks before next transfer */ /*如果要求在传输完一个字段后进行delay,则进行delay*/ if (t->delay_usecs) udelay(t->delay_usecs); if (!cs_change) continue; /*最后一个字段传输完毕了,则跳出循环*/ if (t->transfer_list.next == &m->transfers) break; /* sometimes a short mid-message deselect of the chip * may be needed to terminate a mode or command */ ndelay(nsecs); bitbang->chipselect(spi, BITBANG_CS_INACTIVE); ndelay(nsecs); } m->status = status; m->complete(m->context); /* restore speed and wordsize */ if (setup_transfer) setup_transfer(spi, NULL); /* normally deactivate chipselect ... unless no error and * cs_change has hinted that the next message will probably * be for this chip too. */ if (!(status == 0 && cs_change)) { ndelay(nsecs); bitbang->chipselect(spi, BITBANG_CS_INACTIVE); ndelay(nsecs); } spin_lock_irqsave(&bitbang->lock, flags); } bitbang->busy = 0; spin_unlock_irqrestore(&bitbang->lock, flags);}
只要bitbang->queue等待队列不为空,就表示相应的SPI主控制器上还有传输任务没有完成,因此bitbang_work()会被不断地调度执行。 bitbang_work()中的工作主要是两个循环,外循环遍历等待队列中的message,内循环遍历message中的transfer,在bitbang_work()中,传输总是以transfer为单位的。当选定了一个transfer后,便会调用transfer_txrx()函数,进行实际的数据传输,显然这个函数是针对于平台的SPI控制器而实现的,在s3c24xx平台中,该函数为s3c24xx_spi_txrx();
- static int s3c24xx_spi_txrx(struct spi_device *spi, struct spi_transfer *t)
- {
- struct s3c24xx_spi *hw = to_hw(spi);
- dev_dbg(&spi->dev, ”txrx: tx %p, rx %p, len %d\n”,
- t->tx_buf, t->rx_buf, t->len);
- hw->tx = t->tx_buf;//获取发送缓冲区
- hw->rx = t->rx_buf;//获取读取缓存区
- hw->len = t->len; //获取数据长度
- hw->count = 0;
- init_completion(&hw->done);//初始化完成量
- /* send the first byte */
- /*只发送第一个字节,其他的在中断中发送(读取)*/
- writeb(hw_txbyte(hw, 0), hw->regs + S3C2410_SPTDAT);
- wait_for_completion(&hw->done);
- return hw->count;
- }
static int s3c24xx_spi_txrx(struct spi_device *spi, struct spi_transfer *t){ struct s3c24xx_spi *hw = to_hw(spi); dev_dbg(&spi->dev, "txrx: tx %p, rx %p, len %d\n", t->tx_buf, t->rx_buf, t->len); hw->tx = t->tx_buf;//获取发送缓冲区 hw->rx = t->rx_buf;//获取读取缓存区 hw->len = t->len; //获取数据长度 hw->count = 0; init_completion(&hw->done);//初始化完成量 /* send the first byte */ /*只发送第一个字节,其他的在中断中发送(读取)*/ writeb(hw_txbyte(hw, 0), hw->regs + S3C2410_SPTDAT); wait_for_completion(&hw->done); return hw->count;}
- static inline unsigned int hw_txbyte(struct s3c24xx_spi *hw, int count)
- {
- /*如果tx不为空,也就是说当前是从主机向从机发送数据,则直接将tx[count]发送过去,
- 如果tx为空,也就是说当前是从从机向主机发送数据,则向从机写入0*/
- return hw->tx ? hw->tx[count] : 0;
- }
static inline unsigned int hw_txbyte(struct s3c24xx_spi *hw, int count){ /*如果tx不为空,也就是说当前是从主机向从机发送数据,则直接将tx[count]发送过去, 如果tx为空,也就是说当前是从从机向主机发送数据,则向从机写入0*/ return hw->tx ? hw->tx[count] : 0;}
