那些有趣 Python 库
来源:互联网 发布:linux版本查看 编辑:程序博客网 时间:2024/04/27 08:03
转载出处 苏生不惑
图片处理
pip install pillowfrom PIL import Imageimport numpy as npa = np.array(Image.open('test.jpg'))b = [255,255,255] - aim = Image.fromarray(b.astype('uint8'))im.save('new.jpg')Parse Redis dump.rdb
pip install rdbtools> rdb --command json /var/redis/6379/dump.rdb[{"user003":{"fname":"Ron","sname":"Bumquist"},"lizards":["Bush anole","Jackson's chameleon","Komodo dragon","Ground agama","Bearded dragon"],"user001":{"fname":"Raoul","sname":"Duke"},"user002":{"fname":"Gonzo","sname":"Dr"},"user_list":["user003","user002","user001"]},{"baloon":{"helium":"birthdays","medical":"angioplasty","weather":"meteorology"},"armadillo":["chacoan naked-tailed","giant","Andean hairy","nine-banded","pink fairy"],"aroma":{"pungent":"vinegar","putrid":"rotten eggs","floral":"roses"}}]youtube-dl下载国外视频
pip install youtube-dl #直接安装youtube-dlpip install -U youtube-dl #安装youtube-dl并更新youtube-dl "http://www.youtube.com/watch?v=-wNyEUrxzFU"asciinema录制命令行操作
pip3 install asciinemaasciinema recasciinema play https://asciinema.org/a/132560<script type="text/javascript" src="https://asciinema.org/a/132560.js"id="asciicast-132560" async></script>查看对象的全部属性和方法
pip install pdir2>>> import pdir,requests>>> pdir(requests)module attribute: __cached__, __file__, __loader__, __name__, __package__, __path__, __spec__other: __author__, __build__, __builtins__, __copyright__, __license__, __title__,__version__, _internal_utils, adapters, api, auth, certs, codes, compat, cookies, exceptions, hooks, logging, models, packages, pyopenssl, sessions, status_codes, structures, utils, warningsspecial attribute: __doc__class: NullHandler: This handler does nothing. It's intended to be used to avoid the PreparedRequest: The fully mutable :class:`PreparedRequest <PreparedRequest>` object, Request: A user-created :class:`Request <Request>` object. Response: The :class:`Response <Response>` object, which contains a Session: A Requests session.exception: ConnectTimeout: The request timed out while trying to connect to the remoteserver. ConnectionError: A Connection error occurred. DependencyWarning: Warned when an attempt is made to import a module with missing optional FileModeWarning: A file was opened in text mode, but Requests determined its binary length. HTTPError: An HTTP error occurred. ReadTimeout: The server did not send any data in the allotted amount of time. RequestException: There was an ambiguous exception that occurred while handling your Timeout: The request timed out. TooManyRedirects: Too many redirects. URLRequired: A valid URL is required to make a request.function: delete: Sends a DELETE request. get: Sends a GET request. head: Sends a HEAD request. options: Sends a OPTIONS request. patch: Sends a PATCH request. post: Sends a POST request. put: Sends a PUT request. request: Constructs and sends a :class:`Request <Request>`. session: Returns a :class:`Session` for context-management.Python 玩转网易云音乐
