RDMA技术
来源:互联网 发布:最有名的网络武侠小说 编辑:程序博客网 时间:2024/06/05 03:44
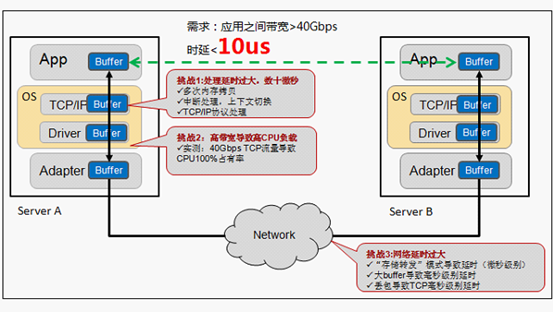
面对高性能计算、大数据分析和浪涌型IO高并发、低时延应用,现有TCP/IP软硬件架构和应用高CPU消耗的技术特征根本不能满足应用的需求。这要有体现在处理延时过大,数十微秒;多次内存拷贝、中断处理,上下文切换、复杂的TCP/IP协议处理、网络延时过大、存储转发模式和丢包导致额外延时。接下来我们继续讨论RDMA技术、原理和优势,看完文章你就会找到为什么RDMA可以更好的解决这一系列问题。
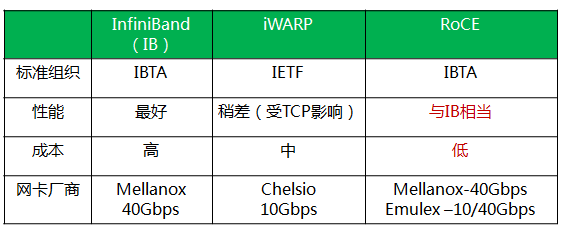
RDMA是一种远端内存直接访问技术,详细介绍请参看文章。RDMA最早专属于Infiniband架构,随着在网络融合大趋势下出现的RoCE和iWARP,这使高速、超低延时、极低CPU使用率的RDMA得以部署在目前使用最广泛的以太网上。
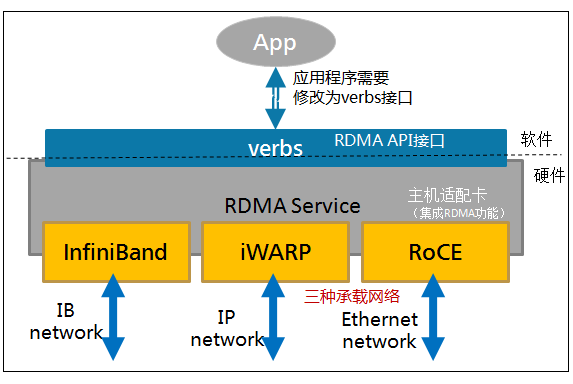
RDMAC(RDMA Consortium)和IBTA(InfiniBand Trade Association)主导了RDMA发展,RDMAC是IETF的一个补充并主要定义的是iWRAP和iSER,IBTA是infiniband的全部标准制定者,并补充了RoCE v1 v2的标准化。IBTA解释了RDMA传输过程中应具备的特性行为,而传输相关的Verbs接口和数据结构原型是由另一个组织OFA(Open Fabric Alliance)来完成。
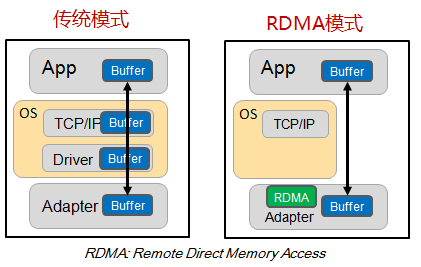
相比传统DMA的内部总线IO,RDMA通过网络在两个端点的应用软件之间实现Buffer的直接传递;相比比传统的网络传输,RDMA又无需操作系统和协议栈的介入。RDMA可以轻易实现端点间的超低延时、超高吞吐量传输,而且基本不需要CPU、OS等资源介入,也不必再为网络数据的处理和搬移耗费过多其他资源。
InfiniBand通过以下技术保证网络转发的低时延(亚微秒级),采用Cut-Through转发模式,减少转发时延;基于Credit的流控机制,保证无丢包;硬件卸载;Buffer尽可能小,减少报文被缓冲的时延 。
iWARP(RDMA over TCP/IP) 利用成熟的IP网络;继承RDMA的优点;TCP/IP硬件实现成本高,但如果采用传统IP网络丢包对性能影响大。
RoCE性能与IB网络相当;DCB特性保证无丢包;需要以太网支持DCB特性;以太交换机时延比IB交换机时延要稍高一些。
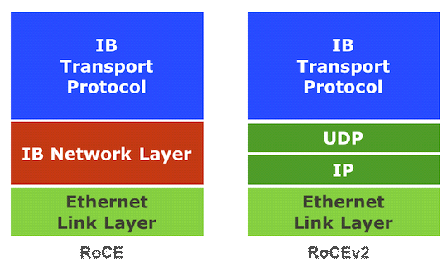
RoCEv2针对RoCE进行了一些改进,如引入IP解决扩展性问题,可以跨二层组网;引入UDP解决ECMP负载分担等问题。
基于InfiniBand的RDMA是在2000年发布规范,属于原生RDMA;基于TCP/IP的RDMA称作iWARP,在 2007年形成标准,主要包括MPA/DDP/RDMAP三层子协议;基于Ethernet的RDMA叫做RoCE,在2010年发布协议,基于增强型以太网并将传输层换成IB传输层实现。
扩展RDMA API接口以兼容现有协议/应用,OFED(Open Fabrics Enterprise Distribution)协议栈由OpenFabric联盟发布,分为Linux和windows版本,可以无缝兼容已有应用。通过使已有应用与RDMA结合后,性能成倍提升。
