BeautifulSoup 库学习笔记
来源:互联网 发布:c语言编程器下载 编辑:程序博客网 时间:2024/05/22 06:19
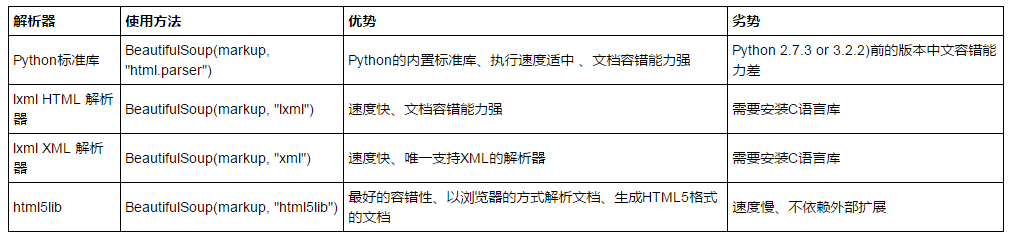
1、常用解析库
2、BeautifulSoup的基本使用
frombs4importBeautifulSoup
html ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#美化后补全输出
print(bs4.prettify())
#输出title标签中的内容
print(bs4.title.string)
3、BeautifulSoup标签选择器的用法
3.1、选择元素
frombs4importBeautifulSoup
html ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出title标签 <title>The Dormouse's story</title>
print(bs4.title)
#输出获取到title标签的类型 <class 'bs4.element.Tag'>
print(type(bs4.title))
#输出head标签
print(bs4.head)
#输出获取到head标签的类型 <class 'bs4.element.Tag'>
print(type(bs4.head))
#获取到head标签中的title标签
print(bs4.head.title)
#输出p标签(只输出第一个)
print(bs4.p)
从上述的代码中可以看出,BeautifulSoup解析出的标签返回任然是一个BeautifulSoup的Tag类,可以再次进行筛选
3.2、获取名称
frombs4importBeautifulSoup
html ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#获取选择的标签的名称 title
print(bs4.title.name)
3.3、获取属性
frombs4importBeautifulSoup
html ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出p标签的name属性值
print(bs4.p['name'])
#输出p标签的name属性值
print(bs4.p.attrs['name'])
3.4、获取内容
frombs4importBeautifulSoup
html ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出title标签中的内容
print(bs4.title.string)
#输出a标签中的内容(去除html标签包括注释)
print(bs4.a.string)
3.5、嵌套选择
frombs4importBeautifulSoup
html ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出head标签中的title标签中的内容
print(bs4.head.title.string)
3.6、子节点和子孙节点
3.6.1、contents
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#将p标签的子节点以列表的方式输出
print(bs4.p.contents)
3.6.2、children
frombs4importBeautifulSoup
html ="""
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#获取p标签的所有子节点,返回一个 list 生成器对象
print(bs4.p.children)
#对子节点进行遍历
fori, childinenumerate(bs4.p.children):
print(i, child)
3.6.3、descendants
frombs4importBeautifulSoup
html ="""
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#获取p标签的所有子节点(包含子孙节点),返回一个 list 生成器对象
print(bs4.p.descendants)
#对子节点进行遍历
fori, childinenumerate(bs4.p.descendants):
print(i, child)
3.7、父节点和祖先节点
3.7.1、parent
frombs4importBeautifulSoup
html ="""
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出第一个a标签的父节点
print(bs4.a.parent)
3.7.2、parents
frombs4importBeautifulSoup
html ="""
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出循环遍历出所有的祖先节点
fori, parentinenumerate(bs4.a.parents):
print(i, parent)
3.8、兄弟节点
frombs4importBeautifulSoup
html ="""
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出所有前兄弟节点
print(list(enumerate(bs4.a.next_siblings)))
#输出所有后兄弟节点
print(list(enumerate(bs4.a.previous_siblings)))
4、标准选择器
4.1、find_all (返回所有元素)
可根据标签名、属性、内容查找文档
4.1.1、name根据标签名
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出所有的ul标签(列表)
print(bs4.find_all('ul'))
#输出查找到元素的类型 <class 'bs4.element.Tag'>
print(type(bs4.find_all('ul')[0]))
for i in bs4.find_all('ul'):
# 输出每个ul中的所有li
print(i.find_all('li'))
4.1.2、attr根据属性
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出根据id属性查找到的tag元素
print(bs4.find_all(attrs={'id':'list-1'}))
#上述的简写方式
print(bs4.find_all(id='list-1'))
#输出根据name属性查找到的tag元素
print(bs4.find_all(attrs={'name':'elements'}))
#根据class查找的话,因为class是python的关键字因此需要加上_
print(bs4.find_all(class_='list-small'))
4.1.3、text根据文本
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
#通过 text 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True
print(bs4.find_all(text='Foo'))
4.2、find(查找单个)
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
#输出第一个ul标签
print(bs4.find('ul'))
# <class 'bs4.element.Tag'>
print(type(bs4.find('ul')))
#如果找不到则输出None
print(bs4.find('page'))
4.3、其他用法
find_parents() find_parent()
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings() find_next_sibling()
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。
find_previous_siblings() find_previous_sibling()
find_previous_siblings()返回前面所有兄弟节点,find_previous_sibling()返回前面第一个兄弟节点。
find_all_next() find_next()
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点
find_all_previous() 和 find_previous()
find_all_previous()返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点
5、CSS选择器
通过select()直接传入CSS选择器即可完成选择
5.1、普通选择
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
print(bs4.select('.panel .panel-heading'))
print(bs4.select('ul li'))
print(bs4.select('#list-2 .element'))
# <class 'list'>以列表方式输出
print(type(bs4.select('ul li')))
# <class 'bs4.element.Tag'>
print(type(bs4.select('ul')[0]))
5.2、获取属性
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
#查找所有ul并遍历
forulinbs4.select('ul'):
#获取ul的id属性
print(ul['id'])
#获取ul的id属性
print(ul.attrs['id'])
5.3、获取内容
frombs4importBeautifulSoup
html ="""
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
bs4 = BeautifulSoup(html,'lxml')
#查找所有li并遍历
forliinbs4.select('li'):
#输出li的文本内容
print(li.get_text())
阅读全文
0 0
- BeautifulSoup 库学习笔记
- Python爬虫库学习笔记-BeautifulSoup
- BeautifulSoup学习笔记
- BeautifulSoup学习笔记
- BeautifulSoup学习笔记
- BeautifulSoup学习笔记
- BeautifulSoup学习笔记1
- BeautifulSoup学习笔记2
- BeautifulSoup学习笔记3
- BeautifulSoup学习笔记4
- BeautifulSoup学习笔记5
- BeautifulSoup学习笔记6
- BeautifulSoup学习笔记7
- python BeautifulSoup 库 笔记
- BeautifulSoup的使用学习笔记
- Python学习笔记:BeautifulSoup模块
- BeautifulSoup官网学习笔记
- Python3爬虫学习笔记(4.BeautifulSoup库详解)
- Linux的常用指令(二)
- 多项式求逆
- spring扩展容器-ApplicationContext之BeanPostProcessor
- Coursera Using python to access Web data quiz 4
- 由CSS列表引发对CSS生成内容的思考
- BeautifulSoup 库学习笔记
- 2017年酸奶市场超速增长,未来纯奶将何去何从?
- 数据结构 中序遍历的堆栈实现法
- JSP学习总结
- Requests库学习笔记
- Agri-Net POJ
- [数学杂题 位运算] ZROI 2017 提高6 T1 异或统计
- [图解数据结构之Java实现](2) --- 线性表之链表实现
- P3851航运调度


