备忘--python常见面试题
来源:互联网 发布:北大光华mba知乎 编辑:程序博客网 时间:2024/05/18 03:07
一、理想公司:
1、迭代器
用for循环迭代的对象都是Iterable类型,用next()内置函数取值的对象都是Iterator类型,表示一个惰性计算的序列,Iterable均可通过内置函数iter(),获得一个Iterator对象。
for循环内部实现机制就是先iter()再反复next()
2、生成器
生成器是一次生成一个值的特殊类型函数(特殊的迭代器),其最大的作用是将输入对象返回为一个迭代器。
有两点要先明确:
任意生成器都是迭代器(反之,不成立)
任意生成器,都是一个可以延迟创建值的工厂(可控性)
这里有个关于生成器的创建问题面试官有考:
问:将列表生成式中[]改成() 之后数据结构是否改变?
答案:是,从列表变为生成器
>>> L = [x*x for x in range(10)]>>> L[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]>>> g = (x*x for x in range(10))>>> g<generator object <genexpr> at 0x0000028F8B774200>通过列表生成式,可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含百万元素的列表,不仅是占用很大的内存空间,如:我们只需要访问前面的几个元素,后面大部分元素所占的空间都是浪费的。因此,没有必要创建完整的列表(节省大量内存空间)。在Python中,我们可以采用生成器:边循环,边计算的机制—>generator
另外就是关键字yield创建生成器,可以把函数变为生成器,可以参考协程来比较学习
3、列表生成式应用
>>> [x * x for x in range(1, 11) if x % 2 == 0][4, 16, 36, 64, 100]>>> [m + n for m in 'ABC' for n in 'XYZ']['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']4、HTTP 8种方法
HTTP请求方法介绍
HTTP/1.1协议中共定义了8种HTTP请求方法,HTTP请求方法也被叫做“请求动作”,不同的方法规定了不同的操作指定的资源方式。服务端也会根据不同的请求方法做不同的响应。
GET
GET请求会显示请求指定的资源。一般来说GET方法应该只用于数据的读取,而不应当用于会产生副作用的非幂等的操作中。
GET会方法请求指定的页面信息,并返回响应主体,GET被认为是不安全的方法,因为GET方法会被网络蜘蛛等任意的访问。
HEAD
HEAD方法与GET方法一样,都是向服务器发出指定资源的请求。但是,服务器在响应HEAD请求时不会回传资源的内容部分,即:响应主体。这样,我们可以不传输全部内容的情况下,就可以获取服务器的响应头信息。HEAD方法常被用于客户端查看服务器的性能。
POST
POST请求会 向指定资源提交数据,请求服务器进行处理,如:表单数据提交、文件上传等,请求数据会被包含在请求体中。POST方法是非幂等的方法,因为这个请求可能会创建新的资源或/和修改现有资源。
PUT
PUT请求会身向指定资源位置上传其最新内容,PUT方法是幂等的方法。通过该方法客户端可以将指定资源的最新数据传送给服务器取代指定的资源的内容。
DELETE
DELETE请求用于请求服务器删除所请求URI(统一资源标识符,Uniform Resource Identifier)所标识的资源。DELETE请求后指定资源会被删除,DELETE方法也是幂等的。
CONNECT
CONNECT方法是HTTP/1.1协议预留的,能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接与非加密的HTTP代理服务器的通信。
OPTIONS
OPTIONS请求与HEAD类似,一般也是用于客户端查看服务器的性能。 这个方法会请求服务器返回该资源所支持的所有HTTP请求方法,该方法会用’*’来代替资源名称,向服务器发送OPTIONS请求,可以测试服务器功能是否正常。JavaScript的XMLHttpRequest对象进行CORS跨域资源共享时,就是使用OPTIONS方法发送嗅探请求,以判断是否有对指定资源的访问权限。 允许
TRACE
TRACE请求服务器回显其收到的请求信息,该方法主要用于HTTP请求的测试或诊断。
HTTP/1.1之后增加的方法
在HTTP/1.1标准制定之后,又陆续扩展了一些方法。其中使用中较多的是 PATCH 方法:
PATCH
PATCH方法出现的较晚,它在2010年的RFC 5789标准中被定义。PATCH请求与PUT请求类似,同样用于资源的更新。二者有以下两点不同:
但PATCH一般用于资源的部分更新,而PUT一般用于资源的整体更新。
当资源不存在时,PATCH会创建一个新的资源,而PUT只会对已在资源进行更新。
5、用Django做Restful API
可以用django-rest-framework来做
参考:http://www.jianshu.com/p/653a0a5684eb
6、Django的中间件怎么用
就像Flask里面的钩子作用一样,写法就是写好中间件然后注册到setting上面即可.
