今日头条街拍爬取
来源:互联网 发布:微博的基本数据分析 编辑:程序博客网 时间:2024/05/08 17:40
本次练习使用到的知识点有
* Requests 库的使用
* BeautifulShop 库的使用
* 正则表达式的使用
* pymongo 库的使用
1、项目流程分析
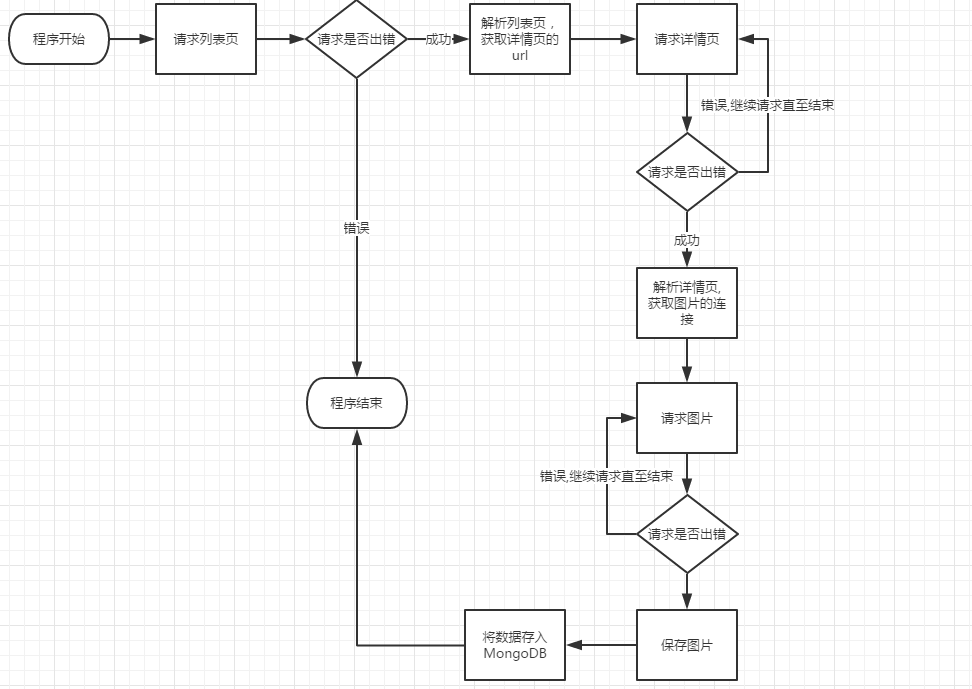
2、中心调度
#中心调度
defmain(offset):
#获取列表页
index_data = get_page_index(offset,KEYWORDS)
ifindex_dataisNone:
print("offset:"+offset+"异常")
return
#解析列表页获取所有详情页的url
forurlinparse_page_index(index_data):
#获取详情页
detail_data = get_page_detail(url)
ifdetail_dataisNone:
print('url:%s异常'.format(url))
pass
#解析详情页
data = parse_page_detail(detail_data, url)
ifdataisNone:
continue
save_to_mongo(data)
3、请求和解析列表页
#请求获取列表页的响应数据
defget_page_index(offset,keywords):
params = {
'offset':offset,
'format':'json',
'keyword':KEYWORDS,
'cur_tab':3,
'autoload':'true',
'count':20
}
try:
response = requests.get('http://www.toutiao.com/search_content/',params=params)
ifresponse.status_code==200:
returnresponse.text
returnNone
exceptRequestExceptionase:
returnNone
#解析列表页
defparse_page_index(text):
try:
data = json.loads(text)
ifdataand'data'indata.keys():
foritemindata.get('data'):
yielditem.get('article_url')
exceptJSONDecodeErrorase:
print('解析异常')
return[]
4、请求和解析详情页
#解析详情页面
defparse_page_detail(html, url):
soup = BeautifulSoup(html,'lxml')
#获取页面的标题
title = soup.title.string
image_pattern = re.compile('var gallery = (.*?);',re.S)
result = image_pattern.search(html)
ifresult:
try:
data = json.loads(result.group(1))
ifdataand'sub_images'indata.keys():
#获取所有的image的url
images = [item.get('url')foritemindata.get('sub_images')]
forimageinimages:
#下载图片
download_image(image)
return{'title':title,'url':url,'images':images}
exceptJSONDecodeErrorase:
