朴素贝叶斯分类算法
来源:互联网 发布:淘宝买家退货流程 编辑:程序博客网 时间:2024/05/22 11:44
朴素贝叶斯简介
朴素贝叶斯是贝叶斯分类中最简单的一类,要求必须事先已知样本总体能够分为几类。它首先根据训练样本的分类分布情况,得出先验概率。然后利用贝叶斯公式,得到后验概率,从而对对整个的待分类集合进行分类,其分类依据是将待分类集合中的元素分类到最可能的那种类别。
贝叶斯公式
基于贝叶斯公式的分类算法很多,朴素贝叶斯的应用极为广泛。但是,它也有其缺陷,因为它要求待分类集合的属性独立,因此这种方法在有些特征属性之间关系比较复杂的情况下,往往不能表现出良好的性能。在这里给出贝叶斯的数学公式和解读:
向来数学公式是装逼利器(当然上面这个比较简单除外),下面对这个公式做解读。
如果我们把上述的A当作已知分类集合Y,把B当作待分类集合X。那么可以看出利用已知分类集合Y(用机器学习的术语来表述就是训练样本集合Y)可以求得先验概率,然后通过待分类样本求得似然度和标准化常量,最后得到分类的后验概率,取其最大值,设定为待分类样本所属的类。其实贝叶斯公式在这里主要是给我们提供了一个分类器供我们使用。
朴素贝叶斯分类的原理
其实上面说了那么多,估计还是云里雾里的,举个例子就明白了,因为我们每个人在平常的生活中都会发挥分类的作用。比如说,你来到了一所高中,突然你的面前出现了一个身长2米的同学,你肯定会对其进行判断,如果把判断的方面限制到,判断这个同学是什么运动队的。你的第一反应就是这个人肯定是篮球队的。在这里先验条件就是,高个子的学生打篮球的几率可能比较大,这里的待分类样本其实是这名同学的身高。这个例子菜的抠脚,原谅博主神一般的脑回路,实在想不起更有趣的例子。当然,这名同学有可能不是,如果人家喜欢绣花,你也不能拦着人家。其实说了这么多,就是告诉我们,贝叶斯估计能够结合先验概率和样本的似然程度对样本进行分类,这就大大提高了分类的准确程度,并且在数据量很大的时候,朴素贝叶斯展现了它的强大。
下面给出朴素贝叶斯分类的正式定义:
1. 设存在待分类项
2. 同时已知分类集合
3. 分别计算
4.
我们来寻找整个分类过程中的已知量和未知量。
1. 待分类项也就是待分类的样本集合中的样本。
2. 已知分类集合,可以通过训练样本结合进行训练和提取。
3. 根据贝叶斯公式:
要求左边,只需要求出右边,在右边的分式中,分母是常数,因为当测试样本确定之后
所以就求所有特征属性在分类确定的情况下的似然度的连乘和分类本身在训练样本中所占概率做乘积。其中的最大值就是我们所求的结果,最大值所对应的分类就是待分类项的类别。在这里,我所实验的样本是离散的,所以只需要求得每个分类和每个分类的属性在训练样本中的频数就可以确定先验概率,然后求出测试样本中在分类确定的情况下,各个特征属性出现的频数就可以确定似然度,当然出现的频数越大似然度也就越大,从而就可以进行分类。
下面给出整个朴素贝叶斯分类的流程图: 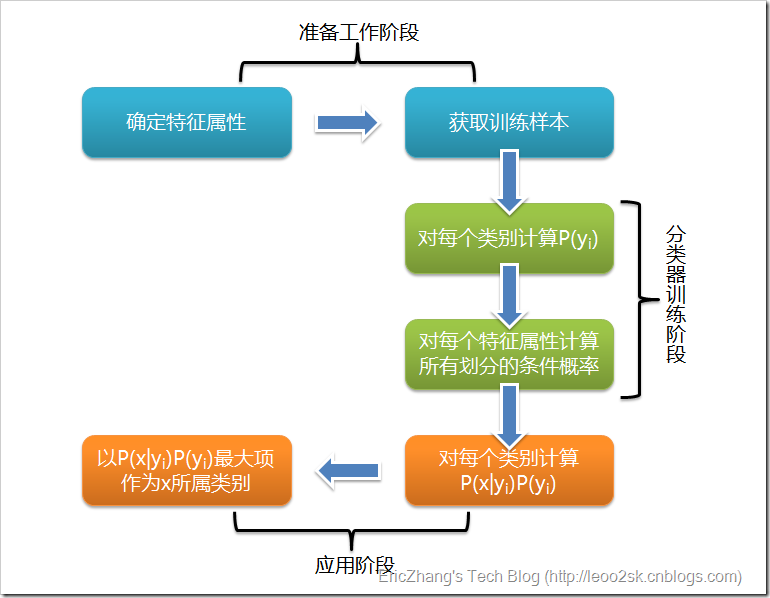
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
样本特征属性选择和数据处理
特征属性选择
在文章的开头就已经说明,朴素贝叶斯算法,人为的限制所有样本的特征属性独立。所以在选择特征属性的时候,应当注意选择权重较大,独立性较高的属性来作为特征属性。
拉普拉斯校准
细心阅读上面的内容,会发现如果一个待测样本的某一个特征属性在某个分类上出现的次数为0时,它将会导致整个分子的乘积为0,这有可能导致就算待测样本在其他属性上与一个已知分类一模一样,也不会被划分到该类。因此会大大降低整个分类的效果。与此同时,这种情况在现实生活中也是不被允许的。举个例子,就比如你今天穿了红上衣和妈妈打完招呼之后,高高兴兴的去上学,然后放学回家的路上掉到了水坑里,回家之后不得不换了一件黑上衣。此时你母亲再看到你的时候,不能因为你是黑上衣,就说你不是她的孩子。从机器学习的角度看,她会降低上衣颜色这个属性的权重,通过对其他属性的评估来确认。当然这个例子也不是太好,比较极端,但是它确实说明了问题的严重性。
因此,需要我们对整个数据进行处理。在这里的表现就是拉普拉斯校准。也就是当一个属性在分类中出现的词频是0的时候,我默认其为1,当然其他的样本的个数都要加1.相应的1变成2,2变成3。这样的话,保证了分子不为0,而且在数据量很大的情况下,它并不会影响结果。所以利用拉普拉斯校准解决了这个问题。
总结
朴素贝叶斯算法能够很好的完成分类工作,但是它人为强加的条件限制了它的使用场景。我在Hadoop下利用MapReduce实现了朴素贝叶斯算法,确实能够达到不错分类效果。如果有读者需要程序,可以发送邮件给我。希望各位读者对文章中出现的问题和错误进行斧正,欢迎大家一起探讨相关方面的问题
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 分类算法-朴素贝叶斯
- 分类算法:朴素贝叶斯
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- 朴素贝叶斯分类算法
- hexo使用畅言评论系统
- CentOS-6半自动化安装
- Javascript字符串判别相等
- 7类常用的dede模板开发标签
- 05 用xml文件可视化设计窗口布局
- 朴素贝叶斯分类算法
- POJ3669 Meteor Shower 流星雨【预处理】【广搜】
- Python学习之条件循环语句详解
- 指针总结
- 子集生成算法
- 【算法系列】—冒泡排序
- 给定入栈顺序,判断出栈顺序是否合法
- MVC模型和MVT模型
- 详解协方差与协方差矩阵


