Batch Normalization
来源:互联网 发布:用友t3数据保存在哪 编辑:程序博客网 时间:2024/05/28 11:48
在传统的机器学习模型中,数据的归一化有助于模型的训练、收敛,同样,归一化这种方式也有利于深度模型的训练,但是鉴于深度网络的层次结构,输入数据的归一化效果很有可能在第一层网络之后就失去了。在这种情况下,针对每一层数据做归一化就尤为重要,但是做法又与传统方式略有不同,具体思想就体现在Batch Normalization这个操作中。
文章结构
- 归一化
- 归一化的作用
- 归一化的方法
- Min-Max Scaling
- Z-score
- Batch Normalization
- 主要思想
- 具体实现
- 卷积网络中的应用
- 总结
归一化
归一化的作用
在传统的机器学习模型中,归一化通常作为数据预处理的部分,对模型的收敛、训练加速起到了重要的作用。训练集数据的各个特征在各自的维度空间可能会有着不同的分布方式,而且有些特征的量纲可能很小或者很大,前者会带来拟合效率的低下,而后者则会造成模型过分依赖某些特征,而忽视了一些量纲较小的特征。假设一个数据集的特征数是2,其数据分布方式的具体表征如图-1所示:
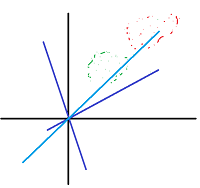
拟合曲线
我们想要在这个数据集上做一个分类任务,简单说,我们用一条直线$y=Wx+b$来将上图中的点分为一分为二。一般情况下,我们的参数都来自于高斯分布,甚至为0,这样的话,初始的分类线基本都是过原点的,显然这条初始的分类线需要经过迭代到达最优解。更形式化的说,如果我们的目标函数由两个不同量纲的参数组成,这个目标函数肯能是如下这种形状的,那么它的优化过程有可能是这样的:
显然,这种优化方式走了弯路。但是如果我们可以通过一种方式,让数据向分类线的初始位置靠近,让目标函数在各个参数上的分布更加均衡,不就可以加快优化速度了吗?使用归一化可以起到类似的作用。对上图中的数据做归一化,结果(PS:对均值和方差的要求只是一些归一化方法的要求)如图-2所示:
显然在这种数据分布下拟合会更加迅速。
归一化方法
Min-Max Scaling
Min-Max Scaling是一个线性方法,将数据线性的转化到[0,1]区间。
Z-Score
又称作零均值标准化,它是一种比归一化更强操作的归一化方法。将原始数据标准化到均值为0,方差为1,具体方式如下:
Z-Score方法可以有效消除量纲不同带来对距离、相似性、协方差计算带来的影响,所以要注意区分使用,另外值得注意的是,它将数据强行归一化到了均值为0,方差为1的高斯分布上(相应带来的遍历请参考这篇文章归一化与标准化),如果原始数据的分布与高斯分布迥异,那么会造成模型效果的下降。另外,值得注意的是,相较于普通的归一化,标准化的方式可以达到如下目的:
Data normalization can promote the performance in common machine learning problems. Most classifiers will calculate the Euclidean distance between two points. If one of the features has a broad range of values, the distance will be governed by this particular feature. Thus, the range of all features should be normalized so that each feature contributes approximately proportionately to the final distance.
Batch Normalization
主要思想
在传统的机器学习模型中,如果一个模型的输入是多变的,我们称这种情况叫做:Covariate Shfit。在深度网络训练中,每一层都可以看做是一个模型,一层网络参数的细微变动这每一个模型都希望有一个归一化(或标准化)的数据作为输入,以此加快训练速度。但是实际上,在BN出现之前,都没能实现有效的方法。在图像处理中,常见的方法是白化,但是因为要计算PCA、特征等,计算代价太大,更重要的是白化是一个不可导的过程,这就意味着无法通过反向传播来优化白化操作,所以白化操作也基本没被大家一致采用。
具体实现
Batch Normalization方法建立在Z-Socre标准化的基础上,其前向传播的算法流程如图-3所示:

Batch Normalization算法
- 针对每一个特征计算特征均值
- 计算方差
- 计算标准化后的特征
- 对标准化的结果做scale和shift
BN方法在传统的z-score方法基础上,做了第四步:scale和shift。论文中提到,$\gamma$,$\beta$的值分别设置为输入的方差和均值。很多人在此处会有疑问:这样的scale和shift将会抵消掉前面步骤所做的标准化,为什么要做这样一个操作呢?实际上,$\gamma,\beta$是两个有待优化的变量,设置为方差和均值只是这两个变量的初始值。$\gamma,\beta$的可优化性,使得神经网络可以通过训练自动去选择是否做标准化,以及标准化之后是否要做scale和shift,如果训练结束后,$\gamma,\beta$等于方差和均值,那就意味着神经网络认为不对该层的数据做标准化是最优的选择。
卷积网络的应用
Batch Normalization广泛应用于卷积网络结构。在GAN模型中,BN起到重要的作用。在常见的卷积神经网络中,BN一般应用于卷积之后,激活函数之前。相较于一维变量形式,BN在多维多通道数据上,是作用于channel上的。以下图为例,数据维度为[batch_size h w channels]:
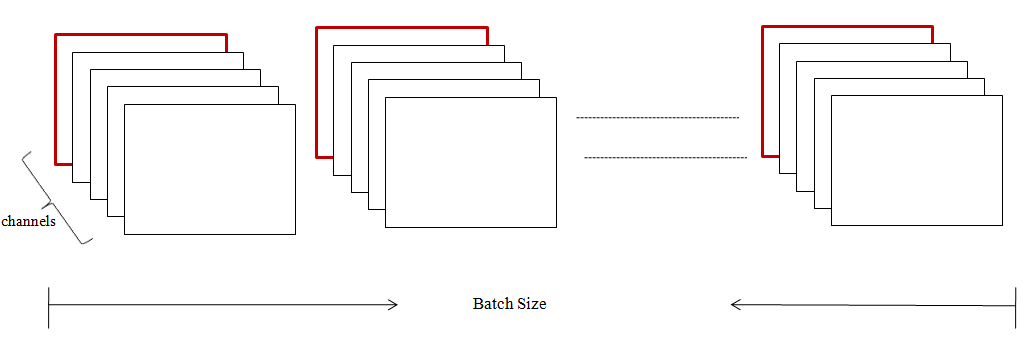
BN on Conv
在执行BN操作的时候,将所有样本在指定channel上的patch的值提取出来,计算均值和方差,所以最终的结果是一个一维的长为channels的向量。
总结
BN在深度网络中的应用使得训练得到加速。
- Batch Normalization
- Batch Normalization
- Batch Normalization
- batch normalization
- Batch Normalization
- Batch Normalization
- batch normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- Batch Normalization
- 清除元素
- Unity播放声音框架
- jupyter使用matplotlib
- 2017年全球大数据产业报告之海外篇(第五集)
- 【软件网每日新闻播报│第9-18期】
- Batch Normalization
- 使用Spring3.1后的的Profile配置使不同环境加载不同配置文件
- 2017年全球大数据产业报告之海外篇(终结篇)
- Apache-Tomcat的server.xml配置文件中Connector节点中URIEncoding的作用
- CSS居中的常用手段
- Part 4 Package与Import 定义一个圆类(Circle),其所在的包为bzu.info.software;定义一个圆柱类Cylinder,其所在的包为bzu.info.com;
- 推出Android原生开发工具包r16
- hiberate的org.hibernate.loader.custom.NonUniqueDiscoveredSqlAliasException异常解决
- 快把Oracle从云的世界弄走!


