高性能消息队列 CKafka 核心原理介绍(下)
来源:互联网 发布:程序员不好找女朋友 编辑:程序博客网 时间:2024/05/14 14:12
3 Kafka技术原理
Kafka设计目的就是为业界提供一套高性能、高可靠的消息中间件,故下面将会从高性能、高可靠几个方面对Kafka的技术原理进行剖析。
3.1 性能
3.1.1 Kafka高性能的关键点
Message格式简单而且采用二进制编码,尤为关键的地方是sdk和后端broker一致,且最终存储在文件中的格式也是一致。故生产消费时没有任何编解码操作,并且可以采用sendfile做到零拷贝进一步利用操作系统的高级特性提供性能。
批量处理,批处理是一种常用的用于提高I/O性能的方式。对于Kafka而言批处理既减少了网络传输的开销也提高了网络传输效率,同样采用批量方式提高了数据块的大小也会提高磁盘写入效率。
基于磁盘大文件的顺序读写。Kafka设计时就充分利用了磁盘的特性,采用大文件大块顺序读写方式,极大的提高了系统的吞吐量。
对Topic进行分区(partition),并尽量将不同的partition分配到不同的Broker,从而实现水平扩展,并且支持在线调整partition数量,理论上可以支持无线吞吐量,但受限于zookeeper的容量和性能,broker个数和partition都会有上限,但该上限非常大以至于可以认为没有上限。
端到端的数据压缩,并且支持批量压缩,极大的降低网络负载和磁盘负载。更妙的是Broker端接收到消息后,可以不直接解压直接将消息以压缩的形式直接持久化到磁盘(注:Broker这边其实还是会解压数据,然后对数据进行校验如果数据合法才会写入)。而且针对消费消息来说,这些已经被压缩的消息,也会直接发给消费者,由消费端自己负责解压缩,不仅降低了Broker的网络带宽,而且将解压的计算也分到消费者端,更近一步降低了Broker的资源消耗。
简单高效的传输协议及序列化方式,Kafka协议仅采用了单字节对齐,网络字节序的二进制格式进行通信,协议编解码效率极高,资源消耗少。
充分利用系统的Page Cache,而不采用应用内存缓存,如果采用应用内存不仅会耗费浪费更多的内存,而且会增加JVM的GC负担(注:Kafka采用Scala编写但Scala也是需要运行在JVM上,故这里有JVM及GC之说),Kafka的实现者充分做到了取长补短。而使用Page Cache又有如下好处:
a. I/O Scheduler会将连续的小块写组装成大块的物理写从而提高性能
b. I/O Scheduler会尝试将一些写操作进行重新排序,从而减少磁盘头的移动时间
c. 读操作可以直接在Page Cache中进行。如果生产消费速度相当,甚至不需要经过物理磁盘,直接通过Page Cache交换数据支持多Disk Drive,Kafka的log.dirs配置项允许配置多个目录。如果机器上还有多个Disk Drive,可以将不同的Disk挂载到不同的目录,然后将这些目录配置到log.dirs里,Kafka Broker会尽可能的将不同的Partition分配到不同的从而充分利用了多Disk优势。注:个人愚见,觉得这个功能其实不是十分有用,如果要追求高性能不如将多块磁盘做一下Raid,更方便调度,并且使得partition拥有更好的伸缩性能,当然有些场景无法做RAID,使用该方式也是能够利用到多块磁盘的能力。
3.1.2 Message格式详解
注:Kafka为支持不同的业务形态当前共存在3个版本格式的Message
a. v0版本包括0.9及其之前的版本采用
b. v1 0.10版本新定义的Message格式,较v0增加了一个8byte的time字段
c. v2 0.11版本新定义的Message格式之前的编码格式有较大的改动,而且该版本于2017年6月底才发布故不再本文讨论范围
1、message v0格式详解
采用一字节对齐,且使用网络字节序(大端)
bit 0 ~ 2 : Compression codec.