returnNone
returnNone
5、下载图片和保存至Mongodb
#获取图片的二进制流
defdownload_image(url):
try:
print('图片'+url+'正在下载')
response = requests.get(url)
ifresponse.status_code ==200:
#保存图片
save_image(response.content)
exceptRequestExceptionase:
print('异常image:'+url)
pass
#保存二进制流至文件
defsave_image(content):
file_path ='{0}/images/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
ifnotos.path.exists(file_path):
withopen(file_path,'wb+')asfile:
file.write(content)
file.close()
defsave_to_mongo(data):
ifdb[MONGO_TABLE].insert(data):
print('成功保存'+data['title'])
returnTrue
returnFalse
6、完整代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
importos
importre
importrequests
importpymongo
importjson
fromhashlibimportmd5
frombs4importBeautifulSoup
fromsettingimport*
fromrequests.exceptionsimportRequestException
fromjson.decoderimportJSONDecodeError
frommultiprocessingimportPool
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
#请求获取列表页的响应数据
defget_page_index(offset,keywords):
params = {
'offset':offset,
'format':'json',
'keyword':KEYWORDS,
'cur_tab':3,
'autoload':'true',
'count':20
}
try:
response = requests.get('http://www.toutiao.com/search_content/',params=params)
ifresponse.status_code==200:
returnresponse.text
returnNone
exceptRequestExceptionase:
returnNone
#解析列表页
defparse_page_index(text):
try:
data = json.loads(text)
ifdataand'data'indata.keys():
foritemindata.get('data'):
yielditem.get('article_url')
exceptJSONDecodeErrorase:
print('解析异常')
return[]
#请求获取详情页面的响应数据
defget_page_detail(url):
response = requests.get(url)
try:
ifresponse.status_code==200:
returnresponse.text
returnNone