#https://github.com/ziwenxie/netease-dl pip install netease-dlpip install ncmbotimport ncmbot#登录bot = ncmbot.login(phone='xxx', password='yyy')bot.content # bot.json()#获取用户歌单ncmbot.user_play_list(uid='36554272')下载视频字幕
pip install getsub
Python 财经数据接口包
pip install tushareimport tushare as ts#一次性获取最近一个日交易日所有股票的交易数据ts.get_today_all()代码,名称,涨跌幅,现价,开盘价,最高价,最低价,最日收盘价,成交量,换手率 code name changepercent trade open high low settlement \ 0 002738 中矿资源 10.023 19.32 19.32 19.32 19.32 17.56 1 300410 正业科技 10.022 25.03 25.03 25.03 25.03 22.75 2 002736 国信证券 10.013 16.37 16.37 16.37 16.37 14.88 3 300412 迦南科技 10.010 31.54 31.54 31.54 31.54 28.67 4 300411 金盾股份 10.007 29.68 29.68 29.68 29.68 26.98 5 603636 南威软件 10.006 38.15 38.15 38.15 38.15 34.68 6 002664 信质电机 10.004 30.68 29.00 30.68 28.30 27.89 7 300367 东方网力 10.004 86.76 78.00 86.76 77.87 78.87 8 601299 中国北车 10.000 11.44 11.44 11.44 11.29 10.40 9 601880 大连港 10.000 5.72 5.34 5.72 5.22 5.20 10 000856 冀东装备 10.000 8.91 8.18 8.91 8.18 8.10 开源漏洞靶场
# 安装pipcurl -s https://bootstrap.pypa.io/get-pip.py | python3# 安装dockerapt-get update && apt-get install docker.io# 启动docker服务service docker start# 安装composepip install docker-compose # 拉取项目git clone git@github.com:phith0n/vulhub.gitcd vulhub# 进入某一个漏洞/环境的目录cd nginx_php5_mysql# 自动化编译环境docker-compose build# 启动整个环境docker-compose up -d#测试完成后,删除整个环境docker-compose down北京实时公交
pip install -r requirements.txt 安装依赖python manage.py build_cache 获取离线数据,建立本地缓存#项目自带了一个终端中的查询工具作为例子,运行: python manage.py cli>>> from beijing_bus import BeijingBus>>> lines = BeijingBus.get_all_lines()>>> lines[<Line: 运通122(农业展览馆-华纺易城公交场站)>, <Line: 运通101(广顺南大街北口-蓝龙家园)>, ...]>>> lines = BeijingBus.search_lines('847')>>> lines[<Line: 847(马甸桥西-雷庄村)>, <Line: 847(雷庄村-马甸桥西)>]>>> line = lines[0]>>> print line.id, line.name541 847(马甸桥西-雷庄村)>>> line.stations[<Station 马甸桥西>, <Station 马甸桥东>, <Station 安华桥西>, ...]>>> station = line.stations[0]>>> print station.name, station.lat, station.lon马甸桥西 39.967721 116.372921>>> line.get_realtime_data(1) # 参数为站点的序号,从1开始[ { 'id': 公交车id, 'lat': 公交车的位置, 'lon': 公交车位置, 'next_station_name': 下一站的名字, 'next_station_num': 下一站的序号, 'next_station_distance': 离下一站的距离, 'next_station_arriving_time': 预计到达下一站的时间, 'station_distance': 离本站的距离, 'station_arriving_time': 预计到达本站的时间, }, ...]文章提取器