0 : no compression
1 : gzip
2 : snappy
3 : lz4
bit 3 ~ 7 : reservedkey length(K)4byte用于表明key的大小(不包含本身所占用的空间),需要注意的是Kafka对该字段的表明的意义不一样:
-1表示不存在key
0表示存在key但key的大小为0
>0 表示key的长度keyK byte存储key的内容,其大小由key length字段表示。用户可以自己指定,Kafka Broker进行日志compact也会有用到该字段value length(V)4byte用于表明value的大小(不包含本身所占用的空间)valueV byte存储value的内容,其大小由value length字段表示
为了方便查看用C的伪代码可以如下表示v0消息的格式


2、essage v1 格式详解
bit 0 ~ 2 : Compression codec.
0 : no compression
1 : gzip
2 : snappy
3 : lz4
bit 3:时间戳类型
0: 消息产生的时间,由用户端指定
1: 消息添加到Broker log的时间,由Broker指定
bit 4 ~ 7 : reservedtimestamp8byte消息生产的时间或者消息被broker添加到log的时间,具体看attributes的值。单位mskey length(K)4byte用于表明key的大小(不包含本身所占用的空间),需要注意的是Kafka对该字段的表明的意义不一样:
-1表示不存在key
0表示存在key但key的大小为0
>0 表示key的长度keyK byte存储key的内容,其大小由key length字段表示。用户可以自己指定,Kafka Broker进行日志compact也会有用到该字段value length(V)4byte用于表明value的大小(不包含本身所占用的空间)valueV byte存储value的内容,其大小由value length字段表示
可以看出比v0版本的消息仅多了一个timestamp字段用于表明消息的生产(或添加到broker日志的时间),方便用户通过指定时间去获取消息。为了方便查看用C的伪代码可以如下表示v1消息的格式

3、批量消息及压缩详解
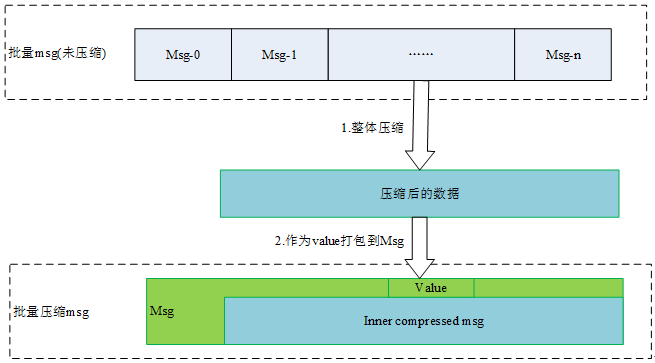
通过上图,可以看出Kafka通过消息嵌套(Kafka要求消息仅能嵌套一层)的方式,实现了消息的批量压缩,既保证了格式的一致,也实现了批量消息压缩用以提高整体压缩率。而不是采用单个消息压缩。较友好的实现了批量压缩。
4、Message格式小结
a. Message整个头部非常紧凑,v0格式的仅仅26字节 v1格式的也只有34字节。既节省了带宽也节省了存储。
b. 格式定义良好,扩展方便,编码解码简单。对于客户端和后端的存储采用同一套编码方式,这样就导致了不用来回编解码和格式转换,节省了Broker及客户端的资源,让整个消息流转及存储更加的高效。
c. 包含了校验码,用于进行数据完整性校验,提高了数据的可靠性
d. 可以非常简单的不改变原有格式的情况下,通过嵌套方式实现消息批量压缩,更近一步提高资源利用率。而且Broker仅仅只用解压对消息进行一些必要的校验,而不用再次压缩,效率高。最重要的是由于整个消息格式在客户端和broker都是一致的,消费时broker不用做任何解压缩和压缩操作,直接将消息传递个消费者,效率奇高。
3.1.3 Kafka存储方式详解
