海量数据的解决方案
来源:互联网 发布:js json转换对象 编辑:程序博客网 时间:2024/05/18 00:19
随着企业业务的不断扩展,不得不面临数据量大的问题,下面针对这个问题进行各种方案的介绍。
1 缓存和页面静态化
缓存的使用方式分为通过程序保存到内存中和使用缓存框架两种方式。程序直接操作的是 Map,尤其是ConcurrentMap,而常用的缓存框架有 Ehcache、Memcache 和 Redis等。
页面静态化是将程序最后生成的页面保存起来,使用页面静态化后就不需要每次调用都重新生成页面了,这样不但不需要查询数据库,而且连应用查询处理都省了,所以页面静态化同时对数据量大和并发量高两大问题都有好处。但是页面静态化之后,如果页面中包含动态的数据,可以在页面加载完毕后通过ajax异步拉取最新的数据。常用的框架 Freeemarker 和 Velocity 都可以根据模板生成静态页面。
2 数据库优化
好的数据库结构对于应用的访问速度起到了很大的重要。常用的优化有如下几种:
- 表结构优化;
- SQL语句优化;
- 分区:分区相对于分表,其实就是把一张表中的数据按照一定的规则存放在不同的区。
- 分表;
- 索引优化:
- 使用存储过程代替直接操作。
3 分离活跃数据
对于一张表来说,只有很少一部分的数据是用户经常访问和使用的,绝大多数的数据用率都很低,我们可以把活跃数据存放到一张表里面。这样就可以起到加速访问的作用。
4 批量读取和延迟修改
批量读取和延迟修改的原理就是尽量减少对数据库的io操作。比如我们在增加某些不需要那么高实时性的数据的时候,如录入员工的数据,我们在增加某条员工数据时,需要查询数据库中是否有这条数据,我们就可以先向临时表中插入数据,然后批量录入这些数据。
5 读写分离
读写分离的本质是对数据库进行集群,多数情况下我们将一台服务器作为主服务器,当然也可以根据不同的业务划分主服务器,读取时使用其下游服务器,这样我们在写入到主服务器后,主服务器将数据同步到其下游服务器,然后我们再读取下游服务器的数据,在高并发的情况下就将数据库的操作分配到多个数据库去处理从而降低单台服务器的压力。
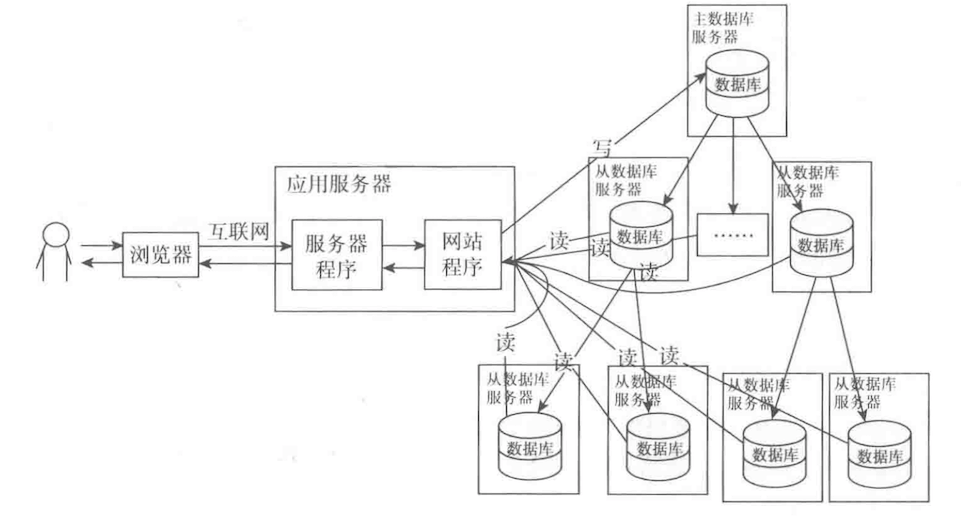
6 分布式数据库
分布式数据库是将不同的表存放到不同的数据库中然后再放到不同的服务器。这样在处理请求时,可以让多个服务器同时处理,从而提高处理速度。使用分布式后的每个节点还可以同时使用读写分离,从而组成多个节点群。

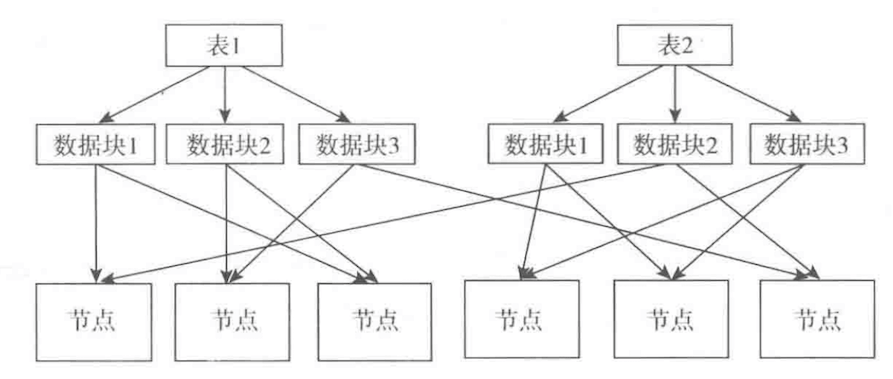
7 Hadoop
Hadoop 是专门针对大数据处理的一套框架,Hadoop是将同一个表中的数据分成多块保存到多个节点(分布式),而且每一块数据都有多个节点保存(集群),这里集群除了可以并行处理相同的数据,还可以保证数据的稳定性,在其中一个节点出现问题后数据不会丢失。
Appendix
Revision History
Copyright
CSDN:http://blog.csdn.net/y550918116j
GitHub:https://github.com/937447974
- 海量数据的解决方案
- 海量数据的解决方案
- 海量数据的解决方案
- 海量数据对比去除重复的解决方案
- 海量数据的存储和访问解决方案
- 关于海量数据问题的解决方案
- 关于海量数据问题的解决方案
- 海量数据解决方案
- 海量大数据解决方案
- 海量数据解决方案
- 基于hadoop的海量数据挖掘的开源解决方案
- 海量数据列表翻页解决方案
- 海量数据解决方案,知多少?
- 海量数据解决方案 知识总结
- 浅谈海量数据的微软商务智能解决方案
- mysql 海量数据的存储和访问解决方案
- mysql 海量数据的存储和访问解决方案
- mysql海量数据的存储和读取解决方案
- 创建软连接ln -s
- __attribute__()的研究
- CSS(四)— 伪类
- 锤子剪刀布 (20)
- MySQL 复制--slave 执行start slave时,连接master
- 海量数据的解决方案
- mybatis foreach语法
- MyEclipse写web项目,连接数据库出现main方法错误
- 【C++】 union详解
- 企业应用通用架构图
- c++小项目(学生信息管理系统)
- 新手看JAVA异常处理机制
- 如何在 Kaggle 首战中进入前 10%
- error: expected ';', ',' or ')' before '&' token 解决方法