参考:http://blog.csdn.net/u013205877/article/details/77479056
参考:http://www.jianshu.com/p/96f2fa90f031
7、Django的makemessage
国际化生成翻译文件所用:http://code.ziqiangxuetang.com/django/django-internationalization.html
8、Django的信号
注册回调函数
https://segmentfault.com/a/1190000008455657
https://my.oschina.net/liuyuantao/blog/1098858
http://www.cnblogs.com/qwj-sysu/p/4224805.html
9、Django的auth_user怎么扩展
OneToOneField方式\继承
https://my.oschina.net/watcher/blog/848565
http://python.usyiyi.cn/documents/django_182/topics/auth/customizing.html#extending-user
10、Django的三种继承方式的使用
抽象类继承\多表继承\代理模型继承
python高效开发实战这本书P202
11、列表排序和转换
dasa = [8, 2, 3, 4, 2, 4, 6]dddddd = dasa.sort()print(dasa)输出:[2, 2, 3, 4, 4, 6, 8]print(dddddd)输出:Nonedddddd = sorted(dasa)print(dddddd)输出:[2, 2, 3, 4, 4, 6, 8]12、自定义装饰器
# 装饰器是一个函数,而其参数为另外一个函数def my_shiny_new_decorator(a_function_to_decorate) : # 在内部定义了另外一个函数:一个封装器。 # 这个函数将原始函数进行封装,所以你可以在它之前或者之后执行一些代码 def the_wrapper_around_the_original_function() : # 放一些你希望在真正函数执行前的一些代码 print "Before the function runs" # 执行原始函数 a_function_to_decorate() # 放一些你希望在原始函数执行后的一些代码 print "After the function runs" #在此刻,"a_function_to_decrorate"还没有被执行,我们返回了创建的封装函数 #封装器包含了函数以及其前后执行的代码,其已经准备完毕 return the_wrapper_around_the_original_functionhttp://blog.csdn.net/u013205877/article/details/71158228
13、可变对象和不可变对象的应用场景
14、nginx和apache区别
nginx 相对 apache 的优点:
轻量级,同样起web 服务,比apache 占用更少的内存及资源
抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能
高度模块化的设计,编写模块相对简单
社区活跃,各种高性能模块出品迅速啊
apache 相对nginx 的优点:
rewrite ,比nginx 的rewrite 强大
模块超多,基本想到的都可以找到
少bug ,nginx 的bug 相对较多
超稳定
作者:陈湛翀
链接:https://www.zhihu.com/question/19571087/answer/12313829
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
上面来自知乎的是比较久远且政治正确的回答,建议看看这个:http://www.yunweipai.com/archives/7971.html
15、闭包处理结果分辨
python循环中不包含域的概念。
flist = []for i in range(3): def func(x): return x*i flist.append(func)for f in flist: print(f(2))按照大家正常的理解,应该输出的是0, 2, 4对吧?但实际输出的结果是:4, 4, 4. 原因是什么呢?loop在python中是没有域的概念的,flist在像列表中添加func的时候,并没有保存i的值,而是当执行f(2)的时候才去取,这时候循环已经结束,i的值是2,所以结果都是4。
ps:补充说明:
这之所以会发生是由于Python中的“后期绑定”行为——闭包中用到的变量只有在函数被调用的时候才会被赋值。所以,在上面的代码中,任何时候,当返回的函数被调用时,Python会在该函数被调用时的作用域中查找 i 对应的值(这时,循环已经结束,所以 i 被赋上了最终的值2)
其实修改方案也挺简单的:
flist = []for i in range(3): def makefunc(i): def func(x): return x*i return func flist.append(makefunc(i))for f in flist: print(f(2))在func外面再定义一个makefunc函数,func形成闭包,结果就正确了。
划重点!敲黑板!!!!
