从零开始写Python爬虫 --- 1.6 爬虫实践: DOTA'菠菜'结果查询
来源:互联网 发布:最简单的网络贷款平台 编辑:程序博客网 时间:2024/04/30 21:06
从零开始写Python爬虫 --- 1.6 爬虫实践: DOTA'菠菜'结果查询
说起来目录里面本来是准备双色球信息查询的,但是我一点都不懂这个啊,恰好身边有个老赌棍,沉迷Dota饰品交易,俗称 “菠菜”。老赌棍啊,老赌棍,能不能不要每天我说天台见。。。
这次的爬虫功能十分的简答,主要目的是延展一下bs4库的使用。
目标分析:
我们查询比赛结果的网址是:http://dota2bocai.com/match
看一看网站里的信息是怎么排列的:

和上一次一样 我们使用开发者工具,快速定位到比赛结果的div中:
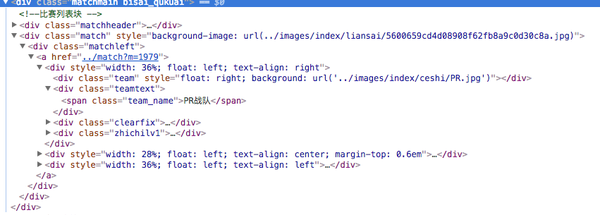
有了上一次爬取百度贴吧的经验。我们很容易就能发现,每一场比赛的信息都保存在:
<div class="matchmain bisai_qukuai">这个div中。
这样我们先利用bs4库的findall()方法抓取到每个div,
再循环遍历出每一条我们需要的信息就大功告成了!
代码的实现:
抓取头:
依旧是我们经常用的抓网页到本地的代码框架,
def get_html(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return " ERROR "主要处理函数:
def print_result(url): ''' 查询比赛结果,并格式化输出! ''' html = get_html(url) soup = bs4.BeautifulSoup(html,'lxml') match_list = soup.find_all('div', attrs={'class': 'matchmain bisai_qukuai'}) for match in match_list: time = match.find('div', attrs={'class': 'whenm'}).text.strip() teamname = match.find_all('span', attrs={'class': 'team_name'}) #由于网站的构造问题,队名有的时候会不显示,所以我们需要过滤掉一些注释,方法如下: if teamname[0].string[0:3] == 'php': team1_name = "暂无队名" else: team1_name = teamname[0].string # 这里我们采用了css选择器:比原来的属性选择更加方便 team1_support_level = match.find('span', class_='team_number_green').string team2_name = teamname[1].string team2_support_level = match.find('span', class_='team_number_red').string print('比赛时间:{},\n 队伍一:{} 胜率 {}\n 队伍二:{} 胜率 {} \n'.format(time,team1_name,team1_support_level,team2_name,team2_support_level))这里有些内容要想说一下:
- bs4css选择器的使用:
原来我们在文档中查询tag的时候,总是习惯使用这个方法:
find_all('name',attrs={})
这个方法的的确是很方便的帮我们定位元素,
之前的查询中,我们只用到attrs={}字典中的一个class值。
如果单单通过class属性来定位我们有更好的方式:css选择器:
语法:
soup.find_all("a", class_="xxx")
这样我们就能迅速的找到soup中的class为‘xxx’的元素了
- Comment类型的注释文件:
这次我们在爬取的时候,由于网站可能没做好,有的队伍名字查询不到,就会显示一个php的查询注释:
<div class="teamtext"><span class="team_name"><?php phpinfo(); ?></span></div>`这里我选择了硬编码的方式来解决:
#由于网站的构造问题,队名有的时候会不显示,所以我们需要过滤掉一些注释,方法如下: if teamname[0].string[0:3] == 'php': team1_name = "暂无队名" else: team1_name = teamname[0].string由于是十分小的项目,可以这样解决,但是如果是较大,
并且需要复用的情况,
我们来看看推荐的做法:
html = '''<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>'''#可以看到,a标签下的内容是一个注释类型,但是如果我们直接输出它的话#会输把注释符号去掉的 Elsie:print(soup.a.string) #Elsie#所以为了过滤掉注释类型,我们可以这样做:if type(soup.a.string)==bs4.element.Comment: //TO DO#上面通过一个简单的类型判断解决了这个问题。整体代码:
'''爬取Dota菠菜结果信息使用 requests --- bs4 线路Python版本: 3.6OS: mac os 12.12.4'''import requestsimport bs4def get_html(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return " ERROR "def print_result(url): ''' 查询比赛结果,并格式化输出! ''' html = get_html(url) soup = bs4.BeautifulSoup(html,'lxml') match_list = soup.find_all('div', attrs={'class': 'matchmain bisai_qukuai'}) for match in match_list: time = match.find('div', attrs={'class': 'whenm'}).text.strip() teamname = match.find_all('span', attrs={'class': 'team_name'}) #由于网站的构造问题,队名有的时候会不显示,所以我们需要过滤掉一些注释,方法如下: if teamname[0].string[0:3] == 'php': team1_name = "暂无队名" else: team1_name = teamname[0].string # 这里我们采用了css选择器:比原来的属性选择更加方便 team1_support_level = match.find('span', class_='team_number_green').string team2_name = teamname[1].string team2_support_level = match.find('span', class_='team_number_red').string print('比赛时间:{},\n 队伍一:{} 胜率 {}\n 队伍二:{} 胜率 {} \n'.format(time,team1_name,team1_support_level,team2_name,team2_support_level))def main(): url= 'http://dota2bocai.com/match' print_result(url)if __name__ == '__main__': main()爬取结果:
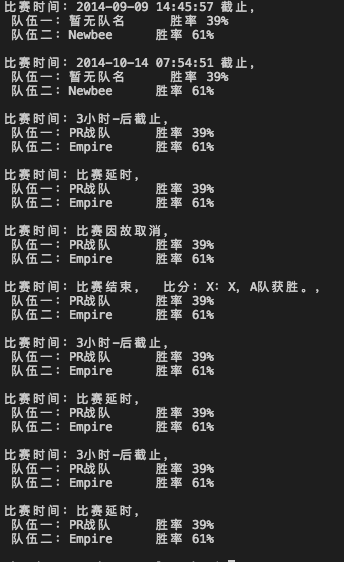
经过这两个小例子,大家也可以开始动手去写自己的爬虫了
你可能会遇到很多小问题,不要畏惧,一点一点的去解决
看着debug信息,遇到不懂的就去Google,其实我们遇到的很多问题,
前人都已经遇到过,并且大多数时候都有很好地解决办法。
如果还是不能解决,欢迎在我这里留言~
每天的学习记录都会 同步更新到:
微信公众号: findyourownway
知乎专栏:从零开始写Python爬虫 - 知乎专栏
blog : www.ehcoblog.ml
Github: Ehco1996/Python-crawler
- 从零开始写Python爬虫 --- 1.6 爬虫实践: DOTA'菠菜'结果查询
- 从零开始写Python爬虫 --- 1.9 爬虫实践:悦音台mv排行榜与反爬虫技术
- 从零开始写Python爬虫 --- 导言
- 从零开始写Python爬虫 --- 1.5 爬虫实践: 获取百度贴吧内容
- 从零开始写Python爬虫 --- 1.7 爬虫实践: 排行榜小说批量下载
- Python--从零开始学会写爬虫(Python)
- python从零开始写爬虫(2)
- python从零开始写爬虫(3)
- 从零开始写爬虫111
- python从零开始写爬虫(1)-- 开发环境搭建
- python从零开始写爬虫(4)-- 整合代码
- python从零开始写爬虫(5)-- 数据入库
- Python从零开始写爬虫(一)requests库使用
- Python从零开始写爬虫(二)BeautifulSoup库使用
- 从零开始写Python爬虫 --- 1.3 BS4库的解析器
- 从零开始写Python爬虫 --- 1.4 正则表达式:re库
- python爬虫入门实践
- Python爬虫Scrapy实践
- Web Service (003---WebService概念)
- Windows Practice_Socket
- centos7使用yum安装mariaDB(开源MySQL)无法启动的解决办法
- 几种可以让元素水平垂直居中的方法
- [BZOJ]2161: 布娃娃 权值线段树
- 从零开始写Python爬虫 --- 1.6 爬虫实践: DOTA'菠菜'结果查询
- BZOJ 2152: 聪聪可可 分治
- Training RNNs as Fast as CNNs
- HTML <dl> 标签
- 将“在此处打开命令窗口”添加到右键菜单
- 阿里云ECS使用过程中遇到的坑
- 模板--快速幂及矩阵快速幂
- poj2485 highways 之prim解法
- 详解ImageNet 2017夺冠架构SENet


