深度学习(一) cross-entropy和sofrmax
来源:互联网 发布:linux print 编辑:程序博客网 时间:2024/06/16 00:43
Cross-entropy
神经网络的学习行为和人脑差的很多, 开始学习很慢, 后来逐渐增快
为什么?
学习慢 => 偏导数 ∂C/∂w 和 ∂C/∂b 值小
回顾之前学习的Cost函数:
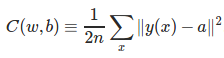
回顾sigmoid函数:
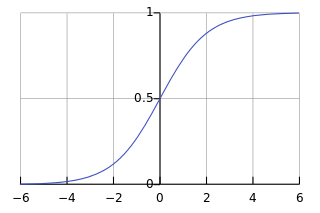
当神经元的输出接近1或0时,曲线很平缓,因而会使偏导数 ∂C/∂w 和 ∂C/∂b 值小,致使学习很慢
如何增快学习?
为此神经网络引入交叉熵代价函数cross-entropy函数
弥补 sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷
首先来看平方误差函数(squared-loss function),对于一个神经元(单输入单输出),定义其代价函数:
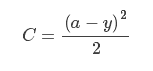
其中 a=σ(z),z=wx+b,然后根据对权值(w)和偏置(b)的偏导(为说明问题的需要,不妨将 x=1,y=0):
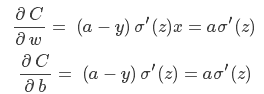
根据偏导计算权值和偏置的更新:
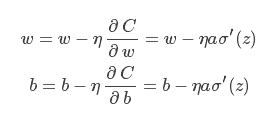
无论如何简化,sigmoid 型函数的导数形式 σ′(z) 始终阴魂不散
上文说了 σ′(z) 较容易达到饱和,这会严重降低参数更新的效率。
交叉熵代价函数
对于多输入单输出的神经元结构而言,如下图所示:

我们将其损失函数定义为:
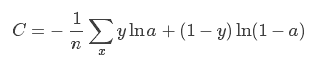
其中:
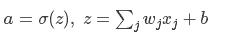
最终求导得:
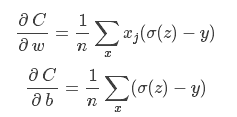
学习的快慢取决于
σ(z) - y
也就是输出的error
好处:错误大时,更新多,学的快
错误小时,学习慢
避免了 σ′(z) 参与参数更新、影响更新效率的问题;
总结:
cross-entropy cost几乎总是比二次cost函数好
如果神经元的方程是线性的, 用二次cost函数 (不会有学习慢的问题)
softmax和overfitting
1.下面介绍另外一种类型的输出层函数:
第一步:和sigmoid一样
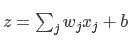
第二步:softmax函数
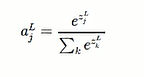
(分母是将每层所有的神经元的输出值加起来)
(分子是指第L层第J个神经元的输出)
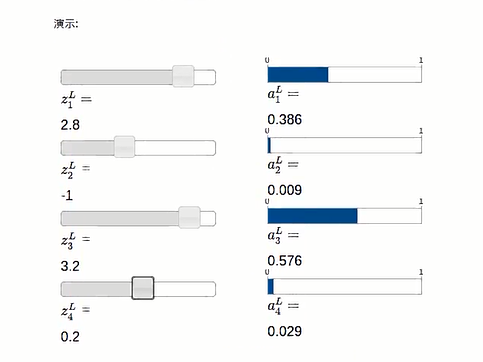
由上可得:
当最后一行z增大时,a也随之增大,其他a随之减小
事实上, 其他a减小的值总是刚好等于a4增加的值, 总和为1不变,Softmax的输出每个值都是大于等于0, 而且总和等于1
所以, 可以认为是概率分布,也可以认为输出的是每个可能分类标签的概率
如果输出层是sigmod层, 不能默认输出总和为1, 所以不能轻易描述为概率分布
2.介绍一种代价函数log-likelyhood函数
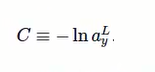
假设输入的是手写数字7的图片,输出比较确定接近7,对于对应的输出7的神经元,概率a接近1,对数C接近0,反之,对数C比较大,所有适合做Cost
是否存在学习慢的问题取决于:
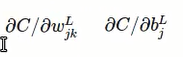
求偏导数,得到:
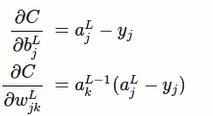
对比之前用的cross-entropy得到的偏导公式
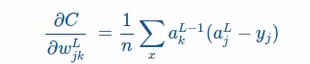
阅读全文
0 0
- 深度学习(一) cross-entropy和sofrmax
- TensorFlow学习笔记(二十三)四种Cross Entropy交叉熵算法实现和应用
- 交叉熵(Cross-Entropy)
- 交叉熵(Cross-Entropy)
- 交叉熵(Cross Entropy)
- 交叉熵(Cross-Entropy)
- 深度学习基础理论探索(二): cross-entropy损失函数的前世今生
- Cross entropy
- cross-entropy
- cross entropy
- 深度学习笔记:交叉熵(cross-entropy)损失函数解决二次型带来的学习速率下降问题
- 深度学习--手写数字识别<二>--交叉熵损失函数(cross entropy cost function)
- 理解交叉熵损失(Cross-Entropy)
- TensorFlow 中的交叉熵(Cross Entropy)
- 学习Caffe(五):浅析softmax cross entropy loss与sigmoid cross entropy loss
- TensorFlow 实战(一)—— 交叉熵(cross entropy)的定义
- 机器学习基础(六)—— 交叉熵代价函数(cross-entropy error)
- Cross Entropy Error Function
- 神经网络之卷积和池化
- Awesome-MaterialDesign最新控件效果git开源直接依赖
- lintcode递归总结
- instanceOf学习笔记
- C++笔试、面试、基础问题笔记
- 深度学习(一) cross-entropy和sofrmax
- 正则表达式 [后向引用]
- Android中的TCP/IP,HTTP的认识
- UE4--多线程的实现方式
- 《软件测试》学习笔记01
- 解决python无法用pip命令安装的问题
- Linux 命令
- 二分查找
- Redis使用认证密码登录