git clone https://github.com/grangier/python-goose.gitcd python-goosepip install -r requirements.txtpython setup.py install>>> from goose import Goose>>> from goose.text import StopWordsChinese>>> url = 'http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics.shtml'>>> g = Goose({'stopwords_class': StopWordsChinese})>>> article = g.extract(url=url)>>> print article.cleaned_text[:150]香港行政长官梁振英在各方压力下就其大宅的违章建筑(僭建)问题到立法会接受质询,并向香港民众道歉。梁振英在星期二(12月10日)的答问大会开始之际在其演说中道歉,但强调他在违章建筑问题上没有隐瞒的意图和动机。一些亲北京阵营议员欢迎梁振英道歉,且认为应能获得香港民众接受,但这些议员也质问梁振英有Python 艺术二维码生成器
pip install MyQRmyqr https://github.commyqr https://github.com -v 10 -l Q
伪装浏览器身份
pip install fake-useragentfrom fake_useragent import UserAgentua = UserAgent()ua.ie# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);ua.msie# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'ua['Internet Explorer']# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)ua.opera# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11ua.chrome# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'美化 curl
pip install httpstathttpstat httpbin.org/get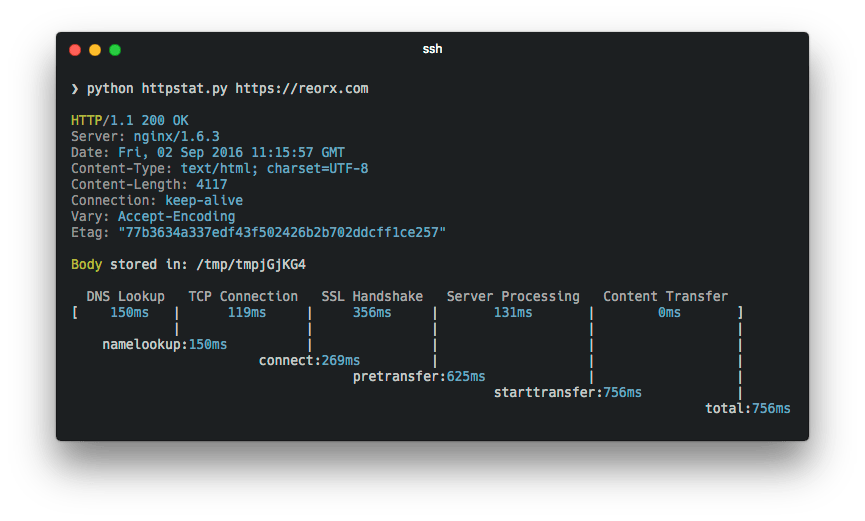
python shell
pip install shfrom sh import ifconfigprint ifconfig("eth0")处理中文文本内容
pip install -U textblob#英文文本的情感分析pip install snownlp#中文文本的情感分析from snownlp import SnowNLPtext = "I am happy today. I feel sad today."from textblob import TextBlobblob = TextBlob(text)TextBlob("I am happy today. I feel sad today.")blob.sentimentSentiment(polarity=0.15000000000000002, subjectivity=1.0)s = SnowNLP(u'这个东西真心很赞')s.words # [u'这个', u'东西', u'真心', # u'很', u'赞']s.tags # [(u'这个', u'r'), (u'东西', u'n'), # (u'真心', u'd'), (u'很', u'd'), # (u'赞', u'Vg')]s.sentiments # 0.9769663402895832 positive的概率s.pinyin # [u'zhe', u'ge', u'dong', u'xi', # u'zhen', u'xin', u'hen', u'zan']s = SnowNLP(u'「繁體字」「繁體中文」的叫法在臺灣亦很常見。')s.han # u'「繁体字」「繁体中文」的叫法 # 在台湾亦很常见。'抓取发放代理
pip install -U getproxy➜ ~ getproxy --helpUsage: getproxy [OPTIONS]Options:--in-proxy TEXT Input proxy file--out-proxy TEXT Output proxy file--help Show this message and exit.--in-proxy可选参数,待验证的 proxies 列表文件--out-proxy可选参数,输出已验证的 proxies 列表文件,如果为空,则直接输出到终端
--in-proxy 文件格式和 --out-proxy 文件格式一致
zhihu api
pip install git+git://github.com/lzjun567/zhihu-api --upgradefrom zhihu import Zhihuzhihu = Zhihu()zhihu.user(user_slug="xiaoxiaodouzi"){'avatar_url_template': 'https://pic1.zhimg.com/v2-ca13758626bd7367febde704c66249ec_{size}.jpg', 'badge': [], 'name': '我是小号', 'headline': '程序员', 'gender': -1, 'user_type': 'people', 'is_advertiser': False, 'avatar_url': 'https://pic1.zhimg.com/v2-ca13758626bd7367febde704c66249ec_is.jpg', 'url': 'http://www.zhihu.com/api/v4/people/1da75b85900e00adb072e91c56fd9149', 'type': 'people', 'url_token': 'xiaoxiaodouzi', 'id': '1da75b85900e00adb072e91c56fd9149', 'is_org': False}Python 密码泄露查询模块
