Hibernate 一级缓存,二级缓存,查询缓存
来源:互联网 发布:linux安装windows软件 编辑:程序博客网 时间:2024/05/16 11:50
概念:
1.什么是缓存呢?
缓存:是计算机领域的概念,它介于应用程序和永久性数据存储源之间。
缓存:一般人的理解是在内存中的一块空间,可以将二级缓存配置到硬盘。用白话来说,就是一个存储数据的容器。我们关注的是,哪些数据需要被放入二级缓存。
作用:降低应用程序直接读写数据库的频率,从而提高程序的运行性能。缓存中的数据是数据存储源中数据的拷贝。缓存的物理介质通常是内存。
2.缓存在软件系统中的位置

3.hibernate的缓存一般分为几种?
分为三种:一级缓存,二级缓存和查询缓存
4.一级缓存
01.session内的缓存即一级缓存,内置且不能被卸载,一个事务内有效。在这个空间存放了相互关联的Java对象,这种位于session缓存内的对象也别称为持久化对象,session负责根据持久化对象的状态变化来同步更新数据库。
02.session为应用程序提供了管理缓存的方法:evict(Object o)和clear()
03.一级缓存结论
一级缓存的生命周期和session的生命周期一致,当前session一旦关闭,一级缓存就消失了,因此一级缓存也叫session级的缓存或事务级缓存,一级缓存只存实体对象,它不会缓存一般的对象属性(查询缓存可以),即当获得对象后,就将该对象缓存起来,如果在同一session中再去获取这个对象时,它会先判断在缓存中有没有该对象的id,如果有则直接从缓存中获取此对象,反之才去数据库中取,取的同时再将此对象作为一级缓存处理。
04.以下方法支持一级缓存
* get()
* load()
* iterate(查询实体对象)
其中 Query 和Criteria的list() 只会缓存,但不会使用缓存(除非结合查询缓存)。

5.二级缓存
01.二级缓存是进程(N个事务)或集群范围内的缓存,可以被所有的Session共享,在多个事务之间共享。
02.二级缓存是可配置的插件
03.二级缓存的散装数据
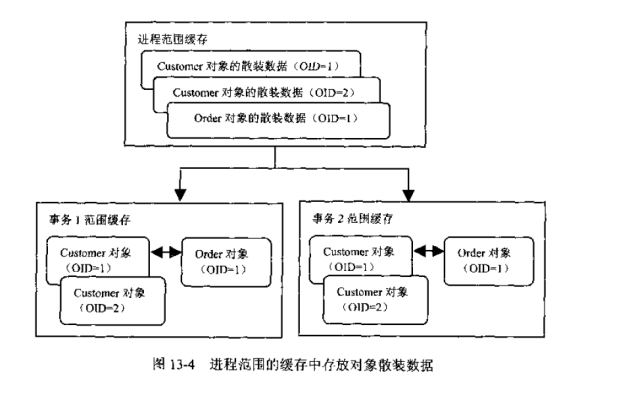
注意:如果缓存中的数据采用对象的散装数据形式,那么当不用的事务到缓存中查询OID为1的Customer对象时,获得的是Customer对象的散装数据,每个事务都必须分别根据散装数据重新构造出Customer实例,也就是说,每个事务都会获得不同的Customer对象。
04.二级缓存机制

05.二级缓存分为:类级别缓存,集合级别缓存,更新时间戳和查询缓存。
06.二级缓存的散装原理图

07.类级别的二级缓存只适用于get和load获取数据,对query接口的list()可以将数据放置到类级别的缓存中,但不能使用query接口的list()从缓存中获取数据。
08.注意点:修改一级缓存的数据,会自动同步到二级缓存。
09.二级缓存结论
二级缓存也称进程级的缓存或SessionFactory级的缓存,二级缓存可以被所有session共享,二级缓存的生命周期和SessionFactory的生命周期一致。hibernate为实现二级缓存,只提供二级缓存的接口供第三方实现。二级缓存也是缓存实体对象,原理和方法都与一级缓存差不多,只是生命周期有所差异。
6.查询缓存
01.查询是数据库技术中最常用的操作,Hibernate为查询提供了缓存,用来提高查询速度,优化查询性能相同HQL语句检索结果的缓存!
