RocketMQ原理
来源:互联网 发布:!=在c语言中是什么意思 编辑:程序博客网 时间:2024/06/05 06:12
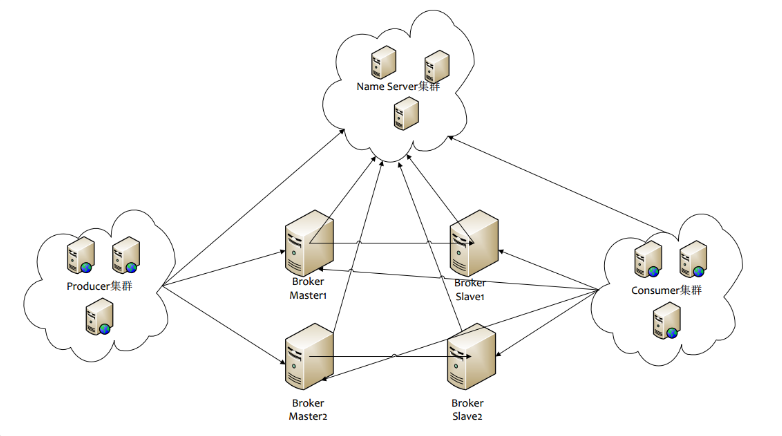
RocketMQ原理(1)——服务端组件介绍
RocketMQ服务端的组件有三个,NameServer,Broker,FilterServer(可选,部署于和Broker同一台机器)

Name Server
Name Server是RocketMQ的寻址服务。用于把Broker的路由信息做聚合。客户端依靠Name Server决定去获取对应topic的路由信息,从而决定对哪些Broker做连接。
Name Server是一个几乎无状态的结点,Name Server之间采取share-nothing的设计,互不通信。
对于一个Name Server集群列表,客户端连接Name Server的时候,只会选择随机连接一个结点,以做到负载均衡。
Name Server所有状态都从Broker上报而来,本身不存储任何状态,所有数据均在内存。
如果中途所有Name Server全都挂了,影响到路由信息的更新,不会影响和Broker的通信。
Broker
Broker是处理消息存储,转发等处理的服务器。
- Broker以group分开,每个group只允许一个master,若干个slave。
- 只有master才能进行写入操作,slave不允许。
- slave从master中同步数据。同步策略取决于master的配置,可以采用同步双写,异步复制两种。
- 客户端消费可以从master和slave消费。在默认情况下,消费者都从master消费,在master挂后,客户端由于从Name Server中感知到Broker挂机,就会从slave消费。
- Broker向所有的NameServer结点建立长连接,注册Topic信息。
Filter Server(可选)
RocketMQ可以允许消费者上传一个Java类给Filter Server进行过滤。
- Filter Server只能起在Broker所在的机器
- 可以有若干个Filter Server进程
- 拉取消息的时候,消息先经过Filter Server,Filter Server靠上传的Java类过滤消息后才推给Consumer消费。
- 客户端完全可以消费消息的时候做过滤,不需要Filter Server
- FilterServer存在的目的是用Broker的CPU资源换取网卡资源。因为Broker的瓶颈往往在网卡,而且CPU资源很闲。在客户端过滤会导致无需使用的消息在占用网卡资源。
- 使用 Java 类上传作为过滤表达式是一个双刃剑,一方面方便了应用的过滤操作且节省网卡资源,另一方面也带来了服务器端的安全风险,这需要足够谨慎,消费端上传的class要保证过滤的代码足够安全——例如在过滤程序里尽可能不做申请大内存,创建线程等操作,避免 Broker 服务器资源泄漏。
RocketMQ原理(2)——核心概念及术语
RocketMQ中有很多独有的概念,其中包括一些术语和角色。
理清楚基本的概念是理解原理的第一步,也是对排查生产问题找到线索的必要条件。
以下一一介绍笔者认为RocketMQ中最重要的一些概念和术语。
--------------------------------------------------------------------------------------------------------
角色:
Producer
生产者。发送消息的客户端角色。发送消息的时候需要指定Topic。
Consumer
消费者。消费消息的客户端角色。通常是后台处理异步消费的系统。 RocketMQ中Consumer有两种实现:PushConsumer和PullConsumer。
PushConsumer
推送模式(虽然RocketMQ使用的是长轮询)的消费者。消息的能及时被消费。使用非常简单,内部已处理如线程池消费、流控、负载均衡、异常处理等等的各种场景。
PullConsumer
拉取模式的消费者。应用主动控制拉取的时机,怎么拉取,怎么消费等。主动权更高。但要自己处理各种场景。
------------------------------------------------------------------------------------------------------------
概念术语
Producer Group
标识发送同一类消息的Producer,通常发送逻辑一致。发送普通消息的时候,仅标识使用,并无特别用处。若事务消息,如果某条发送某条消息的producer-A宕机,使得事务消息一直处于PREPARED状态并超时,则broker会回查同一个group的其 他producer,确认这条消息应该commit还是rollback。但开源版本并不完全支持事务消息(阉割了事务回查的代码)。
Consumer Group
标识一类Consumer的集合名称,这类Consumer通常消费一类消息,且消费逻辑一致。同一个Consumer Group下的各个实例将共同消费topic的消息,起到负载均衡的作用。
消费进度以Consumer Group为粒度管理,不同Consumer Group之间消费进度彼此不受影响,即消息A被Consumer Group1消费过,也会再给Consumer Group2消费。
注: RocketMQ要求同一个Consumer Group的消费者必须要拥有相同的注册信息,即必须要听一样的topic(并且tag也一样)。
Topic
标识一类消息的逻辑名字,消息的逻辑管理单位。无论消息生产还是消费,都需要指定Topic。
Tag
RocketMQ支持给在发送的时候给topic打tag,同一个topic的消息虽然逻辑管理是一样的。但是消费topic1的时候,如果你订阅的时候指定的是tagA,那么tagB的消息将不会投递。
Message Queue
简称Queue或Q。消息物理管理单位。一个Topic将有若干个Q。若Topic同时创建在不同的Broker,则不同的broker上都有若干Q,消息将物理地存储落在不同Broker结点上,具有水平扩展的能力。
无论生产者还是消费者,实际的生产和消费都是针对Q级别。例如Producer发送消息的时候,会预先选择(默认轮询)好该Topic下面的某一条Q地发送;Consumer消费的时候也会负载均衡地分配若干个Q,只拉取对应Q的消息。