pip install leakPasswdimport leakPasswdleakPasswd.findBreach('taobao')
解析 nginx 访问日志并格式化输出
pip install ngxtop$ ngxtoprunning for 411 seconds, 64332 records processed: 156.60 req/secSummary:| count | avg_bytes_sent | 2xx | 3xx | 4xx | 5xx ||---------+------------------+-------+-------+-------+-------|| 64332 | 2775.251 | 61262 | 2994 | 71 | 5 |Detailed:| request_path | count | avg_bytes_sent | 2xx | 3xx | 4xx | 5xx ||------------------------------------------+---------+------------------+-------+-------+-------+-------|| /abc/xyz/xxxx | 20946 | 434.693 | 20935 | 0 | 11 | 0 || /xxxxx.json | 5633 | 1483.723 | 5633 | 0 | 0 | 0 || /xxxxx/xxx/xxxxxxxxxxxxx | 3629 | 6835.499 | 3626 | 0 | 3 | 0 || /xxxxx/xxx/xxxxxxxx | 3627 | 15971.885 | 3623 | 0 | 4 | 0 || /xxxxx/xxx/xxxxxxx | 3624 | 7830.236 | 3621 | 0 | 3 | 0 || /static/js/minified/utils.min.js | 3031 | 1781.155 | 2104 | 927 | 0 | 0 || /static/js/minified/xxxxxxx.min.v1.js | 2889 | 2210.235 | 2068 | 821 | 0 | 0 || /static/tracking/js/xxxxxxxx.js | 2594 | 1325.681 | 1927 | 667 | 0 | 0 || /xxxxx/xxx.html | 2521 | 573.597 | 2520 | 0 | 1 | 0 || /xxxxx/xxxx.json | 1840 | 800.542 | 1839 | 0 | 1 | 0 |火车余票查询
pip install iquery Usage: iquery (-c|彩票) iquery (-m|电影) iquery -p <city> iquery -l song [singer] iquery -p <city> <hospital> iquery <city> <show> [<days>] iquery [-dgktz] <from> <to> <date> Arguments: from 出发站 to 到达站 date 查询日期 city 查询城市 show 演出的类型 days 查询近(几)天内的演出, 若省略, 默认15 city 城市名,加在-p后查询该城市所有莆田医院 hospital 医院名,加在city后检查该医院是否是莆田系 Options: -h, --help 显示该帮助菜单. -dgktz 动车,高铁,快速,特快,直达 -m 热映电影查询 -p 莆田系医院查询 -l 歌词查询 -c 彩票查询 Show: 演唱会 音乐会 音乐剧 歌舞剧 儿童剧 话剧 歌剧 比赛 舞蹈 戏曲 相声 杂技 马戏 魔术电脑之间传文件
pip install magic-wormholeSender:% wormhole send README.mdSending 7924 byte file named 'README.md'On the other computer, please run: wormhole receiveWormhole code is: 7-crossover-clockwork Sending (<-10.0.1.43:58988)..100%|=========================| 7.92K/7.92K [00:00<00:00, 6.02MB/s]File sent.. waiting for confirmationConfirmation received. Transfer complete.Receiver:% wormhole receiveEnter receive wormhole code: 7-crossover-clockworkReceiving file (7924 bytes) into: README.mdok? (y/n): yReceiving (->tcp:10.0.1.43:58986)..100%|===========================| 7.92K/7.92K [00:00<00:00, 120KB/s]Received file written to README.mdPython 数据可视化
pip install pyechartsfrom pyecharts import Barbar = Bar("我的第一个图表", "这里是副标题")bar.add("服装", ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"], [5, 20, 36, 10, 75, 90])bar.show_config()bar.render()#在根目录下生成一个 render.html 的文件,用浏览器打开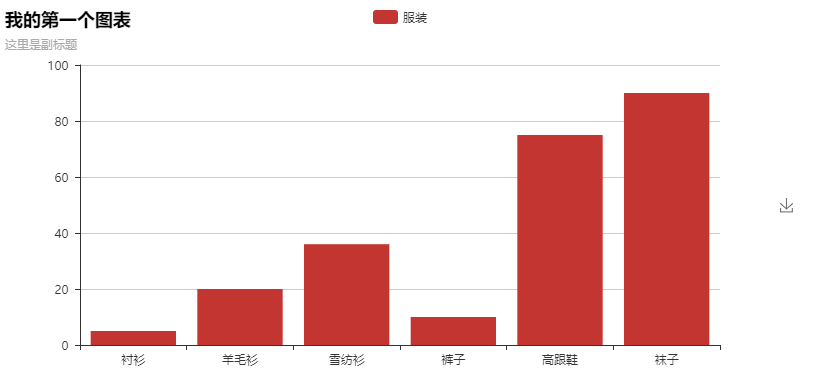