返回闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变
二、微步在线:
1、手写最大堆最小堆排序
一般用数组表示堆,如果根节点存在序号0处,i节点的父节点下标就是(i-1)/2,i节点的子节点分别是2*i+1、2*i+2 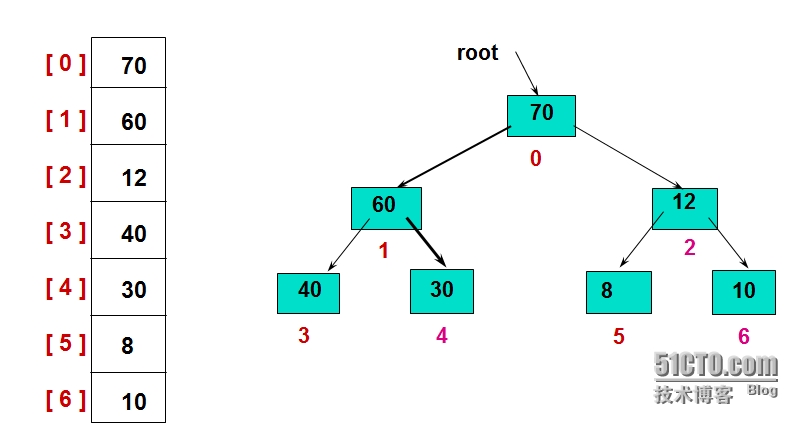
def filter_down(attr, start, end): root = start while True: child = 2 * root + 1 if child > end: break # if child + 1 <= end and attr[child] < attr[child + 1]: print 'child is: ******** > ', child print 'end is: >>>> ',end if child + 1 < end and attr[child] < attr[child + 1]: child += 1 if attr[root] < attr[child]: temp = attr[root] attr[root] = attr[child] attr[child] = temp root = child else: break print '把每个子树都变为最大堆形式: > ', attrdef heap_sort(attr): attr_num = len(attr) - 1 sort_num = len(attr) // 2 -1 for index in range(sort_num, -1, -1): filter_down(attr, index, attr_num) print '得到最大堆: ', attr for end_index in range(attr_num, -1, -1): print ' choose end is ***** >>>>> ', end_index temp = attr[0] attr[0] = attr[end_index] attr[end_index] = temp filter_down(attr, 0, end_index - 1) print '得到最小堆: ', attrif __name__ == '__main__': attr_list = [7, 50, 42, 37, 3, 71, 83, 87, 94, 12] heap_sort(attr_list) print '########################'http://jx610.blog.51cto.com/5113370/1702260
http://blog.csdn.net/nfzhlk/article/details/77726436
2、top k 问题(100万日志求前10的数据)
http://www.jianshu.com/p/5fe0de66f2a6
3、python是否多继承,对于父类属性的搜索是广度优先还是深度优先
新式类class Myclass(object)支持多继承,而且多继承时,到父类寻找本类中不存在的属性时,从以前的深度优先搜索改为了广度优先搜索。这样改的原因,也是跟新式类的类继承的层级关系有关。对于Class A(B,C),如果仍用深度优先搜索,会从B一直向上递归搜索到object基类,这样在继承较多类时,每次都会重复的去访问object基类,很降低效率。
4、一个数组每隔一个数打印一次,有几种实现方法
用下标,用range的步长
5、对java和php的要求
三、天启智创:
- redis的应用场景
https://my.oschina.net/stefanzhlg/blog/336880 - restful api的数据交互方式使用经验与应用场景,支持哪些数据类型
https://www.ibm.com/developerworks/cn/web/1103_chenyan_restapi/ - 对装饰器的理解+
http://blog.csdn.net/u013205877/article/details/71158228 - 对mysql索引的原理,应用场景
http://blog.csdn.net/slvher/article/details/42239269 - Django中消息队列,中间件,信号等等是否用到
四、多牛:
1、
print("%.02f" % "1.333")2、
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))print A0A1 = range(10)print A1A2 = [i for i in A1 if i in A0]print A2A3 = [A0[s] for s in A0]print A3输出
