redis 网络分区
来源:互联网 发布:网络综艺访谈节目 编辑:程序博客网 时间:2024/06/06 04:17
网络分区
分布式通常假设网络是异步的,意味着网络可能会导致任意的重复、丢失、延迟或者乱序的节点间消息传递。在实际中,TCP状态机会保证节点间消息传递的不丢失、不重复、时序。但是,在Socket级别上,节点接发消息会阻塞,超时等等。
检测到网络失败是困难,因为我们唯一能跟得到其他节点状态的信息就是通过网络来得到,延迟跟网络失败也无从区分。这里就会产生一个基本的网络分区问题:高延迟可以考虑作为失败。当分区产生后,我们没有渠道去了解到其他节点到底发生了什么事: 它们是否还存活?或者已经crash?是否有收到消息?是否正在尝试回应。当网络最终恢复后,我们需要重新建立连接然后尝试解决在不一致状态时的不一致。
很多系统在解决分区时会进入一个特殊的降级操作模式。CAP理论也告诉我们妖么得到一致性要么高可用性,但是很少有数据库系统能够达到CAP理论的极限,多数只是丢失数据。
Redis
Redis通常被视为一个共享的heap,因为它容易理解的一致性模型,很多用户把Redis作为消息队列、锁服务或者主要数据库。Redis在一个server上运行实例视为CP系统(CAP理论),因此一致性是它的主要目的。 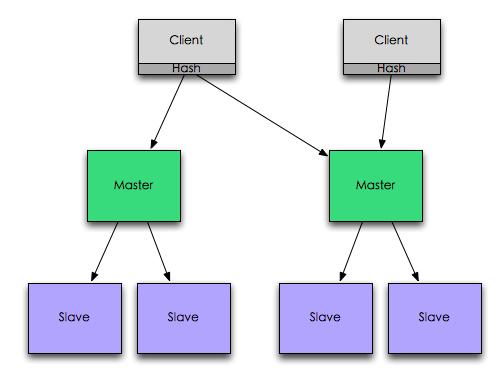
Redis集群通常是主备,primary node负责写入和读取,而slave node只是用来备份。当primary node失败时,slave node有机会被提升为primary node。但是因为primary node和slave node之间是异步传输,因此slave node被提升为primary node后会导致0~N秒的数据丢失。此时Redis的一致性已经被打破,Redis这个模式的集群不是一个CP系统!
Redis有一个官方组件叫Sentinel(参考Redis Sentinel,它是通过类似Quorum的方式来连接Sentinel instance,然后检测Redis集群的状态,对故障的primary节点试用slave节点替换。Redis官方号称这个是HA solution,通过Redis Sentinel来构建一个CP系统。
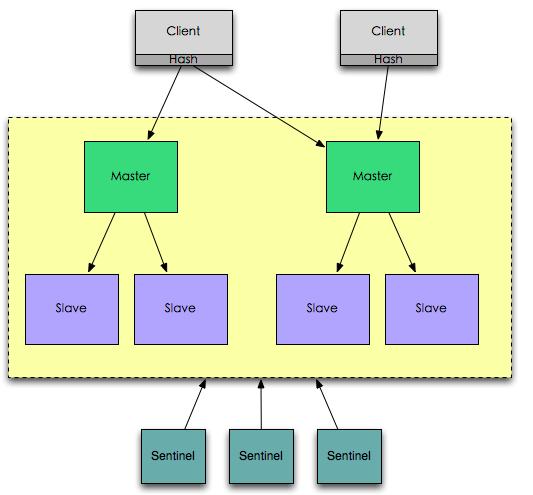
考虑Redis Sentinel在网络分区时候的情况,这时Redis集群被网络分成两部分,Redis Sentinel在的大区域可能会提升Slave node作为primary node。如果这时候一直client在连接原来的primary node,这时会出现两个primary node(split-brain problem,脑裂问题)!也就是说,Redis Sentinel并没有阻止client连接Old primary node。在此时,已经连接到old primary node的client会写入old primary node,新的client会写入到new primary node。此时,CP系统已经完全瘫痪。虽然Redis集群一直是保持运行的,但是因为依赖于Quorum来提升slave节点,因此它也不会是AP系统。
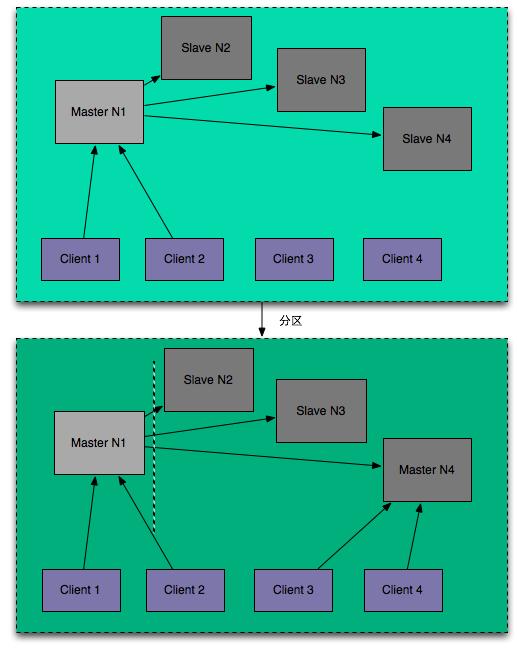
如果使用Redis作为Lock service,那么这个问题会成为致命问题。这会导致分区后同时可以有两个client获取同一个锁并成功,lock service必须是严格的CP系统,像Zookeeper。
如果使用Redis作为queue,那么你需要接受一个item可能会被分发零次、一次或者两次等等,大部分的分布式队列都保证最多只分发一次或者最少分发一次,CP系统会提确切一次的分发然后带来较高的延迟。你需要明确使用Redis作为队列服务的话必须要接受网络分区后队列服务可能导致的不稳定。
如果使用Redis作为database,那么可想而知,利用Redis Sentinel建立的database是不能称为database的。
最后,以目前的Redis来说,使用官方提供的组件它只能成为Cache
参考文档
网络分区带给分布式数据库的难题如何解决?
- redis 网络分区
- Redis分区
- Redis分区
- Redis 分区
- Redis分区
- Redis学习之Redis分区
- Redis 分区实现原理
- Redis怎么分区
- Redis 分区 详解
- Redis分区理论知识
- 模拟RabbitMQ网络分区
- 分布式系统与网络分区
- RabbitMQ 集群与网络分区
- 分布式系统与网络分区
- 使用Redis分区将数据分割到多个Redis实例
- 【09-Redis-分区:怎样将数据分布到多个redis实例】
- redis 之网络模型
- redis网络层学习
- Goroutine的调度分析(二)
- android NDK--C 调用java
- 某集训记录
- 高并发秒杀系统实现和优化分析(行级锁优化和具体过程优化)
- cenos7安装elasticsearch5.5.2
- redis 网络分区
- Mysql课后思考题
- 栈的应用2--通用括号平衡
- Mysql综合案例
- ADODB.Connection对象的Execute方法
- 国庆去哪人少,大数据来告诉你
- 最近最少使用
- redis 主从复制
- MySql阶段案例