微信公众号爬虫接口
pip install wechatsogoufrom wechatsogou import *wechats = WechatSogouApi()name = '南京航空航天大学'wechat_infos = wechats.search_gzh_info(name)优雅的重试
pip install tenacity #限制重试次数为3次from tenacity import retry, stop_after_attempt@retry(stop=stop_after_attempt(3))def extract(url): info_json = requests.get(url).content.decode() info_dict = json.loads(info_json) data = info_dict['data'] save(data)查找IP地址归属地
pip install qqwry-py3 from qqwry import QQwry q = QQwry() q.load_file('qqwry.dat', loadindex=False) result = q.lookup('8.8.8.8') 导出 python 库列表
#pip freeze 导出当前环境中所有的 python 库列表$ pip install pipreqs$ pipreqs /home/project/locationSuccessfully saved requirements file in /home/project/location/requirements.txtGoogle Chrome Dev Protocol
pip install -U pychromegoogle-chrome --remote-debugging-port=9222# create a browser instancebrowser = pychrome.Browser(url="http://127.0.0.1:9222")# list all tabs (default has a blank tab)tabs = browser.list_tab()if not tabs: tab = browser.new_tab()else: tab = tabs[0]# register callback if you wantdef request_will_be_sent(**kwargs): print("loading: %s" % kwargs.get('request').get('url'))tab.Network.requestWillBeSent = request_will_be_sent# call methodtab.Network.enable()# call method with timeouttab.Page.navigate(url="https://github.com/fate0/pychrome", _timeout=5)# 6. wait for loadingtab.wait(5)# 7. stop tab (stop handle events and stop recv message from chrome)tab.stop()# 8. close tabbrowser.close_tab(tab)模糊搜索
pip install fuzzywuzzy>>> from fuzzywuzzy import fuzz>>> from fuzzywuzzy import process>>> fuzz.ratio("this is a test", "this is a test!") 97 >>> choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]>>> process.extract("new york jets", choices, limit=2) [('New York Jets', 100), ('New York Giants', 78)]>>> process.extractOne("cowboys", choices) ("Dallas Cowboys", 90)算法学习
from pygorithm.sorting import bubble_sortmyList = [12, 4, 3, 5, 13, 1, 17, 19, 15]sortedList = bubble_sort.sort(myList)print(sortedList)[1, 3, 4, 5, 12, 13, 15, 17, 19]命令行洪流搜索程序
pip install torrench --upgrade$ torrench "ubuntu desktop 16.04" ## Search Linuxtracker for Ubuntu Desktop 16.04 distro ISO$ torrench "fedora workstation" ## Search for Fedora Workstation distro ISO$ torrench -d "opensuse" ## Search distrowatch for opensuse ISO$ torrench -d "solus" ## Search distrowatch for solus ISO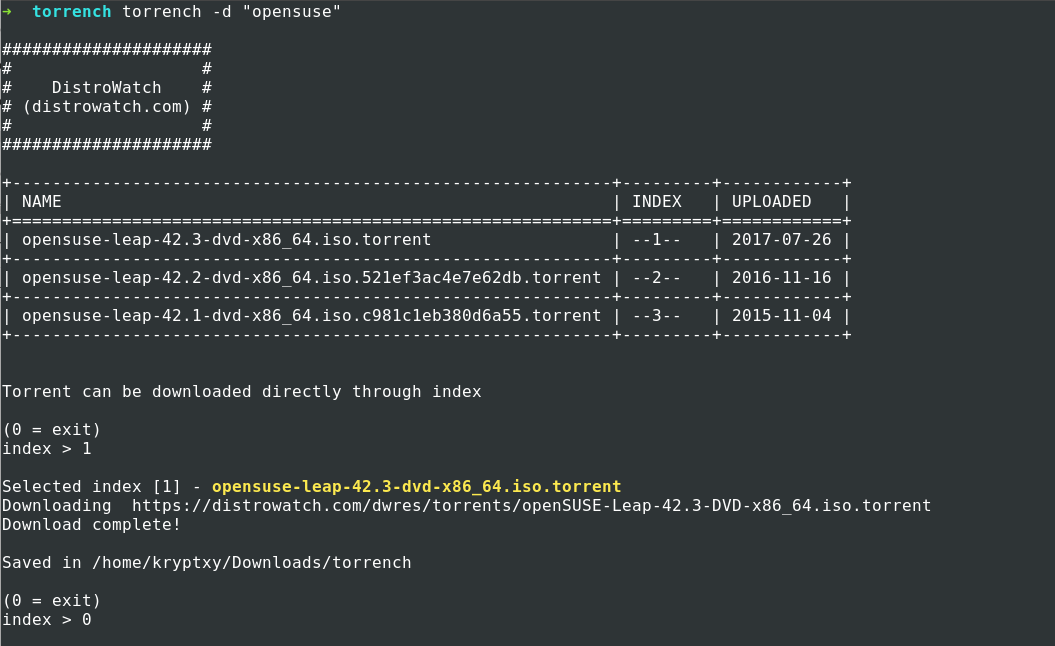
根据姓名来判断性别
pip install ngender$ ng 赵本山 宋丹丹name: 赵本山 => gender: male, probability: 0.9836229687547046name: 宋丹丹 => gender: female, probability: 0.9759486128949907>>> import ngender>>> ngender.guess('赵本山')('male', 0.9836229687547046)Python编写的简单的微信客户端