02.查询缓存依赖于二级缓存,查询缓存是针对普通属性结果集的缓存,对实体对象的结果集只缓存id(其id不是对象的真正id,可以看成是HQL或者SQL语句,它与查询的条件相关即where后的条件相关,不同的查询条件,其缓存的id也不一样)。查询缓存的生命周期,当前关联的表发生修改或是查询条件改变时,那么查询缓存生命周期结束,它不受一级缓存和二级缓存生命周期的影响,要想使用查询缓存需要手动配置。
7.结论
不要想当然的以为缓存可以提高性能,仅仅在你能够驾驭它并且条件合适的情况下才是这样的。hibernate的二级缓存限制还是比较多的。在不了解原理的情况下乱用,可能会有1+N的问题。不当的使用还可能导致读出脏数据。 如果受不了hibernate的诸多限制,那么还是自己在应用程序的层面上做缓存吧。
在越高的层面上做缓存,效果就会越好。就好像尽管磁盘有缓存,数据库还是要实现自己的缓存,尽管数据库有缓存,咱们的应用程序还是要做缓存。因为底层的缓存它并不知道高层要用这些数据干什么,只能做的比较通用,而高层可以有针对性的实现缓存,所以在更高的级别上做缓存,效果也要好些吧。
缓存是位于应用程序与物理数据源之间,用于临时存放复制数据的内存区域,目的是为了减少应用程序对物理数据源访问的次数,从而提高应用程序的运行性能. Hibernate在查询数据时,首先到缓存中去查找,如果找到就直接使用,找不到的时候就会从物理数据源中检索,所以,把频繁使用的数据加载到缓存区后,就可以大大减少应用程序对物理数据源的访问,使得程序的运行性能明显的提升.
Hibernate查询缓存全面分析
这里介绍Hibernate查询缓存对Iterator不起作用,只对List起作用。
缓存分类:
◆一级缓存 Session级
◆二级缓存 SessionFactory级别,JVM级别
◆Hibernate查询缓存不固定(生命周期不固定)
生命周期:
◆一级缓存 是和 session 会话一致产生一致消失
◆二级缓存 是和 sessionFacotry 一致
◆Hibernate查询缓存 生命周期不固定,当数据库表发生改变,使用Hibernate查询缓存马上消失
使用方法:
◆一级缓存:这个就不用说了
◆二级缓存:首先拷贝使用Hibernate查询缓存类别.xml到 classpath目录下面,然后到hibernate.cfg.xml里面配置。开启二级缓存(默认开启),定义要使用二级缓存的实体类,然后就是在程序中要显示的指定session。使用二级缓存的类别 有三种,Normal,GET,PUT默认使用的是 Normal即可以写也可以读取二级缓存(这里读写是指的会话Session)
◆Hibernate查询缓存:首先也是到hibernate配置文件中去开启Hibernate查询缓存,然后程序中也要显示的调用方法来开启Hibernate查询缓存eg:query.setCachemodel(true);
缓存的保存对象:
◆一级缓存:缓存实体
◆二级缓存:缓存的也是实体
◆Hibernate查询缓存缓存的是查询出来的实体的部分属性结果集和实体的ID(注意这里不是实体)
缓存的使用对象:
◆一级缓存:
Load(Lazy加载):首先查找把序列号去和一级缓存匹配是否有,有就直接取出来,如果没有,则发出SQL语句。
Get:也使用一级缓存。
List接口:query.list()不使用一级缓存,每次都要发出SQL eg:(select * from tudent)。
Iterator接口: query.iterate();使用一级缓存。首先是要发出一条SQL来取得ID,eg: select。id from student; 然后把ID拿到缓存中去匹配, 如果有,就直接取,如果没有,就要再发出SQL。如果都没有,将发出N+1条SQL,这就是N+1问题。