每一条message queue均对应一个文件,这个文件存储了实际消息的索引信息。并且即使文件被删除,也能通过实际纯粹的消息文件(commit log)恢复回来。
Offset
RocketMQ中,有很多offset的概念。但通常我们只关心暴露到客户端的offset。一般我们不特指的话,就是指逻辑Message Queue下面的offset。
可以认为一条逻辑的message queue是无限长的数组。一条消息进来下标就会涨1。下标就是offset。
一条message queue中的max offset表示消息的最大offset。注:这里从源码上看,max_offset并不是最新的那条消息的offset,而是表示最新消息的offset+1。
而min offset则标识现存在的最小offset。
由于消息存储一段时间后,消费会被物理地从磁盘删除,message queue的min offset也就对应增长。这意味着比min offset要小的那些消息已经不在broker上了,无法被消费。
Consumer Offset
用于标记Consumer Group在一条逻辑Message Queue上,消息消费到哪里了。注:从源码上看,这个数值是最新消费的那条消息的offset+1,所以实际上这个值存储的是【下次拉取的话,从哪里开始拉取的offset】。
消费者拉取消息的时候需要指定offset,broker不主动推送消息,而是接受到请求的时候把存储的对应offset的消息返回给客户端。这个offset在成功消费后会更新到内存,并定时持久化。在集群消费模式下,会同步持久化到broker。在广播模式下,会持久化到本地文件。
实例重启的时候会获取持久化的consumer offset,用以决定从哪里开始消费。
集群消费
消费者的一种消费模式。一个Consumer Group中的各个Consumer实例分摊去消费消息,即一条消息只会投递到一个Consumer Group下面的一个实例。
实际上,每个Consumer是平均分摊Message Queue的去做拉取消费。例如某个Topic有3条Q,其中一个Consumer Group 有 3 个实例(可能是 3 个进程,或者 3 台机器),那么每个实例只消费其中的1条Q。
而由Producer发送消息的时候是轮询所有的Q,所以消息会平均散落在不同的Q上,可以认为Q上的消息是平均的。那么实例也就平均地消费消息了。
这种模式下,消费进度的存储会持久化到Broker。
广播消费
消费者的一种消费模式。消息将对一个Consumer Group下的各个Consumer实例都投递一遍。即即使这些 Consumer 属于同一个Consumer Group,消息也会被Consumer Group 中的每个Consumer都消费一次。
实际上,是一个消费组下的每个消费者实例都获取到了topic下面的每个Message Queue去拉取消费。所以消息会投递到每个消费者实例。
这种模式下,消费进度会存储持久化到实例本地。
顺序消息
消费消息的顺序要同发送消息的顺序一致。由于Consumer消费消息的时候是针对Message Queue顺序拉取并开始消费,且一条Message Queue只会给一个消费者(集群模式下),所以能够保证同一个消费者实例对于Q上消息的消费是顺序地开始消费(不一定顺序消费完成,因为消费可能并行)。
在RocketMQ中,顺序消费主要指的是都是Queue级别的局部顺序。这一类消息为满足顺序性,必须Producer单线程顺序发送,且发送到同一个队列,这样Consumer就可以按照Producer发送的顺序去消费消息。
生产者发送的时候可以用MessageQueueSelector为某一批消息(通常是有相同的唯一标示id)选择同一个Queue,则这一批消息的消费将是顺序消息(并由同一个consumer完成消息)。或者Message Queue的数量只有1,但这样消费的实例只能有一个,多出来的实例都会空跑。
普通顺序消息
顺序消息的一种,正常情况下可以保证完全的顺序消息,但是一旦发生异常,Broker宕机或重启,由于队列总数发生发化,消费者会触发负载均衡,而默认地负载均衡算法采取哈希取模平均,这样负载均衡分配到定位的队列会发化,使得队列可能分配到别的实例上,则会短暂地出现消息顺序不一致。
如果业务能容忍在集群异常情况(如某个 Broker 宕机或者重启)下,消息短暂的乱序,使用普通顺序方式比较合适。
严格顺序消息
顺序消息的一种,无论正常异常情况都能保证顺序,但是牺牲了分布式 Failover 特性,即 Broker集群中只要有一台机器不可用,则整个集群都不可用,服务可用性大大降低。
如果服务器部署为同步双写模式,此缺陷可通过备机自动切换为主避免,不过仍然会存在几分钟的服务不可用。(依赖同步双写,主备自动切换,自动切换功能目前并未实现)
RocketMQ原理(3)——水平扩展及负载均衡详解
RocketMQ是一个分布式具有高度可扩展性的消息中间件。本文旨在探索在broker端,生产端,以及消费端是如何做到横向扩展以及负载均衡的。
Broker端水平扩展
Broker负载均衡
Broker是以group为单位提供服务。一个group里面分master和slave,master和slave存储的数据一样,slave从master同步数据(同步双写或异步复制看配置)。
通过nameserver暴露给客户端后,只是客户端关心(注册或发送)一个个的topic路由信息。路由信息中会细化为message queue的路由信息。而message queue会分布在不同的broker group。所以对于客户端来说,分布在不同broker group的message queue为成为一个服务集群,但客户端会把请求分摊到不同的queue。
而由于压力分摊到了不同的queue,不同的queue实际上分布在不同的Broker group,也就是说压力会分摊到不同的broker进程,这样消息的存储和转发均起到了负载均衡的作用。
Broker一旦需要横向扩展,只需要增加broker group,然后把对应的topic建上,客户端的message queue集合即会变大,这样对于broker的负载则由更多的broker group来进行分担。