#https://github.com/pavlovai/matchpip install pywxclientpip install git+https://github.com/justdoit0823/pywxclient>>> from pywxclient.core import Session, SyncClient>>> s1 = Session()>>> c1 = SyncClient(s1)>>> c1.get_authorize_url() # Open the url in web browser>>> c1.authorize() # Continue authorize when returning False>>> c1.login()>>> c1.sync_check()>>> msgs = c1.sync_message() # Here are your wechat messages>>> c1.flush_sync_key()比较相似图片
$ pip install numpy$ pip install scipy$ pip install image_matchfrom image_match.goldberg import ImageSignaturegis = ImageSignature()a = gis.generate_signature('https://upload.wikimedia.org/wikipedia/commons/thumb/e/ec/Mona_Lisa,_by_Leonardo_da_Vinci,_from_C2RMF_retouched.jpg/687px-Mona_Lisa,_by_Leonardo_da_Vinci,_from_C2RMF_retouched.jpg')b = gis.generate_signature('https://pixabay.com/static/uploads/photo/2012/11/28/08/56/mona-lisa-67506_960_720.jpg')gis.normalized_distance(a, b)身份证识别OCR
生成各类虚拟数据
pip install mimesis>>> import mimesis>>> person = mimesis.Personal(locale='en')>>> person.full_name(gender='female')'Antonetta Garrison'>>> person.occupation()'Backend Developer'视频处理库
from moviepy.editor import *video = VideoFileClip("myHolidays.mp4").subclip(50,60)# Make the text. Many more options are available.txt_clip = ( TextClip("My Holidays 2013",fontsize=70,color='white') .set_position('center') .set_duration(10) )result = CompositeVideoClip([video, txt_clip]) # Overlay text on videoresult.write_videofile("myHolidays_edited.webm",fps=25) # Many options...微信聊天记录导出、分析工具
pip install wechat-explorer
wexp list_chatrooms ../Documents user_idwexp list_friends ../Documents user_idwexp get_chatroom_stats ../Documents user_id chatroom_id@chatroom 2015-08-01 2015-09-01wexp export_chatroom_records ../Documents user_id chatroom_id@chatroom 2015-10-01 2015-10-07 ../wexp get_friend_label_stats ../Documents user_idwkhtmltopdf --dpi 300 records.html records.pdf阅读全文
0 0
- 那些有趣 Python 库
- 那些有趣/用的 Python 库
- 那些有趣/用的 Python 库
- python里那些有趣有用又低调的特性
- [Python]一个有趣的库:pipe
- [Python]一个有趣的库:pipe
- 那些有趣的人和事
- stackoverflow那些有趣的badges
- python库的那些事
- Python中的有趣用法
- 有趣的Python
- 那些有趣的网站--个人头像趣处理
- 那些年写过的有趣注释
- Hive中那些有趣的字符串函数
- Python,Spam的有趣由来
- Python 有趣的join函数
- python的几个有趣点
- 有趣的python 对象描述
- 关于Fatal error: Can't use function return value in write context报错的解决方法!
- sql 日累计,不对等关联
- 手把手制作一个vcpkg的安装包及port file相关说明
- 感谢雷神让我了解视音频技术,一路走好!
- Android studio导入项目时的问题(Re-download dependencies and sync project (requires network))
- 那些有趣 Python 库
- HDU
- [RK3288][Android6.0] CPU频率调度策略小结
- 用单向循环链表解决约瑟夫问题
- java.io.File 进行文件操作常用方法
- php分享
- js replace(a,b)之替换字符串中所有指定字符的方法
- 数据库语句
- rocket mq的发展历史和底层实现原理


