okhttp 流程和优化的实现
来源:互联网 发布:淘宝怎样申请退款 编辑:程序博客网 时间:2024/06/06 03:04
一、概述
最近一直在忙着研究 okhttp,看了两周了,感觉东西实在是太多了,如果让我细致的写,我感觉能写 10 篇都写不完,那东西虽然是很多,但是主要的流程我们还是需要了解的,这篇文章我主要介绍以下 okhttp 中的流程,还有一些做的好的东西,之后再去将一些细节上的东西,这篇文章主要说了一个大概的内容,就是帮助你大致了解一下 okhttp 的实现,废话不多说了下面进入正题。
二、异步流程的实现
我们首先看一下网络上面很流行的一张图片,这张图片基本涵盖了一个整个的流程,下面我就对这张图片进行一一的说明:
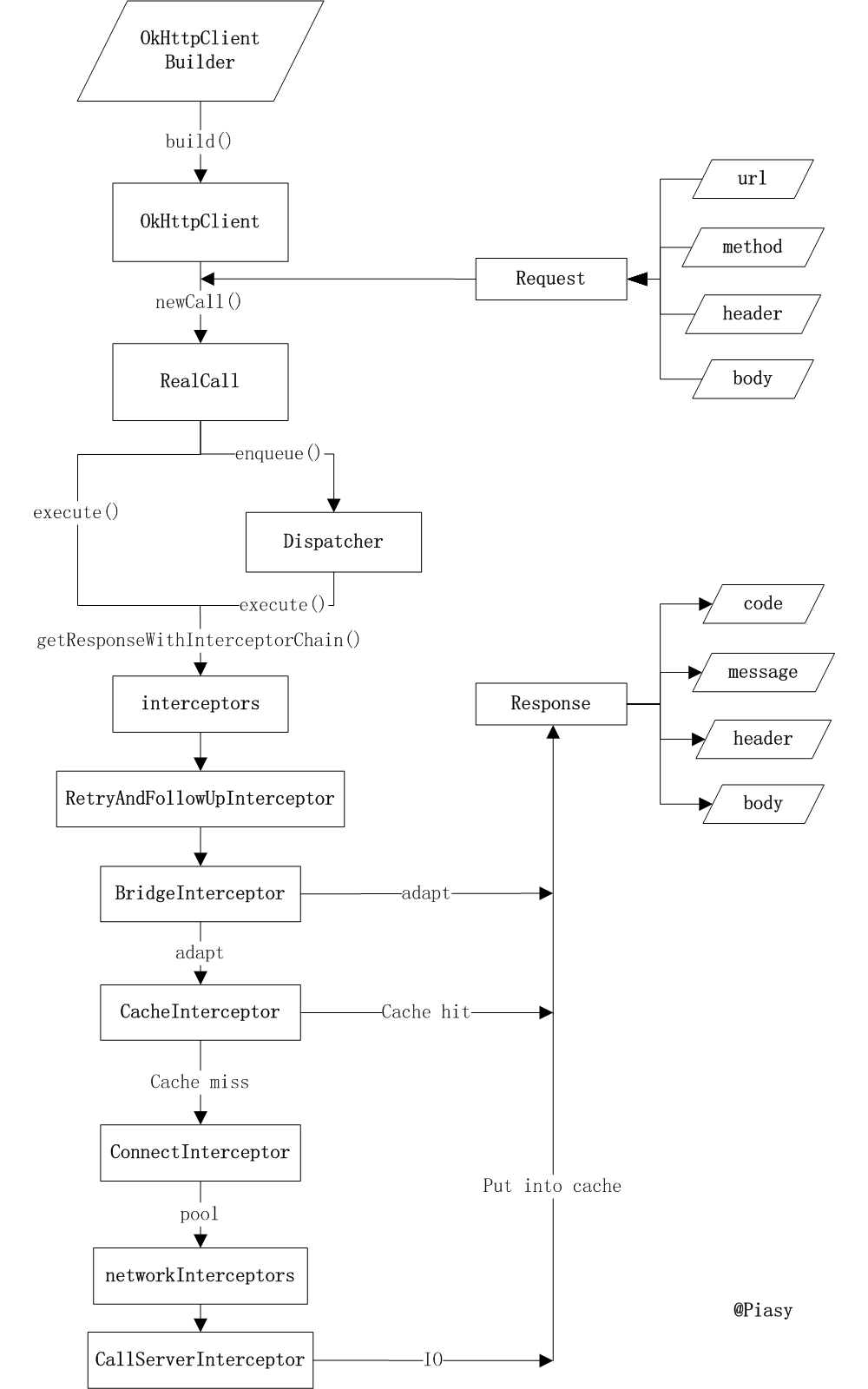
1、当我们请求的时候会新建一个 RealCall 的对象,创建之后会通过 dispatcher 去在线程池中分配线程,这个 dispatcher 的主要作用就是调度请求,这里面有三个队列,作用分别是存储异步正在运行的任务,存储异步正在准备运行的任务,还有同步运行的队列,通过这个类为我们的任务分配一个线程去运行
2、获取 Response 的过程,我们首先通过递归(index+1 的方式实现递归的)的方式一个一个的加入拦截器,拦截器首先加入的是我们的自定义的拦截器,然后去加框架自己的拦截器,那这几个拦截器的主要功能如下:
1、RetryAndFollowUpInterceptor(负责失败重试,重定向的)
概述:主要的作用就是请求时候创建一个 StreamAllocation 对象,这个对象创建的时候会根据请求的协议不同创建不一样的对象
2、BridgeInterceptor(负责把用户构造的请求转换为发送到服务器的请求、把服务器返回的响应转换为用户友好的响应的)
概述:主要就是把我们的 request 请求加上一些请求头,打包成真正的网络请求的 request,在请求返回的时候,通过 gzip 把我们能的 response 进行压缩
3、CacheInterceptor(负责读取缓存的,如果有缓存就拦截并返回,也负责更新缓存)
概述:负责读取我们的缓存,如果我们设置了 cache,那么先从这个里面读取,如果读取不到的那么就把 request 和 caseResponse 构建一个 CaheStategy 对象,然后判断这个对象是否有效,如果有效则直接返回,如果无效,那么我们请求,如果请求返回304,证明资源没过期,我们可以读取本地的缓存
4、 ConnectInterceptor(负责和服务器建立连接的)
概述:这个就比较复杂了,这个里面呢主要是进行 socket 的连接,在这个拦截器里首先获取了一个 streamAllocation 对象,然后通过这个对象获取了一个 RealConnection 对象,然后通过这个对象去获取一个 httpcode 对象,这个对象是一个接口,那具体实现有两种一个是 http1,一个是 http2,它会根据我们的请求创建不同的 httpCode ,通过这个对象可以进行下一个拦截器的操作,在我们获取 realconnection 的同时我们调用了 connect 这个方法,这个方法底层调用的就是 socket.connect 的方法,就是进行了 socket 的连接了
5、配置 OkHttpClient 时设置的 networkInterceptors
6、CallServerInterceptor(负责向服务器发送请求数据、从服务器读取响应数据的)