1、Kafka文件存储机制Kafka文件存储中,同一topic有不同的partition,每个partition为一个目录,partition的命名规则为topic名称 + 有序序号(从零开始)。具体可以参考下图。

- 注:timeindex文件是0.10.1.0版本及之后版本才加入的一个新的索引文件,主要是为了通过时间方式去查找相应的消息,实现类似于.index。如果要通过time查找消息在segment的位置,其实timeindex中存的是relative offset,还需要在经过.index文件去定位消息具体在segment中的偏移。
2、partition在Kafka中以目录形式存在,每个partition物理上由多个segment(文件分片)和与其一一对应的index文件组成。每个segment大小类似(默认配置为1G)。segment的命名方式是使用其第一条消息的offset格式化生成,这样通过名称可以很容易查看到segment消息的开始,同时通过相邻的segment也很容易计算出segment中包含的消息个数。将partition分成segment,则非常方便快速删除过期的分片。
3、index文件
采用稀疏存储用于节省空间,主要用于读取消息时快速定位所需要的消息位置。
4、生产消息
消息以append方式添加到最新的segment尾部,算法复杂度为O(1)不会受到现有数据总量的影响,当写入的数据大小或消息条数达到配置的阈值则主动强制刷盘,用于保证系统崩溃时,消息的丢失量在可以接受的范围。同时当写入一定的数据后生成一条索引信息添加到index文件末尾。当segment大小超过配置则滚动生成一个新的segment。可以看到消息都是顺序追加写,且大块刷,可以很好的利用系统的调度和磁盘顺序写的能力达到较高的吞吐量。
5、消费消息
当消费者拉取消息时会指定offset,这时候先从segment list定位到所需的segment的index文件。由于index文件采用稀疏索引方式,文件较小(Kafka默认配置为10M),故采用mmap形式直接加载到内存,然后采用二分法查找到与所需的消息offset相同或相邻的位置,最后再去segment文件中读取到真正的数据。可以看到消费消息时,整个过程最耗时的地方就在从index文件中查找(时间复杂度O(logn)),然index文件比较小,个数也很少,基本可以全部缓存在page cache加之消费者基本都是顺序消费会进一步提高整个cache命中率,故也能提供非常高的消费性能。
6、删除消息
Kafka的Topic根据应用场景不同提供两种删除方式compact和delete。
a. compact方式
使用compact方式的删除会保证同一个key只保留最新的一条消息(其实这样看来这种方式更加类似于一个kv系统)。0.8.2版本之后(含)Kafka可以使用_consumer_offsets这个特殊的内置topic进行存储consumer group中每个partition的消费状态,而这个topic就采用的是compact方式进行日志删除。该方式要求msg的key不能为空,且比较消耗broker系统资源,一般用户的topic,非常不建议使用该方式进行日志删除。b. delete方式
Kafka topic采用的默认清除日志的方式,按照所设的最大保留时间,或所设定的最大保留大小以segment为最小单位进行删除。从最老的segment开始进行删除。由于是整个文件分片的删除,效率非常高。