并且由于每个group下面的topic的配置都是独立的,也就说可以让group1下面的那个topic的queue数量是4,其他group下的topic queue数量是2,这样group1则得到更大的负载。
commit log
虽然每个topic下面有很多message queue,但是message queue本身并不存储消息。真正的消息存储会写在CommitLog的文件,message queue只是存储CommitLog中对应的位置信息,方便通过message queue找到对应存储在CommitLog的消息。
不同的topic,message queue都是写到相同的CommitLog 文件,也就是说CommitLog完全的顺序写。
具体如下图:

Producer
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下,如下图:

Consumer负载均衡
集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
默认的分配算法是AllocateMessageQueueAveragely,如下图:

还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式,如下图:

需要注意的是,集群模式下,queue都是只允许分配只一个实例,这是由于如果多个实例同时消费一个queue的消息,由于拉取哪些消息是consumer主动控制的,那样会导致同一个消息在不同的实例下被消费多次,所以算法上都是一个queue只分给一个consumer实例,一个consumer实例可以允许同时分到不同的queue。
通过增加consumer实例去分摊queue的消费,可以起到水平扩展的消费能力的作用。而有实例下线的时候,会重新触发负载均衡,这时候原来分配到的queue将分配到其他实例上继续消费。
但是如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用了。所以需要控制让queue的总数量大于等于consumer的数量。
广播模式
由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。
在实现上,其中一个不同就是在consumer分配queue的时候,会所有consumer都分到所有的queue。

RocketMQ原理(4)——消息ACK机制及消费进度管理
https://zhuanlan.zhihu.com/p/25140744 中剖析过,consumer的每个实例是靠队列分配来决定如何消费消息的。那么消费进度具体是如何管理的,又是如何保证消息成功消费的(RocketMQ有保证消息肯定消费成功的特性(失败则重试)?
本文将详细解析消息具体是如何ack的,又是如何保证消费肯定成功的。
由于以上工作所有的机制都实现在PushConsumer中,所以本文的原理均只适用于RocketMQ中的PushConsumer即Java客户端中的DefaultPushConsumer。 若使用了PullConsumer模式,类似的工作如何ack,如何保证消费等均需要使用方自己实现。
注:广播消费和集群消费的处理有部分区别,以下均特指集群消费(CLSUTER),广播(BROADCASTING)下部分可能不适用。
保证消费成功
PushConsumer为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。
消费的时候,我们需要注入一个消费回调,具体sample代码如下:
consumer.registerMessageListener(new MessageListenerConcurrently() { @Override public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) { System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs); doMyJob();//执行真正消费 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; } });业务实现消费回调的时候,当且仅当此回调函数返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS,RocketMQ才会认为这批消息(默认是1条)是消费完成的。(具体如何ACK见后面章节)
如果这时候消息消费失败,例如数据库异常,余额不足扣款失败等一切业务认为消息需要重试的场景,只要返回ConsumeConcurrentlyStatus.RECONSUME_LATER,RocketMQ就会认为这批消息消费失败了。
为了保证消息是肯定被至少消费成功一次,RocketMQ会把这批消息重发回Broker(topic不是原topic而是这个消费租的RETRY topic),在延迟的某个时间点(默认是10秒,业务可设置)后,再次投递到这个ConsumerGroup。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。应用可以监控死信队列来做人工干预。
注:
- 如果业务的回调没有处理好而抛出异常,会认为是消费失败当ConsumeConcurrentlyStatus.RECONSUME_LATER处理。
- 当使用顺序消费的回调MessageListenerOrderly时,由于顺序消费是要前者消费成功才能继续消费,所以没有RECONSUME_LATER的这个状态,只有SUSPEND_CURRENT_QUEUE_A_MOMENT来暂停队列的其余消费,直到原消息不断重试成功为止才能继续消费。
启动的时候从哪里消费
当新实例启动的时候,PushConsumer会拿到本消费组broker已经记录好的消费进度(consumer offset),按照这个进度发起自己的第一次Pull请求。
如果这个消费进度在Broker并没有存储起来,证明这个是一个全新的消费组,这时候客户端有几个策略可以选择:
CONSUME_FROM_LAST_OFFSET //默认策略,从该队列最尾开始消费,即跳过历史消息CONSUME_FROM_FIRST_OFFSET //从队列最开始开始消费,即历史消息(还储存在broker的)全部消费一遍CONSUME_FROM_TIMESTAMP//从某个时间点开始消费,和setConsumeTimestamp()配合使用,默认是半个小时以前所以,社区中经常有人问:“为什么我设了CONSUME_FROM_LAST_OFFSET,历史的消息还是被消费了”? 原因就在于只有全新的消费组才会使用到这些策略,老的消费组都是按已经存储过的消费进度继续消费。
对于老消费组想跳过历史消息可以采用以下两种方法:
- 代码按照日期判断,太老的消息直接return CONSUME_SUCCESS过滤。
- 代码判断消息的offset和MAX_OFFSET相差很远,认为是积压了很多,直接return CONSUME_SUCCESS过滤。
- 消费者启动前,先调整该消费组的消费进度,再开始消费。可以人工使用命令resetOffsetByTime,或调用内部的运维接口,祥见ResetOffsetByTimeCommand.java
消息ACK机制
RocketMQ是以consumer group+queue为单位是管理消费进度的,以一个consumer offset标记这个这个消费组在这条queue上的消费进度。
如果某已存在的消费组出现了新消费实例的时候,依靠这个组的消费进度,就可以判断第一次是从哪里开始拉取的。
每次消息成功后,本地的消费进度会被更新,然后由定时器定时同步到broker,以此持久化消费进度。
但是每次记录消费进度的时候,只会把一批消息中最小的offset值为消费进度值,如下图:

这钟方式和传统的一条message单独ack的方式有本质的区别。性能上提升的同时,会带来一个潜在的重复问题——由于消费进度只是记录了一个下标,就可能出现拉取了100条消息如 2101-2200的消息,后面99条都消费结束了,只有2101消费一直没有结束的情况。
在这种情况下,RocketMQ为了保证消息肯定被消费成功,消费进度职能维持在2101,直到2101也消费结束了,本地的消费进度才会一下子更新到2200。
在这种设计下,就有消费大量重复的风险。如2101在还没有消费完成的时候消费实例突然退出(机器断电,或者被kill)。这条queue的消费进度还是维持在2101,当queue重新分配给新的实例的时候,新的实例从broker上拿到的消费进度还是维持在2101,这时候就会又从2101开始消费,2102-2200这批消息实际上已经被消费过还是会投递一次。
对于这个场景,3.2.6之前的RocketMQ无能为力,所以业务必须要保证消息消费的幂等性,这也是RocketMQ官方多次强调的态度。
实际上,从源码的角度上看,RocketMQ可能是考虑过这个问题的,截止到3.2.6的版本的源码中,可以看到为了缓解这个问题的影响面,DefaultMQPushConsumer中有个配置consumeConcurrentlyMaxSpan
/** * Concurrently max span offset.it has no effect on sequential consumption */private int consumeConcurrentlyMaxSpan = 2000;这个值默认是2000,当RocketMQ发现本地缓存的消息的最大值-最小值差距大于这个值(2000)的时候,会触发流控——也就是说如果头尾都卡住了部分消息,达到了这个阈值就不再拉取消息。
但作用实际很有限,像刚刚这个例子,2101的消费是死循环,其他消费非常正常的话,是无能为力的。一旦退出,在不人工干预的情况下,2101后所有消息全部重复。
Ack卡进度解决方案
对于这个卡消费进度的问题,最显而易见的解法是设定一个超时时间,达到超时时间的那个消费当作消费失败处理。
后来RocketMQ显然也发现了这个问题,而RocketMQ在3.5.8之后也就是采用这样的方案去解决这个问题。
- 在pushConsumer中 有一个consumeTimeout字段(默认15分钟),用于设置最大的消费超时时间。消费前会记录一个消费的开始时间,后面用于比对。
- 消费者启动的时候,会定期扫描所有消费的消息,达到这个timeout的那些消息,就会触发sendBack并ack的操作。这里扫描的间隔也是consumeTimeout(单位分钟)的间隔。
核心源码如下:
//ConsumeMessageConcurrentlyService.javapublic void start() { this.CleanExpireMsgExecutors.scheduleAtFixedRate(new Runnable() { @Override public void run() { cleanExpireMsg(); } }, this.defaultMQPushConsumer.getConsumeTimeout(), this.defaultMQPushConsumer.getConsumeTimeout(), TimeUnit.MINUTES);}//ConsumeMessageConcurrentlyService.javaprivate void cleanExpireMsg() { Iterator<Map.Entry<MessageQueue, ProcessQueue>> it = this.defaultMQPushConsumerImpl.getRebalanceImpl().getProcessQueueTable().entrySet().iterator(); while (it.hasNext()) { Map.Entry<MessageQueue, ProcessQueue> next = it.next(); ProcessQueue pq = next.getValue(); pq.cleanExpiredMsg(this.defaultMQPushConsumer); }}//ProcessQueue.javapublic void cleanExpiredMsg(DefaultMQPushConsumer pushConsumer) { if (pushConsumer.getDefaultMQPushConsumerImpl().isConsumeOrderly()) { return; } int loop = msgTreeMap.size() < 16 ? msgTreeMap.size() : 16; for (int i = 0; i < loop; i++) { MessageExt msg = null; try { this.lockTreeMap.readLock().lockInterruptibly(); try { if (!msgTreeMap.isEmpty() && System.currentTimeMillis() - Long.parseLong(MessageAccessor.getConsumeStartTimeStamp(msgTreeMap.firstEntry().getValue())) > pushConsumer.getConsumeTimeout() * 60 * 1000) { msg = msgTreeMap.firstEntry().getValue(); } else { break; } } finally { this.lockTreeMap.readLock().unlock(); } } catch (InterruptedException e) { log.error("getExpiredMsg exception", e); } try { pushConsumer.sendMessageBack(msg, 3); log.info("send expire msg back. topic={}, msgId={}, storeHost={}, queueId={}, queueOffset={}", msg.getTopic(), msg.getMsgId(), msg.getStoreHost(), msg.getQueueId(), msg.getQueueOffset()); try { this.lockTreeMap.writeLock().lockInterruptibly(); try { if (!msgTreeMap.isEmpty() && msg.getQueueOffset() == msgTreeMap.firstKey()) { try { msgTreeMap.remove(msgTreeMap.firstKey()); } catch (Exception e) { log.error("send expired msg exception", e); } } } finally { this.lockTreeMap.writeLock().unlock(); } } catch (InterruptedException e) { log.error("getExpiredMsg exception", e); } } catch (Exception e) { log.error("send expired msg exception", e); } }}通过源码看这个方案,其实可以看出有几个不太完善的问题:
- 消费timeout的时间非常不精确。由于扫描的间隔是15分钟,所以实际上触发的时候,消息是有可能卡住了接近30分钟(15*2)才被清理。
- 由于定时器一启动就开始调度了,中途这个consumeTimeout再更新也不会生效。
RocketMQ(5)——消息文件过期原理
RocketMQ原理(4)--消息ACK机制及消费进度管理 - 知乎专栏文中提过,所有的消费均是客户端发起Pull请求的,告诉消息的offset位置,broker去查询并返回。但是有一点需要非常明确的是,消息消费后,消息其实并没有物理地被清除,这是一个非常特殊的设计。本文来探索此设计的一些细节。
消费完后的消息去哪里了?
消息的存储是一直存在于CommitLog中的,由于CommitLog是以文件为单位(而非消息)存在的,而且CommitLog的设计是只允许顺序写,且每个消息大小不定长,所以这决定了消息文件几乎不可能按照消息为单位删除(否则性能会极具下降,逻辑也非常复杂)。
所以消息被消费了,消息所占据的物理空间也不会立刻被回收。但消息既然一直没有删除,那RocketMQ怎么知道应该投递过的消息就不再投递?——答案是客户端自身维护——客户端拉取完消息之后,在响应体中,broker会返回下一次应该拉取的位置,PushConsumer通过这一个位置,更新自己下一次的pull请求。这样就保证了正常情况下,消息只会被投递一次。
什么时候清理物理消息文件?
那消息文件到底删不删,什么时候删?
消息存储在CommitLog之后,的确是会被清理的,但是这个清理只会在以下任一条件成立才会批量删除消息文件(CommitLog):
- 消息文件过期(默认72小时),且到达清理时点(默认是凌晨4点),删除过期文件。
- 消息文件过期(默认72小时),且磁盘空间达到了水位线(默认75%),删除过期文件。
- 磁盘已经达到必须释放的上限(85%水位线)的时候,则开始批量清理文件(无论是否过期),直到空间充足。
注:若磁盘空间达到危险水位线(默认90%),出于保护自身的目的,broker会拒绝写入服务。
这样设计带来的好处
消息的物理文件一直存在,消费逻辑只是听客户端的决定而搜索出对应消息进行,这样做,笔者认为,有以下几个好处:
一个消息很可能需要被N个消费组(设计上很可能就是系统)消费,但消息只需要存储一份,消费进度单独记录即可。这给强大的消息堆积能力提供了很好的支持——一个消息无需复制N份,就可服务N个消费组。
由于消费从哪里消费的决定权一直都是客户端决定,所以只要消息还在,就可以消费到,这使得RocketMQ可以支持其他传统消息中间件不支持的回溯消费。即我可以通过设置消费进度回溯,就可以让我的消费组重新像放快照一样消费历史消息;或者我需要另一个系统也复制历史的数据,只需要另起一个消费组从头消费即可(前提是消息文件还存在)。
消息索引服务。只要消息还存在就能被搜索出来。所以可以依靠消息的索引搜索出消息的各种原信息,方便事后排查问题。
注:在消息清理的时候,由于消息文件默认是1GB,所以在清理的时候其实是在删除一个大文件操作,这对于IO的压力是非常大的,这时候如果有消息写入,写入的耗时会明显变高。这个现象可以在凌晨4点(默认删时间时点)后的附近观察得到。
RocketMQ官方建议Linux下文件系统改为Ext4,对于文件删除操作,相比Ext3有非常明显的提升。
跳过历史消息的处理
由于消息本身是没有过期的概念,只有文件才有过期的概念。那么对于很多业务场景——一个消息如果太老,是无需要被消费的,是不合适的。
这种需要跳过历史消息的场景,在RocketMQ要怎么实现呢?