{'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4}[0, 1, 2, 3, 4, 5, 6, 7, 8, 9][][1, 3, 2, 5, 4]3、
class A(object): def go(self): print "GO A"class B(A): def go(self): super(B, self).go() print "GO B"class C(A): def go(self): super(C, self).go() print "GO C"class D(B,C): def go(self): super(D, self).go() print "GO D"A().go()B().go()C().go()D().go()输出:
GO AGO AGO BGO AGO CGO D4、写一个函数实现如下功能,返回1到10亿之间的所有素数
from math import sqrtdef primeNumber(n): for i in range(2,n): flg=True for j in range(2,int(sqrt(i))+1): if (i%j == 0): flg=False if(flg==True): print(i)primeNumber(1000000000)除余法介绍:
https://yq.aliyun.com/articles/90564
筛法介绍:
http://blog.csdn.net/controlfate/article/details/6758202
5、以升序的方式融合这两个列表
List1 = [2,4,5,9,20,8,7]
List2 = [21,25,42,39,8]
并返回融合后的列表,要求不能使用python自带的sort、list.sort函数
List1 = [2,4,5,9,20,8,7]List2 = [21,25,42,39,8]def quicksort(arr): if len(arr)<2: return arr mid = arr[0] before = [i for i in arr[1:] if i <= mid] after = [i for i in arr[1:] if i > mid] finallylist = quicksort(before)+[mid]+quicksort(after) return finallylistprint(quicksort(List1+List2))五、头条:
http状态码常见哪些,304状态码含义,302含义
http://blog.csdn.net/u013205877/article/details/77454102装饰器定义使用,写一个带参数调用的装饰器
http://blog.csdn.net/dreamcoding/article/details/8611578- 将序列[1,2,3,4,5……100]切片,提取返回后50个数之中为偶数的部分
- 将链表1->2->3->4翻转为4->3->2->1
- 备忘--python常见面试题
- 常见python面试题
- Python常见面试题
- python常见面试题
- python常见面试题
- python 常见面试题整理
- 常见的Python面试题
- 常见面试题整理---Python代码篇
- 常见的Python面试题+详细解答
- 一.python 常见面试题11题
- 常见python面试题 -- 手写代码系列
- python正则表达式常见面试题
- 常见面试题整理--Python概念篇
- Python 常见面试题(不断更新)
- 面试题备忘
- 一些面试题备忘
- Python学习笔记5--常见笔面试题整理
- python中常见的15中面试题
- flume使用之httpSource
- 为什么你的手机会越用越卡,那是你不知道这些
- 关于物联网平台 你想知道的都在这里!
- 试图编译lantern android
- Failed to resolve: com.facebook.fresco:fresco:0.6.0
- 备忘--python常见面试题
- Zabbix中文乱码的解决方法
- spring+mybatis报错:Caused by: org.springframework.beans.factory.BeanCreationException: Error creating
- C语言字符串处理的一些函数strok,strstr, strchr,strsub
- UVALive
- Java WebService 简单实例(有图)
- 【PHP】使用MySQLi方式连接数据库,增删改查
- CEOI2017 day1-Sure Bet【三分】
- leetcode Reverse String II 反转字符串