◆二级缓存: 都使用了二级缓存。
◆Hibernate查询缓存:对List 和Iterator接口起作用。但是Hibernate查询缓存对Iterator不起作用,只对List起作用。
下面我们这种介绍把二级缓存和Hibernate查询缓存结合使用。
当只是用Hibernate查询缓存而关闭二级缓存的时候:
第一:如果查询的是部分属性结果集: 那么当第二次查询的时候就不会发出SQL,直接从Hibernate查询缓存中取数据;
第二:如果查询的是实体结果集eg(from Student) ,首先Hibernate查询缓存存放实体的ID,第二次查询的时候就到Hibernate查询缓存中取出ID 一条一条的到数据库查询,这样,将发出N 条SQL造成了SQL泛滥。
当都开启Hibernate查询缓存和二级缓存的时候:
第一:如果查询的是部分属性结果集: 这个和上面只是用Hibernate查询缓存而关闭 二级缓存的时候一致,因为不涉及实体不会用到二级缓存;
第二:如果查询的是实体结果集eg(from Student),首先Hibernate查询缓存存放实体的ID,第二次查询的时候,就到Hibernate查询缓存中取出ID,到二级缓存区找数据,如果有数据,就不会发出SQL;如果都有,一条SQL都不会发出,直接从二级缓存中取数据。
总结: 查询缓存的key与HQL,查询参数以及分布参数有关,而且一旦查询涉及到的任何一张表的数据发生了变化,缓存就失效了,所以在生产环境中命中率较低。查询缓存保存的是结果集的id列表,而不是结果集本身 ,命中缓存的时候,会根据id一个一个地先从二级缓存查找 ,找不到再查询数据库。
list()没有使用缓存中的实体对象,因为查询需要查找到所有符合条件的记录,因此必须执行SELECT SQL,来保证查询数据的完整性;而iterate()通过执行SELECT SQL语句来获取满足查询条件的记录的ID,来保证查询数据的完整性
- hibernate的一级缓存、二级缓存、查询缓存
- hibernate 一级缓存、二级缓存、查询缓存
- 关于hibernate一级缓存二级缓存,查询缓存
- hibernate一级缓存,二级缓存和查询缓存
- hibernate 一级缓存二级缓存及查询缓存
- hibernate一级缓存,二级缓存和查询缓存
- hibernate一级缓存,二级缓存,查询缓存
- Hibernate 一级缓存,二级缓存,查询缓存
- Hibernate 一级缓存,二级缓存,查询缓存
- Hibernate 一级缓存、二级缓存、查询缓存比较
- Hibernate一级缓存 & 二级缓存
- Hibernate一级缓存,二级缓存
- Hibernate一级缓存 & 二级缓存
- Hibernate一级缓存,二级缓存
- hibernate一级缓存 二级缓存
- hibernate 一级缓存、二级缓存
- Hibernate 一级缓存 二级缓存
- hibernate 一级缓存、二级缓存
- 已知两个线性升序表LA,LB,然后合并两个表为LC,并保持升序
- 如果处理服务器与客户端时间不一致的问题
- node+express 后端api
- eclipse linux 下自动提示快捷键
- 分布式数据库, 高级形态 分布式事务数据库
- Hibernate 一级缓存,二级缓存,查询缓存
- Linux进程的共享文件
- 倒计时工具类:PYContDownManager
- android 内存监测工具 DDMS 和mat 工具使用
- include指令和动作的区别
- 3Sum Closest--LeetCode
- 【SSM】Eclipse使用Maven创建Web项目+整合SSM框架(这个666)
- 初识Runtime之KVO实现原理
- 产品级框架封装-单例模版


