Faster RCNN 推荐区域理解
来源:互联网 发布:windows字体安装包 编辑:程序博客网 时间:2024/05/16 10:11
主要的原因还是提proposal(最后输出将全连接换成全卷积也是一点)。其实总结起来我认为有两种方式:1.RPN,2. 暴力划分。RPN的设计相当于是一个sliding window 对最后的特征图每一个位置都进行了估计,由此找出anchor上面不同变换的proposal,设计非常经典,代价就是sliding window的代价。相比较 yolo比较暴力 ,直接划为7*7的网格,估计以网格为中心两个位置也就是总共98个”proposal“。快的很明显,精度和格子的大小有关。SSD则是结合:不同layer输出的输出的不同尺度的 Feature Map提出来,划格子,多种尺度的格子,在格子上提“anchor”。结果显而易见。
还需要说明一个核心: 目前虽然已经有更多的RCNN,但是Faster RCNN当中的RPN仍然是一个经典的设计。下面来说一下RPN:(当然你也可以将YOLO和SSD看作是一种RPN的设计)
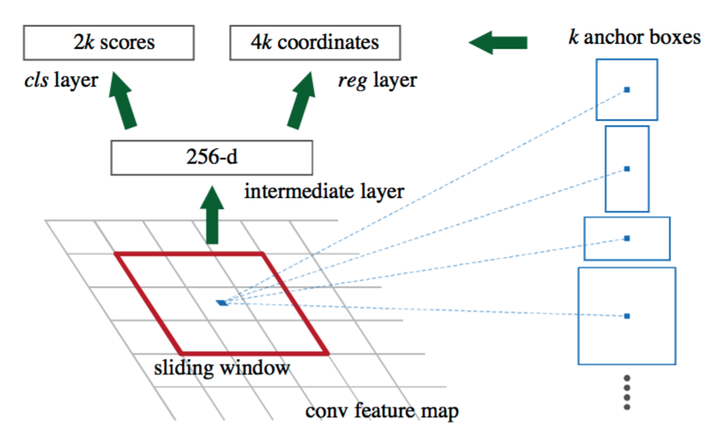
在Faster RCNN当中,一张大小为224*224的图片经过前面的5个卷积层,输出256张大小为13*13的 特征图(你也可以理解为一张13*13*256大小的特征图,256表示通道数)。接下来将其输入到RPN网络,输出可能存在目标的reign WHk个(其中WH是特征图的大小,k是anchor的个数)。
实际上,这个RPN由两部分构成:一个卷积层,一对全连接层分别输出分类结果(cls layer)以及 坐标回归结果(reg layer)。卷积层:stride为1,卷积核大小为3*3,输出256张特征图(这一层实际参数为3*3*256*256)。相当于一个sliding window 探索输入特征图的每一个3*3的区域位置。当这个13*13*256特征图输入到RPN网络以后,通过卷积层得到13*13个 256特征图。也就是169个256维的特征向量,每一个对应一个3*3的区域位置,每一个位置提供9个anchor。于是,对于每一个256维的特征,经过一对 全连接网络(也可以是1*1的卷积核的卷积网络),一个输出 前景还是背景的输出2D;另一个输出回归的坐标信息(x,y,w, h,4*9D,但实际上是一个处理过的坐标位置)。于是,在这9个位置附近求到了一个真实的候选位置。
下面是整个faster RCNN结构的示意图:
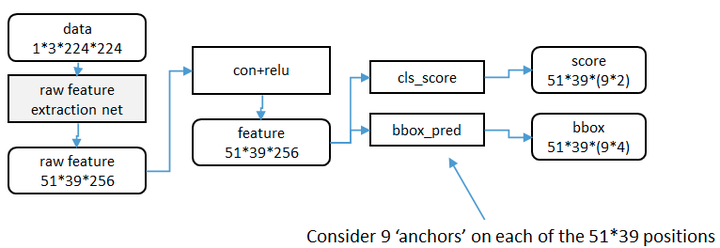
利用anchor是从第二列这个位置开始进行处理,这个时候,原始图片已经经过一系列卷积层和池化层以及relu,得到了这里的 feature:51x39x256(256是层数)
在这个特征参数的基础上,通过一个3x3的滑动窗口,在这个51x39的区域上进行滑动,stride=1,padding=2,这样一来,滑动得到的就是51x39个3x3的窗口。
对于每个3x3的窗口,作者就计算这个滑动窗口的中心点所对应的原始图片的中心点。然后作者假定,这个3x3窗口,是从原始图片上通过SPP池化得到的,而这个池化的区域的面积以及比例,就是一个个的anchor。换句话说,对于每个3x3窗口,作者假定它来自9种不同原始区域的池化,但是这些池化在原始图片中的中心点,都完全一样。这个中心点,就是刚才提到的,3x3窗口中心点所对应的原始图片中的中心点。如此一来,在每个窗口位置,我们都可以根据9个不同长宽比例、不同面积的anchor,逆向推导出它所对应的原始图片中的一个区域,这个区域的尺寸以及坐标,都是已知的。而这个区域,就是我们想要的 proposal。所以我们通过滑动窗口和anchor,成功得到了 51x39x9 个原始图片的proposal。接下来,每个proposal我们只输出6个参数:每个 proposal 和 ground truth 进行比较得到的前景概率和背景概率(2个参数)(对应图上的 cls_score);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的4个平移放缩参数(对应图上的 bbox_pred)。
- Faster RCNN 推荐区域理解
- faster rcnn源码理解
- faster rcnn 论文理解
- Faster RCNN理解
- tf-faster-rcnn代码理解
- Faster RCNN的理解点
- faster RCNN 的细节理解
- Faster RCNN-阅读理解-笔记
- Faster RCNN代码理解(Python)
- Faster RCNN代码理解(Python)
- Faster RCNN代码理解(Python)
- Faster RCNN代码理解(Python)
- Faster RCNN代码理解(Python)
- faster-rcnn中,对RPN的理解
- Faster RCNN 中 RPN 的理解
- Faster RCNN代码理解(Python)
- 【转】Faster RCNN代码理解(Python)
- Faster-RCNN 理解篇 -- 资源收集
- 机器学习笔记--朴素贝叶斯 &三种模型&sklearn应用
- 使用CSS3绘制简单的Android机器人
- java并发编程简单分析
- Problem G. Graph 2015-2016 acmicpc neerc 拓扑排序模拟
- 旧电脑加速
- Faster RCNN 推荐区域理解
- AtomicInteger实现
- LeetCode | 两数之和
- python3 map函数
- 第三章(列表)
- ConcurrentLinkedQueue & CopyOnWriteArrayList
- (二)spring cloud微服务分布式云架构
- CyclicBarrier实现原理
- ReentrantLock实现原理