负责SPI数据传输的中断函数:
- static irqreturn_t s3c24xx_spi_irq(int irq, void *dev)
- {
- struct s3c24xx_spi *hw = dev;
- unsigned int spsta = readb(hw->regs + S3C2410_SPSTA);
- unsigned int count = hw->count;
- /*冲突检测*/
- if (spsta & S3C2410_SPSTA_DCOL) {
- dev_dbg(hw->dev, ”data-collision\n”);
- complete(&hw->done);
- goto irq_done;
- }
- /*设备忙检测*/
- if (!(spsta & S3C2410_SPSTA_READY)) {
- dev_dbg(hw->dev, ”spi not ready for tx?\n”);
- complete(&hw->done);
- goto irq_done;
- }
- hw->count++;
- if (hw->rx)//读取数据到缓冲区
- hw->rx[count] = readb(hw->regs + S3C2410_SPRDAT);
- count++;
- if (count < hw->len)//向从机写入数据
- writeb(hw_txbyte(hw, count), hw->regs + S3C2410_SPTDAT);
- else//count == len,一个字段发送完成,唤醒完成量
- complete(&hw->done);
- irq_done:
- return IRQ_HANDLED;
- }
static irqreturn_t s3c24xx_spi_irq(int irq, void *dev){ struct s3c24xx_spi *hw = dev; unsigned int spsta = readb(hw->regs + S3C2410_SPSTA); unsigned int count = hw->count; /*冲突检测*/ if (spsta & S3C2410_SPSTA_DCOL) { dev_dbg(hw->dev, "data-collision\n"); complete(&hw->done); goto irq_done; } /*设备忙检测*/ if (!(spsta & S3C2410_SPSTA_READY)) { dev_dbg(hw->dev, "spi not ready for tx?\n"); complete(&hw->done); goto irq_done; } hw->count++; if (hw->rx)//读取数据到缓冲区 hw->rx[count] = readb(hw->regs + S3C2410_SPRDAT); count++; if (count < hw->len)//向从机写入数据 writeb(hw_txbyte(hw, count), hw->regs + S3C2410_SPTDAT); else//count == len,一个字段发送完成,唤醒完成量 complete(&hw->done); irq_done: return IRQ_HANDLED;}这里可以看到一点,即使tx为空,也就是说用户申请的是从从设备读取数据,也要不断地向从设备写入数据,只不过写入从设备的是无效数据(0),这样做得目的是为了维持SPI总线上的时钟。至此,SPI框架已分析完毕。
- Linux SPI框架(下)
- Linux SPI框架(下)
- Linux SPI框架(下)
- Linux SPI框架(下)
- LInux SPI框架(下)
- Linux下spi驱动开发理论框架
- Linux SPI框架(上)
- Linux SPI框架(中)
- Linux SPI框架(上)
- Linux SPI框架(中)
- linux spi子系统(框架) .
- Linux SPI框架(上)
- Linux SPI框架(中)
- Linux SPI框架(中)
- Linux SPI框架(上)
- Linux SPI框架 (1)
- Linux SPI框架 (2)
- Linux SPI框架 (3)
- Storm Running Topologies on a Production Cluster
- 使用 Kotlin 开发 Android 应用 | 8 个最优秀的 Android Studio 插件 Kotlin Android 素材
- 《Kotin 极简教程》第14章 使用 Kotlin DSL
- 《Kotin 极简教程》第15章 Kotlin 文件IO操作、正则表达式与多线程
- c#将DataTable中数据写入到CSV文件中
- Linux SPI框架(下)
- 《Kotin 极简教程》第16章 使用 Kotlin Native
- wampservice 支持Python CGI的配置
- 使用 Kotlin 实现 Y 组合子(Y-Combinator)
- 《Spring Boot 实战:从0到1 》
- Spring Boot + JPA + Freemarker 实现后端分页 完整示例
- 《零基础 Java Web 开发》 全书目录
- 《零基础 Java 开发 》全书目录
- LeetCode 106. Construct Binary Tree from Inorder and Postorder Traversal