概述:通过4创建的 httpcode 进行写入数据,它是通过 okio 的 sink 进行写入数据的,这个 sink 和outputstream 差不多,就相当于写入流中数据,然后发送到服务器,这是请求部分。处理 Response 的时候,他会读取我们的返回的数据,通过 Source,然后把数据封装成 response 对象
注意:我们每个拦截器在 intercept 方法中都会调用 process 这个方法,这个方法的作用就是去执行下一个拦截器,那么如果我们自定义拦截器的话,需要调用 chain.proceed 方法,不然的话我们的请求就会在拦截器里面卡主。
那么异步请求的东西大致就这么多,还有很多细致的东西之后会分享出来。
三、okhttp 中有哪些优化,优化是怎么实现的
1、多路复用
概述:之前我们的请求是每一次请求会建立一个链接,请求结束就关闭链接,我们都知道 TCP/IP 请求是需要握手的,那握手就会消耗相应的时间,所以在我们的 okhttp 中,我们会复用之前的链接进行请求,这样请求速度就快了很多。
如果是这样的话就会出现两个问题,第一,我们怎么判断链接是否可用,第二是我们不需要的链接怎么回收。
从上面我们知道我们会在 StreamAllocation.newStream 方法中获取 RealConnection,在获取的时候我们会判断有没有之前的链接可以复用,复用的条件是这样判断的:
1、如果此链接的负载数目超过指定数目(表现为RealConnection的allocations集合的数量超过该链接指定的数量)或者noNewStreams为true时,此链接不可复用。
2、StreamAllocation 所持有的Address对象和RealConnection的Address非主机部分不同,则此链接不可复用。至于非主机部分的判定是在Address的equalsNonHost方法来体现。
两者Adress对象的非主机部分相等的标准就是dns,Authenticator对象、协议、CA授权验证标准、端口等信息全部相等。
3、在1、2判定条件都为true的话,如果两个Address对象的host或者说url中的host一样,则此链接可复用,正如注释说说,添加1、2、3都满足的话,那么此时这个链接就是This connection is a perfect match。
第一个问题我们解决了,现在我们来解决第二个问题,我们都知道链接如果多了我们如果不回收的话就会卡死,那么我们的链接是怎么回收的呢,链接回收主要降到的就是 ConnectionPool 这个类,这个类中有一个 clean up 方法,我们来看一下他里面做了什么:
clean up 方法:
标记清除法
1、首先标记出最不活跃的链接(空闲链接),之后进行清除
2、如果被标记的链接空闲 socket 超过 5 个,时间大于 5 分钟,那么直接清除。
3、如果此链接空闲,但是不足五分钟,则返回剩余时间,并进行标记,以供下次清除。
4、如果没用空闲链接的话,则五分钟之后再进行清理
判断是否为空闲链接:
1、遍历其中的 StreamAllocation,判断是否为空,如果为空,则没有引用这个 StreamAllocation
2、如果引用数量为 0 ,则为空闲链接
多路复用的原理就讲到这里了,其实很简单,只要吧 ConnectionPool 这个类看明白就很好理解了
2、缓存
概述:我们都知道,好的框架都会有缓存的功能,通过缓存我们可以很快的访问我们的资源,那 okhttp 也不例外,从上面的流程中我们可以看到, CacheInterceptor 主要是做缓存的,那么我们来了解一下他的流程是什么:
okhttp 的缓存策略是,key 为 Request的 url 的 MD5 值,value 为 response。