对于一个全新的消费组,PushConsumer默认就是跳过以前的消息而从最尾开始消费的,解析请参看 https://zhuanlan.zhihu.com/p/25265380 相关章节。
但对于已存在的消费组,RocketMQ没有内置的实现,但有以下手段可以解决:
自身的消费代码按照日期过滤,太老的消息直接过滤。如:
@Override public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) { for(MessageExt msg: msgs){ if(System.currentTimeMillis()-msg.getBornTimestamp()>60*1000) {//一分钟之前的认为过期 continue;//过期消息跳过 } //do consume here } return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; }自身的消费代码代码判断消息的offset和MAX_OFFSET相差很远,认为是积压了很多,直接return CONSUME_SUCCESS过滤。
@Override public ConsumeConcurrentlyStatus consumeMessage(// List<MessageExt> msgs, // ConsumeConcurrentlyContext context) { long offset = msgs.get(0).getQueueOffset(); String maxOffset = msgs.get(0).getProperty(MessageConst.PROPERTY_MAX_OFFSET); long diff = Long. parseLong(maxOffset) - offset; if (diff > 100000) { //消息堆积了10W情况的特殊处理 return ConsumeConcurrentlyStatus. CONSUME_SUCCESS; } //do consume here return ConsumeConcurrentlyStatus. CONSUME_SUCCESS; }消费者启动前,先调整该消费组的消费进度,再开始消费。可以人工使用控制台命令resetOffsetByTime把消费进度调整到后面,再启动消费。
- 原理同3,但使用代码来控制。代码中调用内部的运维接口,具体代码实例祥见ResetOffsetByTimeCommand.java.
} else {//key topic不存在,创建失败 LOG.warn("Create new topic failed, because the default topic[{}] not exist. producer:[{}]", defaultTopic, remoteAddress); } ...//把创建的topic维护起来总的来说,这个功能设计出来比较晦涩,而从运维的角度上看,topic在大部分场景下也应该预创建,故本特性没有必要的话,也不会用到,这个配置也没有必要特殊设置。
关于这个TBW102非常不直观的问题,我已经提了issue :Rename DEFAULT_TOPIC
defaultTopicQueueNums
配置说明:自动创建topic的话,默认queue数量是多少
默认值:4
sendMsgTimeout
配置说明:默认的发送超时时间 3000
默认值:单位毫秒
若发送的时候不显示指定timeout,则使用此设置的值作为超时时间。
对于异步发送,超时后会进入回调的onException,对于同步发送,超时则会得到一个RemotingTimeoutException。
compressMsgBodyOverHowmuch
配置说明:消息body需要压缩的阈值
默认值:1024 * 4,4K
retryTimesWhenSendFailed
配置说明:同步发送失败的话,rocketmq内部重试多少次
默认值:2
retryTimesWhenSendAsyncFailed
配置说明:异步发送失败的话,rocketmq内部重试多少次
默认值:2
retryAnotherBrokerWhenNotStoreOK
配置说明:发送的结果如果不是SEND_OK状态,是否当作失败处理而尝试重发
默认值:false
发送结果总共有4钟:
SEND_OK, //状态成功,无论同步还是存储FLUSH_DISK_TIMEOUT, // broker刷盘策略为同步刷盘(SYNC_FLUSH)的话时候,等待刷盘的时候超时FLUSH_SLAVE_TIMEOUT, // master role采取同步复制策略(SYNC_MASTER)的时候,消息尝试同步到slave超时SLAVE_NOT_AVAILABLE, //slave不可用注:从源码上看,此配置项只对同步发送有效,异步、oneway(由于无法获取结果,肯定无效)均无效
maxMessageSize
配置说明:客户端验证,允许发送的最大消息体大小
默认值:1024 * 1024 * 4,4M
若消息体大小超过此,会得到一个响应码13(MESSAGE_ILLEGAL)的MQClientException异常
-----------------------------------------------------------------------------------
TransactionMQProducer
事务生产者,截至至4.1,由于暂时事务回查功能缺失,整体并不完全可用,配置暂时忽略,等后面功能完善后补上。
4.2计划:Support distributed transaction messaging
-----------------------------------------------------------------------------------
DefaultMQPushConsumer
最常用的消费者,使用push模式(长轮询),封装了各种拉取的方法和返回结果的判断。下面介绍其配置。
consumerGroup*
配置说明:消费组的名称,用于标识一类消费者
默认值:无默认值,必设
详见 RocketMQ原理(2)--核心概念及术语 - 知乎专栏
messageModel*
配置说明:消费模式
默认值:MessageModel.CLUSTERING
可选值有两个:
- CLUSTERING //集群消费模式
- BROADCASTING //广播消费模式
两种模式的区别详见:RocketMQ原理(2)--核心概念及术语 - 知乎专栏
consumeFromWhere*
配置说明:启动消费点策略
默认值:ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET
可选值有三个:
- CONSUME_FROM_LAST_OFFSET //队列尾消费
- CONSUME_FROM_FIRST_OFFSET //队列头消费
- CONSUME_FROM_TIMESTAMP //按照日期选择某个位置消费
注:此策略只生效于新在线测consumer group,如果是老的已存在的consumer group,都降按照已经持久化的consume offset进行消费
具体说明祥见: RocketMQ原理(4)--消息ACK机制及消费进度管理 - 知乎专栏
consumeTimestamp:
配置说明:CONSUME_FROM_LAST_OFFSET的时候使用,从哪个时间点开始消费
默认值:半小时前
格式为yyyyMMddhhmmss 如 20131223171201
allocateMessageQueueStrategy*
配置说明:负载均衡策略算法
默认值:AllocateMessageQueueAveragely(取模平均分配)
这个算法可以自行扩展以使用自定义的算法,目前内置的有以下算法可以使用
- AllocateMessageQueueAveragely //取模平均
- AllocateMessageQueueAveragelyByCircle //环形平均
- AllocateMessageQueueByConfig // 按照配置,传入听死的messageQueueList
- AllocateMessageQueueByMachineRoom //按机房,从源码上看,必须和阿里的某些broker命名一致才行
- AllocateMessageQueueConsistentHash //一致性哈希算法,本人于4.1提交的特性。用于解决“惊群效应”。
需要自行扩展的算法的,需要实现org.apache.rocketmq.client.consumer.rebalance.AllocateMessageQueueStrategy
具体分配consume queue的过程祥见: RocketMQ原理(3)--水平扩展及负载均衡详解 - 知乎专栏
subscription
配置说明:订阅关系(topic->sub expression)
默认值:{}
不建议设置,订阅topic建议直接调用subscribe接口
messageListener
配置说明:消息处理监听器(回调)
默认值:null
不建议设置,注册监听的时候应调用registerMessageListener
offsetStore
配置说明:消息消费进度存储器
默认值:null
不建议设置,offsetStore 有两个策略:LocalFileOffsetStore 和 RemoteBrokerOffsetStore。
若没有显示设置的情况下,广播模式将使用LocalFileOffsetStore,集群模式将使用RemoteBrokerOffsetStore,不建议修改。
consumeThreadMin*
配置说明:消费线程池的core size
默认值:20
PushConsumer会内置一个消费线程池,这个配置控制此线程池的core size
consumeThreadMax*
配置说明:消费线程池的max size
默认值:64
PushConsumer会内置一个消费线程池,这个配置控制此线程池的max size
adjustThreadPoolNumsThreshold
配置说明:动态扩线程核数的消费堆积阈值
默认值:1000
相关功能以废弃,不建议设置
consumeConcurrentlyMaxSpan
配置说明:并发消费下,单条consume queue队列允许的最大offset跨度,达到则触发流控
默认值:2000
注:只对并发消费(ConsumeMessageConcurrentlyService)生效
更多分析祥见: RocketMQ原理(4)--消息ACK机制及消费进度管理 - 知乎专栏
pullThresholdForQueue
配置说明:consume queue流控的阈值
默认值:1000
每条consume queue的消息拉取下来后会缓存到本地,消费结束会删除。当累积达到一个阈值后,会触发该consume queue的流控。
更多分析祥见: RocketMQ原理(4)--消息ACK机制及消费进度管理 - 知乎专栏
截至到4.1,流控级别只能针对consume queue级别,针对topic级别的流控已经提了issue: Add flow control on topic level
pullInterval*
配置说明:拉取的间隔
默认值:0,单位毫秒
由于RocketMQ采取的pull的方式进行消息投递,每此会发起一个异步pull请求,得到请求后会再发起下次请求,这个间隔默认是0,表示立刻再发起。在间隔为0的场景下,消息投递的及时性几乎等同用Push实现的机制。
pullBatchSize*
配置说明:一次最大拉取的批量大小
默认值:32
每次发起pull请求到broker,客户端需要指定一个最大batch size,表示这次拉取消息最多批量拉取多少条。
consumeMessageBatchMaxSize
配置说明:批量消费的最大消息条数
默认值:1
你可能发现了,RocketMQ的注册监听器回调的回调方法签名是类似这样的:
ConsumeConcurrentlyStatus consumeMessage(final List<MessageExt> msgs, final ConsumeConcurrentlyContext context);里面的消息是一个集合List而不是单独的msg,这个consumeMessageBatchMaxSize就是控制这个集合的最大大小。
而由于拉取到的一批消息会立刻拆分成N(取决于consumeMessageBatchMaxSize)批消费任务,所以集合中msgs的最大大小是consumeMessageBatchMaxSize和pullBatchSize的较小值。
postSubscriptionWhenPull
配置说明:每次拉取的时候是否更新订阅关系
默认值:false
从源码上看,这个值若是true,且不是class fliter模式,则每次拉取的时候会把subExpression带上到pull的指令中,broker发现这个指令会根据这个上传的表达式重新build出注册数据,而不是直接使用读取的缓存数据。
maxReconsumeTimes
配置说明:一个消息如果消费失败的话,最多重新消费多少次才投递到死信队列
默认值:-1
注:这个值默认值虽然是-1,但是实际使用的时候默认并不是-1。按照消费是并行还是串行消费有所不同的默认值。
- 并行:默认16次
- 串行:默认无限大(Interge.MAX_VALUE)。由于顺序消费的特性必须等待前面的消息成功消费才能消费后面的,默认无限大即一直不断消费直到消费完成。
