论文学习笔记: Convolutional Neural Pyramid for Image Processing
来源:互联网 发布:java中实例化是什么 编辑:程序博客网 时间:2024/05/16 10:58
论文学习笔记: Convolutional Neural Pyramid for Image Processing
原文链接:Convolutional Neural Pyramid for Image Processing
前言
今年刚出的文章,面对的是image restoration的问题。
既然是图像修复, 那么进行修复工作的依据,也就是信息来源,必然是图像的其他完好的区域。所能获取相关图像信息的范围越大,特征越丰富,进行修补工作显然是越容易的。
在卷积网络中,感受野这一概念被用来表示一个特征的信息来源在原图上的分布。其定义为 : 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
关于感受野的概念和计算,可以参看这篇文档 : 卷积神经网络物体检测之感受野大小计算
按照原文摘要中的说法:
But corresponding neural networks for regression either stack many layers or apply large kernels to achieve it, which is computationally very costly.
为了获得更大的感受野,采用的方法往往是
- 堆叠很多数量的网络层数
- 采用大尺度的卷积模板
这就会消耗大量的计算资源。虽然还有像dilated convolution这样的稀疏的卷积模板,试图缓解计算量和感受野大小的矛盾,但其本质还是采用更大的卷积模板。
同时,原文也提到:
This analysis also reveals the fact that color and edge information vanishes in late hidden layers.
即采用更多的网络层数会使一些较小尺度的特征在逐层传播的过程中逐渐消失。
这篇文章提出的金字塔卷积网络, Convolutional Neural Pyramid(CNP),将CNN与图像处理中常用的尺度金字塔的概念结合了起来,能够在不显著增加计算量的情况下,扩大特征的感受野,同时保留不同尺度的特征,按照原文所给的实验结果,其图像修复、除噪、增强的效果和效率是明显优于其他的网络结构的。
论文概述
网络结构
先贴上最关键的网络结构图:
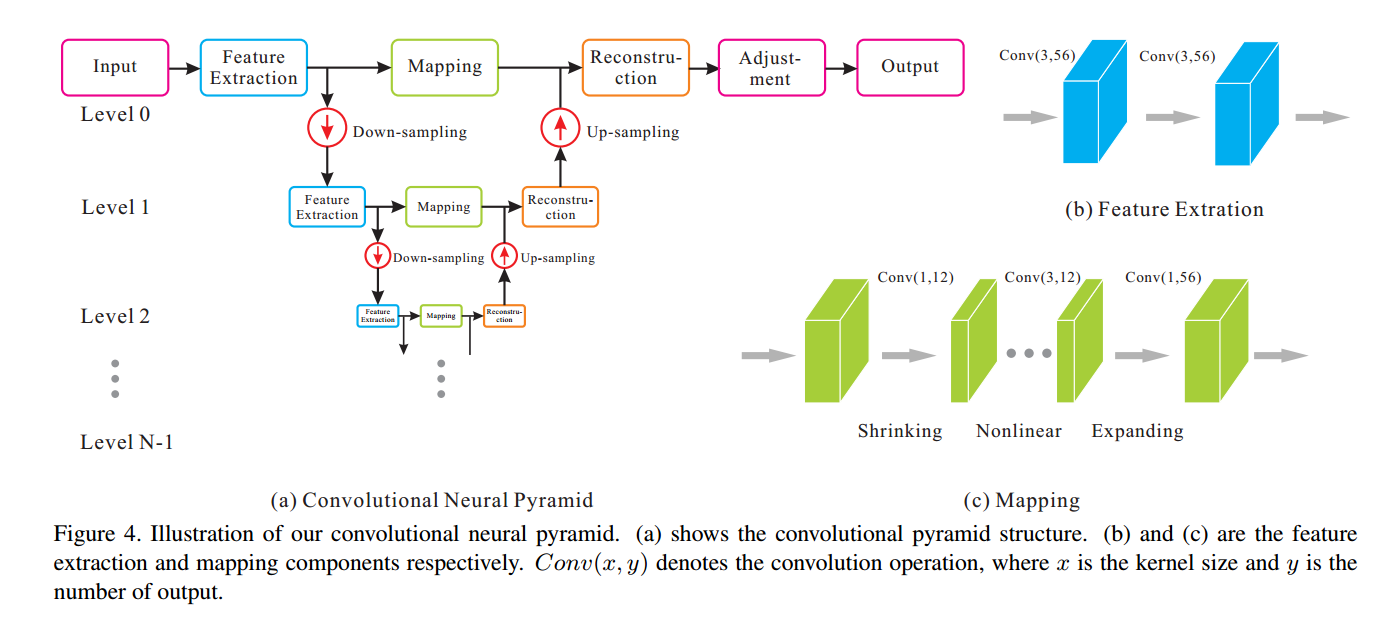
可以看到,CNP将网络分成了许多级,各级之内进行的是一样的运算:提取特征(Feature Extraction)、映射(mapping)、重建(Reconstruction)。
各级的编号从0开始到N-1,编号越大,其代表的级内特征的尺度越大,也就是感受野越大。特征通过下采样(Down-sampling)的方法从低层传递到高层,通过上采样(Up-sampling)从高层回到低层。
由于原文应用的目标是图像的还原,所以输出的尺寸需要调整。故在用CNP网络得到了特征之后添加了一个调整尺度的网络结构(Adjustment)
特征提取 – Feature Extraction
和网络结构图中(b)图表现的一样,每一个特征提取模块由两个使用了PReLU作为激活函数的卷积层组成。关于PReLU的信息,可以参照:深度学习——PReLU激活
卷积层使用的是3×3的卷积模板,输出为56维。按照网络结构,