3.1.4 partition分配策略
Kafka单机性能很强,但总会有上限,Kafka之所以能够无限平行扩展,在性能上碾压其他消息中间件,都是基于其partition概念。由于broker都是以partition为最小服务单位,对外提供服务,当增加partition就有可能分配到更多的broker为其服务,进而提高性能,当然这一切前提都是需要有个好的均衡算法让一个Topic的partition用分配到更多的broker为其服务。故partition能否均匀的分配到Kafka broker集群,直接影响到扩展性和性能。
具体算法
Kafka分配策略的目标有两个:
a.使partition的副本能够均匀的分配至各个Kafka Broker,用于做到负载均衡和应用更多broker的能力
b.使同一个partition的不同副本,分配到不同的broker,进一步提高可用性。当然这个条件也是Kafka限制副本数不能大于broker的原因,因为同一个partition的不同副本分配到相同的broker毫无意义。
算法步骤:
- a.将所有活着的broker,按照broker id进行排序
- b.随机一个起始位置,选取一个最开始分配的broker这里命名为StartBroker,主要用于防止如果partition个数少且副本为1,如果不随机采用从头开始很容易导致partition的分配聚集在id小的broker上导致分配不均匀
- c.随机一个小于broker个数的随机数作为ReplicaShift,该值大小需保证为[1, broker count – 1]
- d.将partition的第一副本分配给StartBroker
- e.根据ReplicaShit计算第n(n>=2)个副本与第一个的偏移量,将其分配至相应Broker
- f.将StartBroker移至下一个Broker
- g.如果Broker以被轮询完一次,则增加ReplicaShift(主要为了可以更加均匀的分配副本)。然后分配下一个partition,从步骤4)继续开始。
算法代码(从Kafka工具截取采用Scala编写不太好看可以对照上面的步骤进行阅读):

注:partition分配算法虽然很重要,但并不是在broker端实现,而是在Kafka Admin工具包中实现。由相关工具分配好,然后写入zookeeper的一个管理节点,最后触发controller watcher事件,controller根据相应的事件,直接从zookeeper拉取到已经分配好的结果,仅仅只用选出leader然后通知相关broker而已。
3.2 可靠性
Kafka的可靠性及可用性,都源自其0.8版本加入的replication概念以及ISR选举算法和消息commit机制(Kafka commit机制通过HW和ISR来保证)共同保证。只有commit后的消息才能被consumer消费,不让消费者消费到未确认的消息从而提高数据的一致性。最后再配合消息生产确认方式及刷盘策略,进而达到用户需要的可靠性及可用性。
3.2.1 生产确认
当Producer向leader发送数据时,可以通过设置acks参数通过确认方式来配合后端提高可靠性级别。其主要配置项如下:
3.2.2 复制原理和同步方式
1、消息在segment文件中的状态
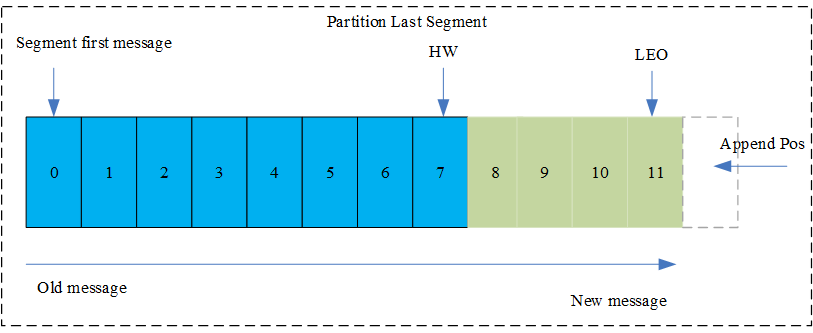
HW:High Water缩写,指的是consumer能够消费到此partition的最大位置,取partition对应的ISR的最小值为HW,另外每个replica都有HW, leader和follower各自负责维护自己的HW状态。