suspendCurrentQueueTimeMillis
配置说明:串行消费使用,如果返回ROLLBACK或者SUSPEND_CURRENT_QUEUE_A_MOMENT,再次消费的时间间隔
默认值:1000,单位毫秒
注:如果消费回调中对ConsumeOrderlyContext中的suspendCurrentQueueTimeMillis进行过设置,则使用用户设置的值作为消费间隔。
consumeTimeout
配置说明:消费的最长超时时间
默认值:15,单位分钟
如果消费超时,RocketMQ会等同于消费失败来处理,更多分析祥见: RocketMQ原理(4)--消息ACK机制及消费进度管理 - 知乎专栏
--------------------------------------------------------------------
DefaultMQPullConsumer
采取主动调用Pull接口的模式的消费者,主动权更大,但是使用难度也相对更大。以下介绍其配置,部分配置和PushConsumer一致。
consumerGroup*
配置说明:消费组的名称,用于标识一类消费者
默认值:无默认值,必设
详见 RocketMQ原理(2)--核心概念及术语 - 知乎专栏
registerTopics*
配置说明:消费者需要监听的topic
默认值:空集合
由于没有subscribe接口,用户需要自己把想要监听的topic设置到此集合中,RocketMQ内部会依靠此来发送对应心跳数据。
messageModel*
配置说明:消费模式
默认值:MessageModel.CLUSTERING
可选值有两个:
- CLUSTERING //集群消费模式
- BROADCASTING //广播消费模式
两种模式的区别详见:RocketMQ原理(2)--核心概念及术语 - 知乎专栏
allocateMessageQueueStrategy*
配置说明:负载均衡策略算法
默认值:AllocateMessageQueueAveragely(取模平均分配)
见DefaultPushConsumer的说明
offsetStore
配置说明:消息消费进度存储器
默认值:null
不建议设置,offsetStore 有两个策略:LocalFileOffsetStore 和 RemoteBrokerOffsetStore。
若没有显示设置的情况下,广播模式将使用LocalFileOffsetStore,集群模式将使用RemoteBrokerOffsetStore,不建议修改。
maxReconsumeTimes
配置说明:调用sendMessageBack的时候,如果发现重新消费超过这个配置的值,则投递到死信队列
默认值:16
由于PullConsumer没有管理消费的线程池和管理器,需要用户自己处理各种消费结果和拉取结果,故需要投递到重试队列或死信队列的时候需要显示调用sendMessageBack。
回传消息的时候会带上maxReconsumeTimes的值,broker发现此消息已经消费超过此值,则投递到死信队列,否则投递到重试队列。此逻辑和DefaultPushConsumer是一致的,只是PushConsumer无需用户显示调用。
brokerSuspendMaxTimeMillis
配置说明:broker在长轮询下,连接最长挂起的时间
默认值:20*1000,单位毫秒
长轮询具体逻辑不在本文论述,且RocketMQ不建议修改此值。
consumerTimeoutMillisWhenSuspend
配置说明:broker在长轮询下,客户端等待broker响应的最长等待超时时间
默认值:30*1000,单位毫秒
长轮询具体逻辑不在本文论述,且RocketMQ不建议修改此值,此值一定要大于brokerSuspendMaxTimeMillis
consumerPullTimeoutMillis
配置说明:pull的socket 超时时间
默认值:10*1000,单位毫秒
虽然注释上说是socket超时时间,但是从源码上看,此值的设计是不启动长轮询也不指定timeout的情况下,拉取的超时时间。
messageQueueListener
配置说明:负载均衡consume queue分配变化的通知监听器
默认值:null
由于pull操作需要用户自己去触发,故如果负载均衡发生变化,要有方法告知用户现在分到的新consume queue是什么。使用方可以实现此接口以达到此目的:
/** * A MessageQueueListener is implemented by the application and may be specified when a message queue changed */public interface MessageQueueListener {/** * @param topic message topic * @param mqAll all queues in this message topic * @param mqDivided collection of queues,assigned to the current consumer */void messageQueueChanged(final String topic, final Set<MessageQueue> mqAll,final Set<MessageQueue> mqDivided);}- RocketMQ原理
- RocketMQ原理
- RocketMQ原理解析-namesrv
- rocketmq-producer原理解析
- rocketMQ原理与实战
- RocketMQ原理与实践
- RocketMQ原理解析-namesrv
- RocketMQ原理解析-namesrv
- rocketMQ nameSrv原理解析
- rocketMq--生产消费原理
- RocketMQ原理解析-namesrv
- RocketMQ的原理与实践
- RocketMQ的原理与实践
- RocketMQ基本概念及原理介绍
- RocketMQ原理——NameServer
- RocketMQ
- Rocketmq
- RocketMQ
- Framework基础介绍
- jqGrid简单使用
- 正负样本不均衡的解决办法
- FastDFS与Springboot集成
- Python实现逻辑回归(Logistic Regression in Python)
- RocketMQ原理
- Angular2语法快速指南
- CodeForces
- 路由器绑定MAC地址
- memset函数使用详解
- java.util.Date和java.sql.Date
- 我是一个线程(趣文)
- reflow与repain
- FastDFS分布式文件系统集群安装与配置