这种结构的安排是该论文的创新点之一,即自适应网络深度(Adaptive depth)。按照一般经验,感受野越大,所描述的特征尺度越大,需要经过的卷积层也越多,但是也会带来更大的计算量;进行的降采样次数越多,特征的尺度越大,但是整体的数据尺寸会减小,同时减小了计算量。卷积层的增加和降采样的叠加在这一结构下同步进行,两者同时增大了特征的尺度,但是其计算量并没有显著增加,因为他们互相抵消了。
映射 –Mapping
映射模块由一个收缩层(Shrinking),
收缩层采用了
重建 –Reconstruction
重建操作是对第
下采样和上采样 –Down- and Up-sampling、
下采样
原文中的下采样比率为0.5, 并测试了两种下采样方法:最大池化和步长为2的卷积操作
For simplicity, we only consider resizing ratio 0.5 in our network. Two downsampling schemes
are tested – max pooling and convolution with a 3 × 3 kernel with stride 2. The simple max pooling works better in experiments due to preservation of the max response.
测试发现最大池化(max pooling)由于保存了图像的最大响应,其效果要优于步长为2的卷积操作。(而且计算量也更小)
上采样
上采样部分也是该论文的创新点之一。一般的“一步到位式”的上采样需要的卷积核的尺寸直接和采样输入和输出的大小有关。由于本文中的
所以该论文采用了渐进式上采样(Progressive Upsampling)方法,在第
这样的渐进式的上采样只需要很小的卷积核,计算简单,易于学习。
原文提到:
Further, information in level i − 1 is upsampled with the guidance from level i since the upsampling kernel is learned between the two neighboring levels.
以及
We simply implement the upsampling operation as a deconvolution layer in Caffe
显示出这一上采样的模板是可以通过学习优化的,而且内置于Caffe,这一学习的细节未在文中给出,本人对Caffe也没什么了解,所以还需要再加探索。
关于基于卷积核的上采样,可以参考:图像卷积与反卷积,有动图,很直观。
CNP整体算法

还是很简洁明了的。
测试部分
原文进行了大量的应用测试。
主要包括深度图像(Depth image)的修复及修复效果和CNP的级数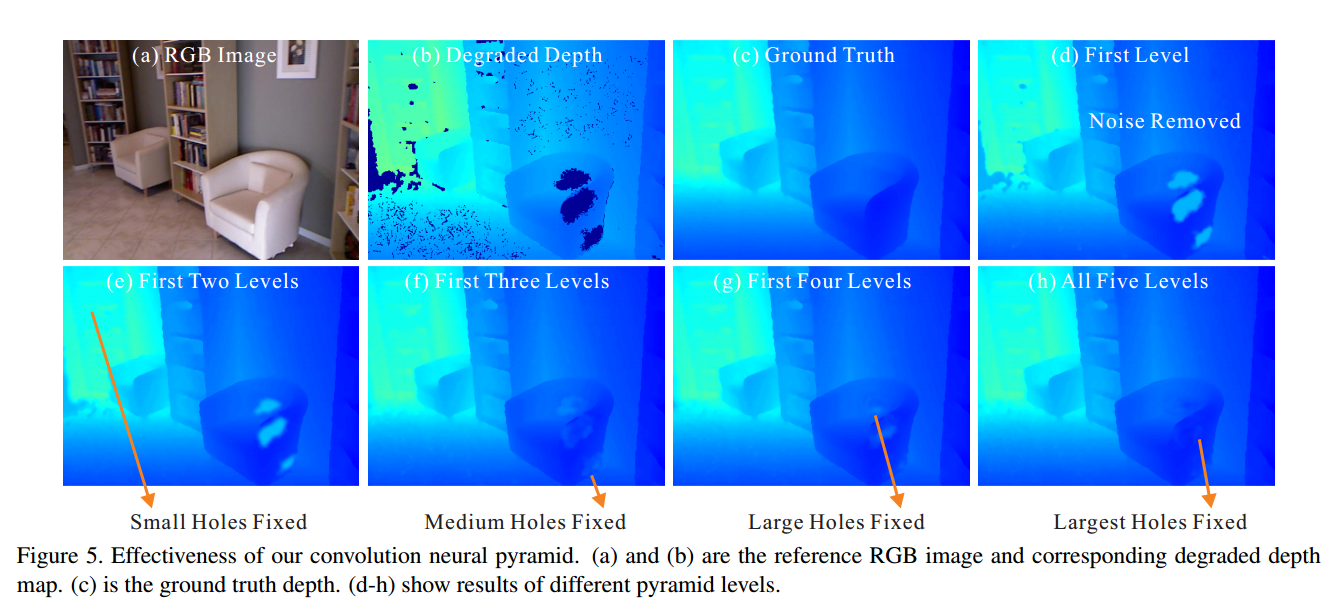
可以发现对大尺度的特征的调用能够显著地提升修复的效果。
同时也进行了除噪操作,其除噪效果明显要由于其他的方法。其中衡量除噪效果用了峰值信噪比(PSNR),可以参看峰值信噪比
学习总结
该论文致力于解决的是不同尺度的特征共存与计算量之间的妥协问题。
在传统的深度网络中,小尺度特征出现在靠前的网络中,大尺度特征出现在靠后的网络中,前者容易在网络层间传播的过程中逐渐消失,无法体现在最终的结果上。虽然当下热门的ResNet方案将不同层之间添加直连会一定程度解决这一问题,但是与此同时会使计算量的问题更加恶化。
CNP巧妙地将增加网络深度与降采样对特征尺度的增幅作用叠加,同时用两者对计算量的相反的影响互相抵消互补,使整体的计算量保持在一个较为恒定的范围。
所以,CNP方法对模式尺度差异问题的处理,很妙啊~
最后:

- 论文学习笔记: Convolutional Neural Pyramid for Image Processing
- RCNN学习笔记(1):《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》论文笔记
- 深度学习论文理解3:Flexible, high performance convolutional neural networks for image classification
- 【深度学习论文笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 深度学习论文笔记:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- [深度学习论文笔记][Image Classification] ImageNet Classification with Deep Convolutional Neural Networks
- 【论文笔记】Image Classification with Deep Convolutional Neural Network
- 《image Style Transfer Using Convolutional Neural Networks》论文笔记
- [深度学习论文笔记][Image Classification] Very Deep Convolutional Networks for Large-Scale Image Recognitio
- deeplearning论文学习笔记(1)Convolutional Neural Networks for Sentence Classification
- [深度学习论文笔记][Semantic Segmentation] Recurrent Convolutional Neural Networks for Scene Labeling
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 论文笔记《Convolutional Neural Networks for Sentence Classification》
- 【论文笔记】A Convolutional Neural Network Cascade for Face Detection
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 【论文笔记】Large-Margin Softmax Loss for Convolutional Neural Networks
- 论文笔记之Learning Convolutional Neural Networks for Graphs
- Java 网络IO编程总结(BIO、NIO、AIO均含完整实例代码)
- Java IO:BIO和NIO区别及各自应用场景
- 牛客网-剑指offer-22-从上往下打印二叉树
- 记录一个网易云IM和直播功能中,服务器API的Java调用代码
- Lvs的安装及负载均衡实现
- 论文学习笔记: Convolutional Neural Pyramid for Image Processing
- protractor元素无法点击
- discuz各个目录与文件的作用说明
- Continuous Subarray Sum
- 论文投稿-图片处理技巧
- Java高并发,如何解决,什么方式解决
- 面试常问问题:银行网上支付项目中怎么控制多线程高并发访问?
- animation 只触发一次的解决办法
- 深入剖析ConcurrentHashMap(1)


