WebCollector 网页爬虫
来源:互联网 发布:西安行知中学初中部 编辑:程序博客网 时间:2024/06/06 05:57
爬虫简介:
WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
爬虫内核:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
<dependencies> <dependency> <groupId>cn.edu.hfut.dmic.webcollector</groupId> <artifactId>WebCollector</artifactId> <version>2.70</version> </dependency></dependencies>
内核构架图:
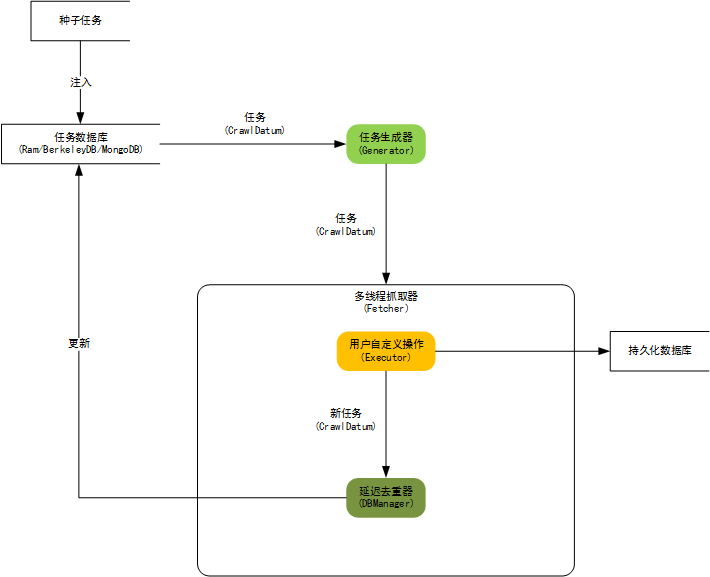
WebCollector 2.x 版本特性:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每个 URL 设置附加信息(MetaData),利用附加信息可以完成很多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可定制自己的Http请求、过滤器、执行器等插件。
内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理长期和大量级的任务,并具有断点爬取功能,不会因为宕机、关闭导致数据丢失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并内置多代理随机切换功能。 可通过定义 http 请求实现模拟登录。
使用 slf4j 作为日志门面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每个爬虫定制配置信息。
WebCollector 2.x 官网和镜像:
官网:https://github.com/CrawlScript/WebCollector
镜像:http://git.oschina.net/webcollector/WebCollector
WebCollector 2.x教程:
WebCollector配置
WebCollector配置教程
WebCollector入门
WebCollector简单入门教程
WebCollector特色功能
【推荐】WebCollector教程——MetaData
【推荐】WebCollector教程——MatchUrl和MatchType
WebCollector 教程——去重辅助插件 NextFilter
WebCollector教程——断点爬取
WebCollector教程——网页正文自动提取
WebCollector持久化
WebCollector教程——使用Spring JDBC持久化数据
WebCollector高级爬虫定制
WebCollector教程——定制简单的Http请求
WebCollector教程——代理设置
WebCollector教程——深度定制Http请求(HttpClient)
WebCollector处理Javascript
WebCollector教程——爬取Javascript加载的数据
WebCollector示例
WebCollector教程——爬取CSDN博客
WebCollector教程——爬取搜索引擎
WebCollector教程——爬取新浪微博
WebCollector教程——爬取微信公众号
WebCollector教程——图片爬取
WebCollector教程——获取当前抓取深度
网页正文提取:
网页正文提取项目 ContentExtractor 已并入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方法。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取效果指标 :
比赛数据集 CleanEval P=93.79% R=86.02% F=86.72%
常见新闻网站数据集 P=97.87% R=94.26% F=95.33%
算法无视语种,适用于各种语种的网页
标题抽取和日期抽取使用简单启发式算法,并没有像正文抽取算法一样在标准数据集上测试,算法仍在更新中。
- WebCollector 网页爬虫
- Webcollector爬虫
- WebCollector爬虫使用内置的Jsoup进行网页抽取
- WebCollector爬虫的种子
- Java爬虫-WebCollector
- JAVA爬虫 WebCollector
- JAVA爬虫WebCollector
- JAVA爬虫 WebCollector
- webcollector爬虫demo
- Webcollector 判定爬虫结束
- webcollector 爬虫框架使用说明
- WebCollector网页正文提取
- JAVA爬虫WebCollector教程列表
- WebCollector爬虫的redis插件
- WebCollector java爬虫使用笔记
- WebCollector java爬虫使用笔记
- Java WebCollector爬虫采集数据
- webcollector爬虫框架使用案例
- 二叉树的递归与非递归遍历(前序、中序、后序)
- CSDN下载积分的获取方式
- nyoj 144 小珂的烦恼
- install samba on ubuntu
- 基于Mina实现的一个简单数据采集中间件
- WebCollector 网页爬虫
- 数据结构实验2.1(单链表)
- LinkedList源码详解
- What a Beautiful Lake
- 线程同步机制
- 六大设计原则详解(5)-迪米特法则
- SpringMvc+POI处理excel表数据导入
- python
- webstorm 使用技巧


