简单理解volatile变量的原理
来源:互联网 发布:赵 和谐 家人 知乎 编辑:程序博客网 时间:2024/06/09 03:16
volatile实现原理
Java语言规范第3版中对volatile的定义如下:java编程语言允许线程访问共享变量,为了确保共享变量能被准确的一致地更新,线程应该确保通过排他锁单独获得这个变量。vola tile并不是绝对的线程安全的,volatile只能保证该变量的可见性,也就是说该变S的值发生变化的时候,所有线程都能够立马发现这个变化。但在某些情况下比锁要方便。因为如果一个字段被声明成了volatile,java线程内存模型确保所有线程看到这个变里的值是一致的。
为了了解volatile变量是如何实现可见性的,首先要了解volatile变量进行写操作的时候cpu具体是在执行什么操作。查看volatile变量的汇编代码时,可以发现对volatile进行写操作比常规的写操作多了一行名为Lock的代码,正是这个lock保证了可见性
查阅相关的资料可以发现,这个lock指令可以锁住一个特定的内存地址,锁定之后可以防止别的系统总线读取和修改这块内存地址加上了 lock指令的写操作在多核处理器下会引发两件事情:
1) 将当前处理器缓存行的数据安全的写回到系统内存
2) 这个写回内存的操作同时会使在其他cpu里缓存了该内存地址的数据无效
上述第一条不难理解,如何保证缓存中的数据安全的写回内存中呢,通常来讲有两种方法
1)通过总线加Lock#锁的方式
2)通过缓存一致性协议
第一种最安全,不过Lock#会锁住总线,导致只有一个cpu可以访问缓存,效率低下。
第二种缓存一致性协议是为了保证各个cpu之间的缓存是一致的,核心思想是当一个cpu在修改变量的时候发现该变量是共享变量,就通知其他CPU其缓存已经失效,其他CPU在修改变量的时候就知道应该从主存中重新读取
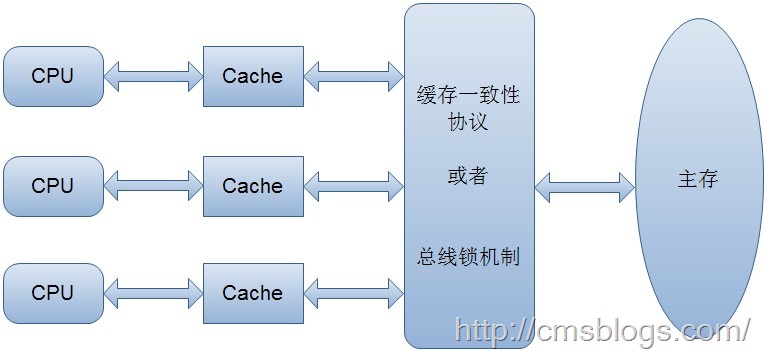
以前的处理器普遍采用的锁总线的方式,但是由于开销较大,现在的处理器已经放弃这种方式而采用缓存一致性协议来保证读写安全
第二条的实现,我们知道处理器为了提高处理速度都不会直接和内存逬行通信,而是先将系统内存数据读到内部的缓存后在对缓存进行操作,但是操作完毕后并不是一定就会马上写回内存。声明了volatile的变量进行写操作的时候,JVM就会向处理器发送一条lock前缀的指令,立马将这个变呈所在缓存行的数据写回到系统内存。
除了写回内存以外,还得保证各个处理器的缓存是一致的,不能有处理器缓存了旧的值,为了实现这个一致性,处理器通过缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设罝成无效状态,当处理器对这个数据进行修改操作的时候,就会重新从系统内存中把数据读到处理器缓存里。
这里捎带提一下缓存行,cpu读取数据都是按缓存行为单位读取的,32位cpu—个缓存行为32位,也就是说,即使你只需要读一个数据,也会将其相邻的32位数据一并读入cpu, 这样是为了提高读取效率,避免频繁的读取数据。
但这个机制也会导致一些困扰,比如在对队列进行入队出队操作的时候,如果队头节点和队尾节点都不足64位的话,处理器就会把他们同时读入一个缓存行,这样,你在高并发场景下进行入队操作的时候,会将整个缓存行锁定,在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的头节点,这样就不能进行出队操作了,这就严重的影响了并发场景下的入队出队效率。
Douglea在使用volatile变量时,就针对这个情况对队列元素进行了优化,也就是并发包中的LinkedTransferQueue,它把队头和队尾元素都用15个变量填充起来,确保队头或是 队尾都能独占一个缓存行,这就提高了并发的效率。
- 简单理解volatile变量的原理
- volatile: 变量的理解
- volatile变量的理解
- 关于volatile变量的理解
- 浅谈volatile变量的理解
- 浅谈volatile变量的理解
- 对Volatile变量的理解和总结
- 多线程并发中volatile变量的原理
- 深入理解volatile变量
- 深入理解 C++ Volatile变量
- 深入理解Java虚拟机笔记---volatile变量的特殊规则
- mDNS 原理的简单理解
- mDNS原理的简单理解
- mDNS原理的简单理解
- jspatch 的简单原理理解
- Socket原理的简单理解
- mDNS原理的简单理解
- #Git原理的简单理解
- 关于C语言打印字母塔的问题
- poj 1321 棋盘问题
- 关于使用元素 background-image 时遇到图片显示无效的原因及解决办法
- centos 7 密码忘记 如何进入修改
- 自定义view画圆
- 简单理解volatile变量的原理
- 正则表达式练习题
- Linux——权限
- Java SE——数据类型
- Oracle 11g中预定义异常
- Hive静态分区和动态分区
- SPOJ
- html53D动画
- SourceTree<三>解决冲突


