KNN中的优化算法KD-tree
来源:互联网 发布:c语言联合 编辑:程序博客网 时间:2024/06/07 10:35
我们知道KNN是基于距离的一个简单分类算法,熟悉KNN的都知道,我们要不断计算两个样本点之间的距离,但是,试想一下,如果数据量特别大的时候,我们要每个都计算一下,那样计算量是非常大的,所以提出了一种优化KNN的算法-----kd-tree.
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。这在特征空间的维数大及训练数据容量大时尤其必要。k近邻法最简单的实现是线性扫描(穷举搜索),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。当训练集很大时,计算非常耗时。为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
构造平衡kd树算法:
输入: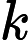
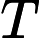

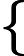





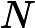
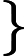

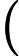
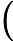
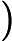
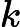

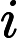


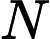

输出:kd树
(1)开始:构造根结点,根结点对应于包含T的k维空间的超矩形区域。选择
(2)重复。对深度为j的结点,选择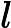
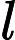
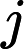
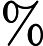

举个简单的例子:
下面用一个简单的2维平面上的例子来进行说明。
例. 给定一个二维空间数据集:
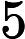


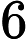
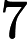
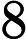
解:根结点对应包含数据集T的矩形,选择
这里注意一下:
从我们的数据集中可以看到,我们是二维的数据,x(1)是表示第一维的数据,x(2)是表示第二维的数据,在我们构造树求中位数的时候,我们先看低维的数据,也就是第一维的数据,即:x(1),在x(1)的基础上,先排序,然后再求中位数。然后再看根节点中位数左边和右边,这个时候注意啦,不是再看第一维了,而是看第二维了,也就是x(2),在x(2)的基础上,排序,求中位数。如果数据是3维,那么下一层就看第三维,。。以此反复类推下去。

kd树我们建立好了,那么我们现在需要来提高算法速度了。怎么做呢?
搜索kd树
利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。下面以搜索最近邻点为例加以叙述:给定一个目标点,搜索其最近邻,首先找到包含目标点的叶节点;然后从该叶结点出发,依次回退到父结点;不断查找与目标点最近邻的结点,当确定不可能存在更近的结点时终止。这样搜索就被限制在空间的局部区域上,效率大为提高。
用kd树的最近邻搜索:
输入: 已构造的kd树;目标点
输出:
(1) 在kd树中找出包含目标点
(2) 以此叶结点为“当前最近点”;
(3) 递归的向上回退,在每个结点进行以下操作:
(a) 如果该结点保存的实例点比当前最近点距目标点更近,则以该实例点为“当前最近点”;
(b) 当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一个子结点对应的区域是否有更近的点。具体的,检查另一个子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距离目标更近的点,移动到另一个子结点。接着,递归的进行最近邻搜索。如果不相交,向上回退。
(4) 当回退到根结点时,搜索结束。最后的“当前最近点”即为
注意:这里的搜索,也是跟上边构造一样,首先先搜索x(1),再搜索x(2)..以此类推下去。
以先前构建好的kd树为例,查找目标点(3,4.5)的最近邻点。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径:(7,2)→(5,4)→(4,7),取(4,7)为当前最近邻点。以目标查找点为圆心,目标查找点到当前最近点的距离2.69为半径确定一个红色的圆。然后回溯到(5,4),计算其与查找点之间的距离为2.06,则该结点比当前最近点距目标点更近,以(5,4)为当前最近点。用同样的方法再次确定一个绿色的圆,可见该圆和y = 4超平面相交,所以需要进入(5,4)结点的另一个子空间进行查找。(2,3)结点与目标点距离为1.8,比当前最近点要更近,所以最近邻点更新为(2,3),最近距离更新为1.8,同样可以确定一个蓝色的圆。接着根据规则回退到根结点(7,2),蓝色圆与x=7的超平面不相交,因此不用进入(7,2)的右子空间进行查找。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.8。

- KNN中的优化算法KD-tree
- KNN算法(基于KD-Tree)
- KD树在knn算法中的应用
- KNN与KD-tree
- kd-tree实现KNN
- kNN与KD-Tree
- KNN中的KD-tree的创建以及查找
- k近邻算法(KNN)及kd树简介(KD-Tree)
- 算法一 knn 扩展 BBF算法,在KD-tree上找KNN ( K-nearest neighbor)
- KNN算法,KD树实现
- KNN算法与Kd树
- KNN算法与Kd树
- K-means KNN AND KD-tree
- kd-tree算法(C)
- Kd-Tree算法
- pcl 中的 kd-tree
- 反距离权重法生成DEM(利用KD-tree实现KNN算法)
- KD tree算法(1)-简介&构建KD tree
- 对于Magento发送邮件的一点探讨
- 《IT老外在中国》第30期:“点燃中国开发者的激情,是我的责任”
- 摩托罗拉系统MOTOTRBO在华十周年:将组建一支团队深耕“定制化
- 没有IP何谈创新力,没有创新力何谈供给侧改革
- Windows对象
- KNN中的优化算法KD-tree
- 全网智联 通达全球
- 苹果WWDC2017的那些事儿:HomePod、iOS 11和iMac Pro
- 对话高通全球总裁Derek Aberle:谈谈高通在中国的合作、创新和最新业务
- 如何帮助中国8000万中小企业上云?阿里云交出了这样的答卷
- 评论:Google I\/O大会后 苹果应该深深畏惧谷歌了
- Linux驱动修炼之道-混杂设备
- 华为发布Matebook系列笔记本+平板 外观堪比MacBook
- 耐克推出多款Apple Watch表带 与其运动鞋相得益彰