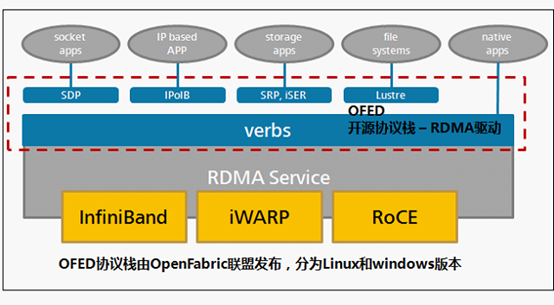
应用和RNIC(RDMA-aware network interface controller)之间的传输接口层(Software Transport Interface)被称为Verbs。OFA(Open Fabric Alliance)提供了RDMA传输的一系列Verbs API。OFA开发了OFED(Open Fabric Enterprise Distribution)协议栈,支持多种RDMA传输层协议。
OFED向下除了提供RNIC(实现 RDMA 和LLP( Lower Layer Protocol))基本的队列消息服务外,向上还提供了ULP(Upper Layer Protocols),通过ULP上层应用不需直接和Verbs API对接,而是借助于ULP与应用对接,这样使得常见的应用不需要做修改就可以跑在RDMA传输层上。
在Infiniband/RDMA的模型中,核心是如何实现应用之间最简单、高效和直接的通信。RDMA提供了基于消息队列的点对点通信,每个应用都可以直接获取自己的消息,无需操作系统和协议栈的介入。
消息服务建立在通信双方本端和远端应用之间创建的Channel-IO连接之上。当应用需要通信时,就会创建一条Channel连接,每条Channel的首尾端点是两对Queue Pairs(QP),每对QP由Send Queue(SQ)和Receive Queue(RQ)构成,这些队列中管理着各种类型的消息。QP会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡。除了QP描述的两种基本队列之外,RDMA还提供一种队列Complete Queue(CQ),CQ用来知会用户WQ上的消息已经被处理完。
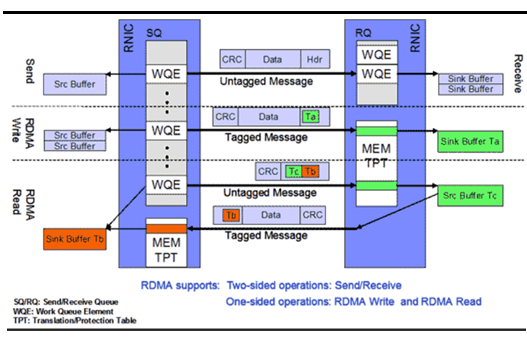
RDMA提供了一套软件传输接口,方便用户创建传输请求Work Request(WR),WR中描述了应用希望传输到Channel对端的消息内容,WR通知QP中的某个队列Work Queue(WQ)。在WQ中,用户的WR被转化为Work Queue Ellement(WQE)的格式,等待RNIC的异步调度解析,并从WQE指向的Buffer中拿到真正的消息发送到Channel对端。
RDMA中SEND/RECEIVE是双边操作,即必须要远端的应用感知参与才能完成收发。READ和WRITE是单边操作,只需要本端明确信息的源和目的地址,远端应用不必感知此次通信,数据的读或写都通过RDMA在RNIC与应用Buffer之间完成,再由远端RNIC封装成消息返回到本端。在实际中,SEND/RECEIVE多用于连接控制类报文,而数据报文多是通过READ/WRITE来完成的。
对于双边操作为例,主机A向主机B(下面简称A、B)发送数据的流程如下:
1. 首先,A和B都要创建并初始化好各自的QP,CQ
2. A和B分别向自己的WQ中注册WQE,对于A,WQ=SQ,WQE描述指向一个等到被发送的数据;对于B,WQ=RQ,WQE描述指向一块用于存储数据的Buffer。
3. A的RNIC异步调度轮到A的WQE,解析到这是一个SEND消息,从Buffer中直接向B发出数据。数据流到达B的RNIC后,B的WQE被消耗,并把数据直接存储到WQE指向的存储位置。