1、如果在 okhttpclient 初始化的时候配置了 cache,那么我们则从缓存中读取 caseResponse。
2、如果没有指定,那么我们将 request 和 caseResponse 构建一个 CacheStrategy 的类
3、判断 cachestrategy 是否有效,如果 request 和 caseResponse 都为空,直接返回 504
4、如果 request == null ,cacheResponse 不为空,则返回
5、如果为空,那么我们就进行网络请求,如果返回了 304 且我们本地有缓存,那么说明我们的缓存没有过期,可以继续使用
3、线程池的引入
概述:我们之前的请求都是每次都会新建线程去进行请求,这样的话我们如果有 100 个请求就会有 100 个线程,那么会消耗很大的资源,当引入线程池之后,我们就不需要频繁的去创建线程,而且可以复用线程,这样就很节省时间了。
4、可以进行压缩
在流程中我们讲到,当我们 response 通过 bridgeInterceptor 处理的时候会进行 gzip 压缩,这样可以大大减小我们的 response ,他不是什么情况下都压缩的,只有支持的时候才会 进行压缩。
其实还有一个是重连和重定向,现在还没弄懂,之后再去分享吧
四、okhttp 中用到了哪些设计模式
1、建造者模式,不管是构建一个 OkhttpClient 或者 Request 都是很复杂的,所以在 okhttp 框架中使用了建造者模式去创建这两个对象。
2、其实我认为 okhttp 最好的就是他的拦截器的设计,通过递归调用的方法去一个一个的拦截,最后在一个一个的处理,这样形成一条链路,让我们操作起来非常方便
总结:
好了,今天的东西就讲到这里吧,其实主要讲的都是一些流程上面的东西,而且讲的很粗略,没有那么细致,如果想深入了解的话还需要去看一下源码是怎么写的,这样会很深入的理解 okhttp 。
阅读全文
0 0
- okhttp 流程和优化的实现
- Okhttp的缓存优化
- okhttp实现 httpget 和 httppost 的java实现
- OkHttp面试之--OkHttp的整个异步请求流程
- OkHttp的同步和异步请求的实现
- 使用OkHttp实现下载的进度监听和断点续传
- okhttp 一 概述及同步和异步请求的实现
- 缺陷驱动的流程优化和技术引进
- iOS内购实现流程和丢单优化
- OkHttp的一些实现细节
- okhttp拦截器的实现
- okhttp拦截器的实现
- Okhttp的借口调用 和Banner实现学习下okhttp还是蛮必要的,本篇博客首先介绍okhttp的简单使用
- Volley和OkHttp的区别
- okhttp的间接 和 总结
- OkHttp的使用和封装
- OkHttp和HttpUrlConnection的示例
- OkHttp的Get和Post
- 如何写SysV服务管理脚本
- SpringBoot学习笔记 依赖管理
- 1095:大小写转换
- TCP自连接问题
- 求幂函数
- okhttp 流程和优化的实现
- 1042. 字符统计
- 【猪八戒】- 2017年在线笔试“叠字问题”
- Unity3D-截屏操作
- std::vector<string>转string
- leetcode 129. Sum Root to Leaf Numbers 一个简单的DFS做法
- c++中模板使用时候typename和class的区别
- Kth Largest Element in an Array
- Oracle与MySQL的几点区别