LEO:Log End Offset的缩写,表示每个partition最后一条message的位置。
2、消息复制及HW和LEO流转过程
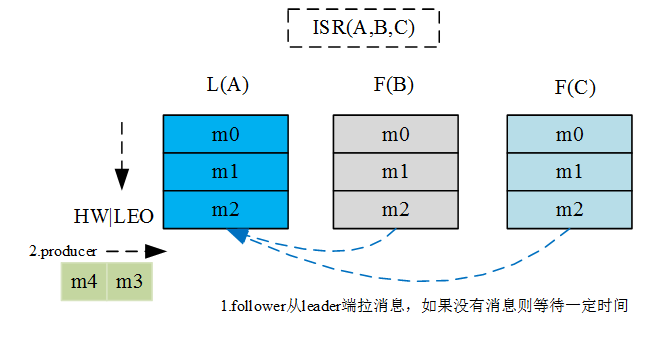

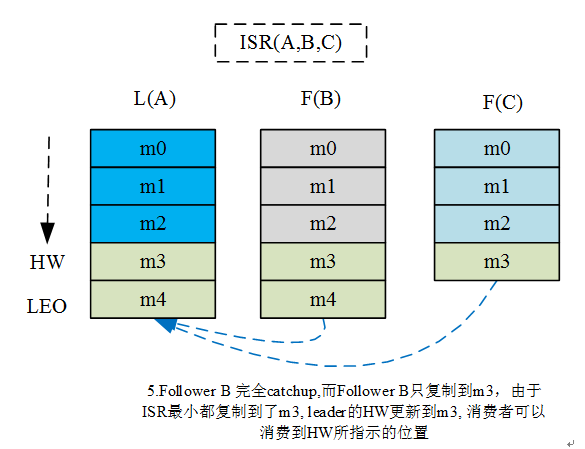
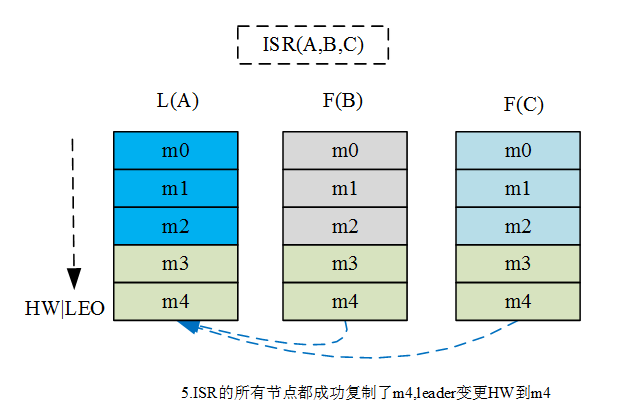
通过该流转过程可见, Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka使用ISR的方式,很好的均衡了数据可靠性及吞吐率。
3.2.3 Leader选举
leader选举的常用算法非常多,比如Zookeeper的Zab、Raft以及Viewstamped Replication等,这些算法其实都是采用少数服从多数的方式。在这种模式下,如果有2f+1个副本,那么在commit之前必须保证有f + 1个replica复制完消息,同时为了保证能正确的选举出新的leader,失败的副本个数不能超过f。这种方式有个很大的优势就是系统的延迟取决于最快的大多数机器,而且数据一致性及可靠性高。当然这种方式也有些劣势就是所能容忍的失败的follower个数较少,故在生产环境下为了保证较高的容错率,必须要有大量的副本,而大量的副本又会在大数据量下导致性能急剧下降。而Kafka所使用的leader选举算法更像是微软的PacificA算法。
Kafka在Zookeeper中为每一个partition动态的维护了一个ISR,这个ISR里的所有replica都跟上了leader,ISR里的成员会优先选为leader(unclean.leader.election.enable=false)。在这种模式下,对于f+1个副本,一个Kafka topic能在保证不丢失已经commit消息的前提下容忍f个副本的失败,在大多数使用场景下,这种模式是十分有利的。事实上,为了容忍f个副本的失败,“少数服从多数”的方式和ISR在commit前需要等待的副本数量是一样的,但是ISR需要的总的副本的个数几乎是“少数服从多数”的方式的一半。在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某一个partition的所有replica都挂了,就无法保证数据不丢失了。这种情况下有两种可行的方案(Kafka默认选择第二种):
a.等待ISR中任意一个replica“活”过来,并且选它作为leader
b.选择第一个“活”过来的replica(并不一定是在ISR中)作为leader
第一种方案会提高可用性,第二种方案则是提高数据可靠性。两种方案,用户可以根据业务形态进行相关的定制化。
3.2.4 消息传递语义
常用的消息传输语义:
- At most once 消息可能会丢失,但绝不会重复传输
- At least once 消息绝不丢失,但可能会重复传输
- Exactly once 每条消息绝不丢失而且仅被传输一次,很多时候这个是用户所需要的。
可以看出,从上到下实现的难度一次递增,当前Kafka其实可以支持到At least once,但这个也基本上要配置成全同步才能做到(比如必须配置所有ISR都同步,并且每条消息都同步刷盘,且生产者配置acks=-1),通过这种方式可以达到同步多写,进而做到数据不丢失,但配置成这种方式又会导致Kafka性能急剧下降,完全违背了Kafka标榜的高吞吐。 注:Kafka 0.11版本添加了Exactly once消息传输支持,但该版本2017年6月底才发布,这里暂不做分析。