4. AB通信完成后,A的CQ中会产生一个完成消息CQE表示发送完成。与此同时,B的CQ中也会产生一个完成消息表示接收完成。每个WQ中WQE的处理完成都会产生一个CQE。
双边操作与传统网络的底层Buffer Pool类似,收发双方的参与过程并无差别,区别在零拷贝、Kernel Bypass,实际上对于RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。
对于单边操作,以存储网络环境下的存储为例(A作为文件系统,B作为存储介质),数据的流程如下:
1. 首先A、B建立连接,QP已经创建并且初始化。
2. 数据被存档在A的buffer地址VA,注意VA应该提前注册到A的RNIC,并拿到返回的local key,相当于RDMA操作这块buffer的权限。
3. A把数据地址VA,key封装到专用的报文传送到B,这相当于A把数据buffer的操作权交给了B。同时A在它的WQ中注册进一个WR,以用于接收数据传输的B返回的状态。
4. B在收到A的送过来的数据VA和R_key后,RNIC会把它们连同存储地址VB到封装RDMA READ,这个过程A、B两端不需要任何软件参与,就可以将A的数据存储到B的VB虚拟地址。
5. B在存储完成后,会向A返回整个数据传输的状态信息。
单边操作传输方式是RDMA与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用的参与其中,这种方式适用于批量数据传输。
1.Infiniband的成功取决于两个因素,一是主机侧采用RDMA技术,可以把主机内数据处理的时延从几十微秒降低到几微秒,同时不占用CPU;二是InfiniBand网络的采用高带宽(40G/56G)、低时延(几百纳秒)和无丢包特性
2.随着以太网的发展,也具备高带宽和无丢包能力,在时延方面也能接近InfiniBand交换机的性能,所以RDMA over Ethernet(RoCE)成为必然,且RoCE组网成本更低。未来RoCE、iWARP和Infiniband等基于RDMA技术产品都会得到长足的发展。
- RDMA技术
- RDMA技术
- RDMA技术
- RDMA技术分析
- RDMA编程技术
- RoCE与RDMA技术
- RDMA技术分析
- RDMA
- RDMA
- RDMA(远程直接内存访问)技术浅析
- 用GPUDirect RDMA技术做的代码测试
- SparkRDMA:使用RDMA技术提升Spark的Shuffle性能
- RDMA 简介
- TOE,RDMA
- rdma编程
- RDMA & RoCE
- 什么是RDMA?
- RDMA PROTOCAL
- Fred 7.0.0 光线追迹软件_USB加密锁,全模块运行稳定版\
- VMware WorkStation的三种网络连接方式
- (三)双向链表的初始化、插入和删除
- 你的Scrum迭代够精益吗?看完就全明白了
- 在 React、Vue项目中使用 SVG
- RDMA技术
- my_bash
- UVA 10706 Number Sequence
- hihoCoder
- Android API 过期方法整理
- sublime text3常用插件
- 滑动窗口的中位数-LintCode
- 《UNIX网络编程 卷2》 笔记: Posix信号量
- LintCode 主元素