3.3 优劣势
3.3.1 优势
- 扩展性高,可以做到平行扩展。并且Kafka集群扩展时,可以做到对用户透明。
- 高性能,Kafka的性能远超过传统的ActiveMQ, RabbitMQ等消息队列。
- 高可用性,通过副本方式和ISR的选举算法,使得Kafka有相当高的可用性。
- 社区活跃度高,当前很多大数据组件如spark, flume, elasticsearch等等都集成了对Kafka的支持。
3.3.2 劣势
- 依赖组件众多,导致部署的设备多,运维量大,难以维护。如果简单的用让Kafka以黑盒的方式进行运行,当然只需要部署Kafka broker和zookeeper即可。但如果想对Kafka运行的状态有所了解则需要部署上相关的监控软件、鉴权中心等等。虽然相关的软都有开源的实现,但学习成本高搭建部署也麻烦。
- 安全防护功能有限,鉴权依赖于第三方搭建组件。最初整个Kafka都没有权限相关的控制也没有用户的概念,最后为了支持,硬生生的在正常的请求前加上了SASL相关的鉴权,但这又导致用户需要搭建相应的鉴权中心,工作量大且复杂。不利于产品化。
- 隔离性差,无法做到分布式资源管理及速度控制。
- 兼容性差,消息格式不断更改,处理逻辑不断更改,导致兼容性非常差,很多版本竟然不能保证向前兼容。
- 配置多,仅仅broker端都有一百多项配置,虽然系统默认的配置能达到不错的效果,但如果想贴合业务进行配置,则这么多的配置会让人望而生畏。
4 Ckafka介绍
鉴于Kafka存在以上(2.3.2)几个无法调和的劣势,我们选择开发Ckafka。
4.1 总体架构
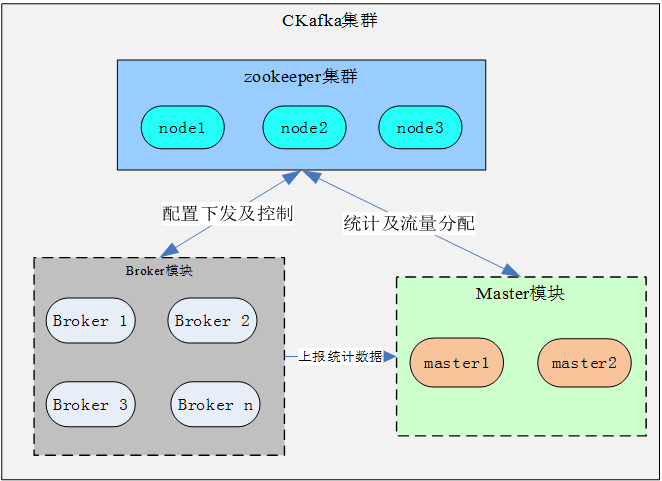
- Ckafka借鉴了Kafka的实现,采用zookeeper进行存储metadata和leader选举
- Ckafka对集群进行了垂直化划分,通过限制每个集群的大小,从而不仅可以减少风险而且可以更大规模的部署更多的集群,做到无限的水平扩展能力。
- Ckafka通过与master合作,实现分布式动态流量分配。更好的隔离和平衡用户在不同broker节点上的流量和容量分配。
4.2 鉴权
Ckafka是以实例(实例包含吞吐量、容量两个维度)的形式对外提供服务,不同用户、实例间通过网络策略进行隔离,实例内部支持按照IP白名单鉴权,满足个性化需求。
- 实例: 不同租户通过不同实例(vip:vport)访问服务,开通网络策略保证租户所在vpc网络只能访问到自己实例(vip:vport)。
- Broker:通过多端口提供服务,不同端口服务不同的实例,达到资源隔离。Broker根据端口鉴权实例是否有生产/消费某个topic的权限。Broker还提供更细力度的鉴权,同一实例不同topic的鉴权,通过客户端ip白名单方式鉴权。
- Topic:同一个broker上存在的不同实例可能topic名称一样,为解决这个问题,Ckafka采用名字映射生成唯一的topic,当然用户对于这个是透明无感知的。
4.3 资源隔离
由于同一个实例会分配多台broker为其服务,以便达到更高的可用性。这种情况下,就需要有一个分布式流量控制程序,对实例的流量进行相关的控制,防止实例使用超过允诺的流量。当前的分布式流量控制由master完成,broker会定期上报当前流量数据到master,master进行汇总后,采用下面的算法进行流量分配。算法具体步骤如下:
1.如果实例的消息存储容量已经达到最大,则堵住生产放行消费
2.根据实例所分配的broker上包含的partition数,计算出每个broker应该分配的流量,这里记为F
3.将实例当前在每个broker产生的流量与F进行比较,如果所有broker当前的量都小于80%,则按照初始量F进行分配。
4.计算出每个broker的流量,计算出每个broker所占的流量比率记为P
5.找出最大最小流量,并计算最大最小流量,分别记为Pmax, Pmin
a.如果Pmin / Pmax >= 80%则根据步骤4中计算出的比率P进行分配
b.如果Pmin / Pmax < 80% 则流量最大的按照P进行分配, 其他的按照min(P + Pmax * 10%, Pmax)进行分配,(加上10%的量是为了给流量小的节点一些余量好进行流量增长,用以达到再平衡)
4.4 优化
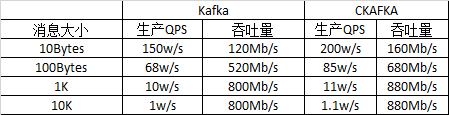
提到Kafka,大家第一反应应该都是高性能。Kafka的确做到了非常高的性能,被业内很多大数据选作中间存储或管道,便是对其高性能的认可。但追求性能的Ckafka同样也对其做了一些优化,而且也取得了一定的效果。
测试场景:1个topic 3个partition 单机测试生产性能
机型B6: Intel(R) Xeon(R) CPU 2.13GHz 16核 、64G内存、1G网卡
5 总结
消息中间通常分为高可靠和高性能两种版本。Ckafka是一款高性能消息中间,主要用于满足对性能要求极高的应用场景(如网站活动追踪、运营监控、日志聚合、流式处理、事件追踪等等),并且兼容现有的Kafka协议使用户零成本迁入。当然用户如果有高可靠的要求,我们自研的CMQ则是一款金融级高可靠分布式消息中间件,其通过Raft保证了消息的可靠不丢失,同时性能和可用性相比竞品也有显著的提高。
- 高性能消息队列 CKafka 核心原理介绍(下)
- 高性能消息队列 CKafka 核心原理介绍(上)
- 高性能消息队列 CKafka 核心原理介绍(上)
- Java常用消息队列原理介绍及性能对比
- 高性能消息队列研究
- 高性能队列Disruptpor核心源码解析
- 【Server】高性能的消息队列 (三)
- 高性能的消息队列 (三)
- 消息队列技术的介绍和原理(MQ)
- 消息队列技术的介绍和原理(MQ)
- 消息队列技术的介绍和原理(MQ)
- 消息队列技术的介绍和原理(MQ)
- 消息队列技术的介绍和原理(MQ)
- 消息队列的介绍和原理
- 消息队列--Apache kafka 工作原理介绍
- 消息队列系列(一):.Net平台下的消息队列介绍
- golang:高性能消息队列moonmq的简单使用
- 高性能开源持久化消息队列
- 高性能消息队列 CKafka 核心原理介绍(上)
- 初识git和svn
- Java String格式日期加1秒(分钟或小时)
- html5/Css3 眩晕转圈
- Java面试题集(136-150)
- 高性能消息队列 CKafka 核心原理介绍(下)
- 30了,程序员中的老司机们,30后的路该开向哪里
- 热修复原理
- 全面屏适配
- C++ 重载限制
- js 数组操作(高级)
- Android开发笔记(一百五十)自动识别验证码图片
- 欢迎使用CSDN-markdown编辑器
- iOS禁用手势滑动