exceptRequestExceptionase:
returnNone
#解析详情页面
defparse_page_detail(html, url):
soup = BeautifulSoup(html,'lxml')
#获取页面的标题
title = soup.title.string
image_pattern = re.compile('var gallery = (.*?);',re.S)
result = image_pattern.search(html)
ifresult:
try:
data = json.loads(result.group(1))
ifdataand'sub_images'indata.keys():
#获取所有的image的url
images = [item.get('url')foritemindata.get('sub_images')]
forimageinimages:
#下载图片
download_image(image)
return{'title':title,'url':url,'images':images}
exceptJSONDecodeErrorase:
returnNone
returnNone
#获取图片的二进制流
defdownload_image(url):
try:
print('图片'+url+'正在下载')
response = requests.get(url)
ifresponse.status_code ==200:
#保存图片
save_image(response.content)
exceptRequestExceptionase:
print('异常image:'+url)
pass
#保存二进制流至文件
defsave_image(content):
file_path ='{0}/images/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
ifnotos.path.exists(file_path):
withopen(file_path,'wb+')asfile:
file.write(content)
file.close()
defsave_to_mongo(data):
ifdb[MONGO_TABLE].insert(data):
print('成功保存'+data['title'])
returnTrue
returnFalse
#中心调度
defmain(offset):
#获取列表页
index_data = get_page_index(offset,KEYWORDS)
ifindex_dataisNone:
print("offset:"+offset+"异常")
return
#解析列表页获取所有详情页的url
forurlinparse_page_index(index_data):
#获取详情页
detail_data = get_page_detail(url)
ifdetail_dataisNone:
print('url:%s异常'.format(url))
pass
#解析详情页
data = parse_page_detail(detail_data, url)
ifdataisNone:
continue
save_to_mongo(data)
if__name__=='__main__':
groups = [x*20forxinrange(GROUP_START,GROUP_END+1)]
pool = Pool()
pool.map(main, groups)
7、运行结果
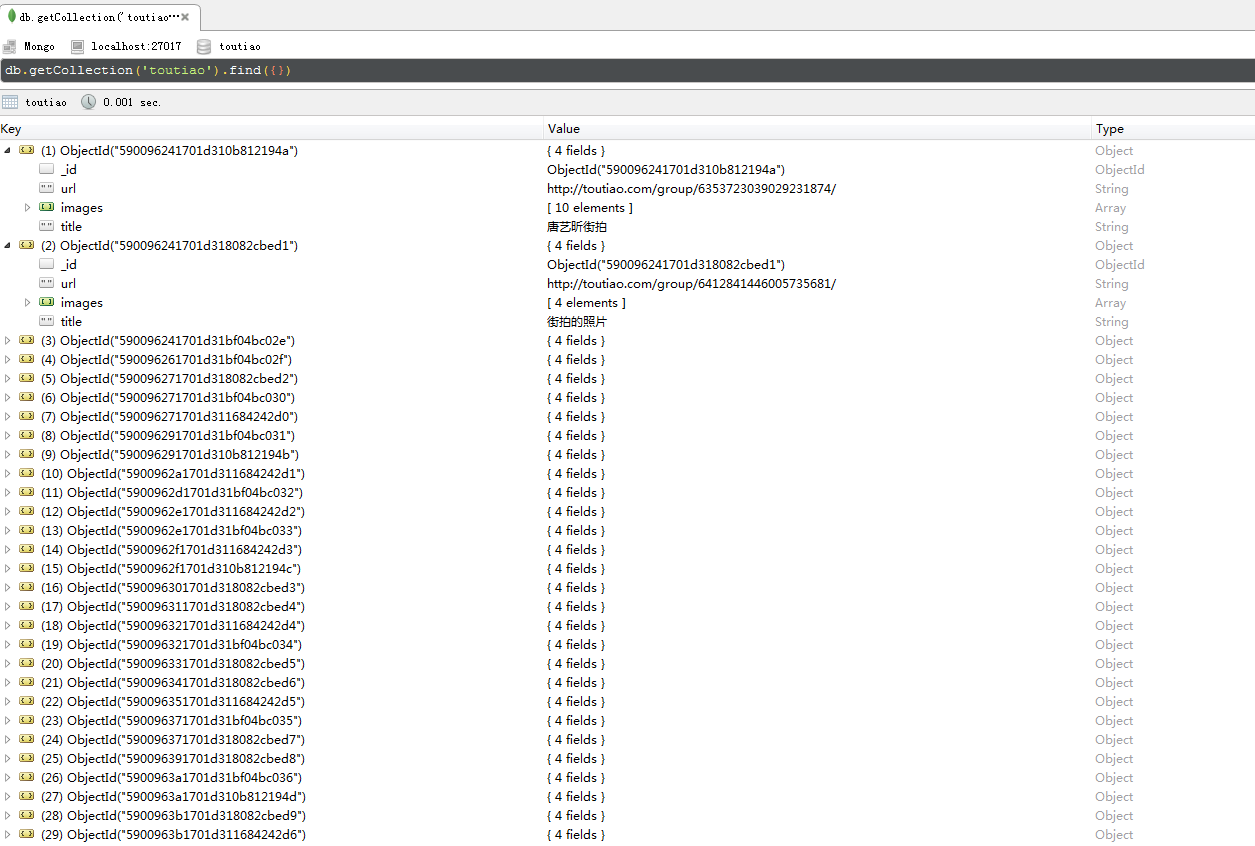
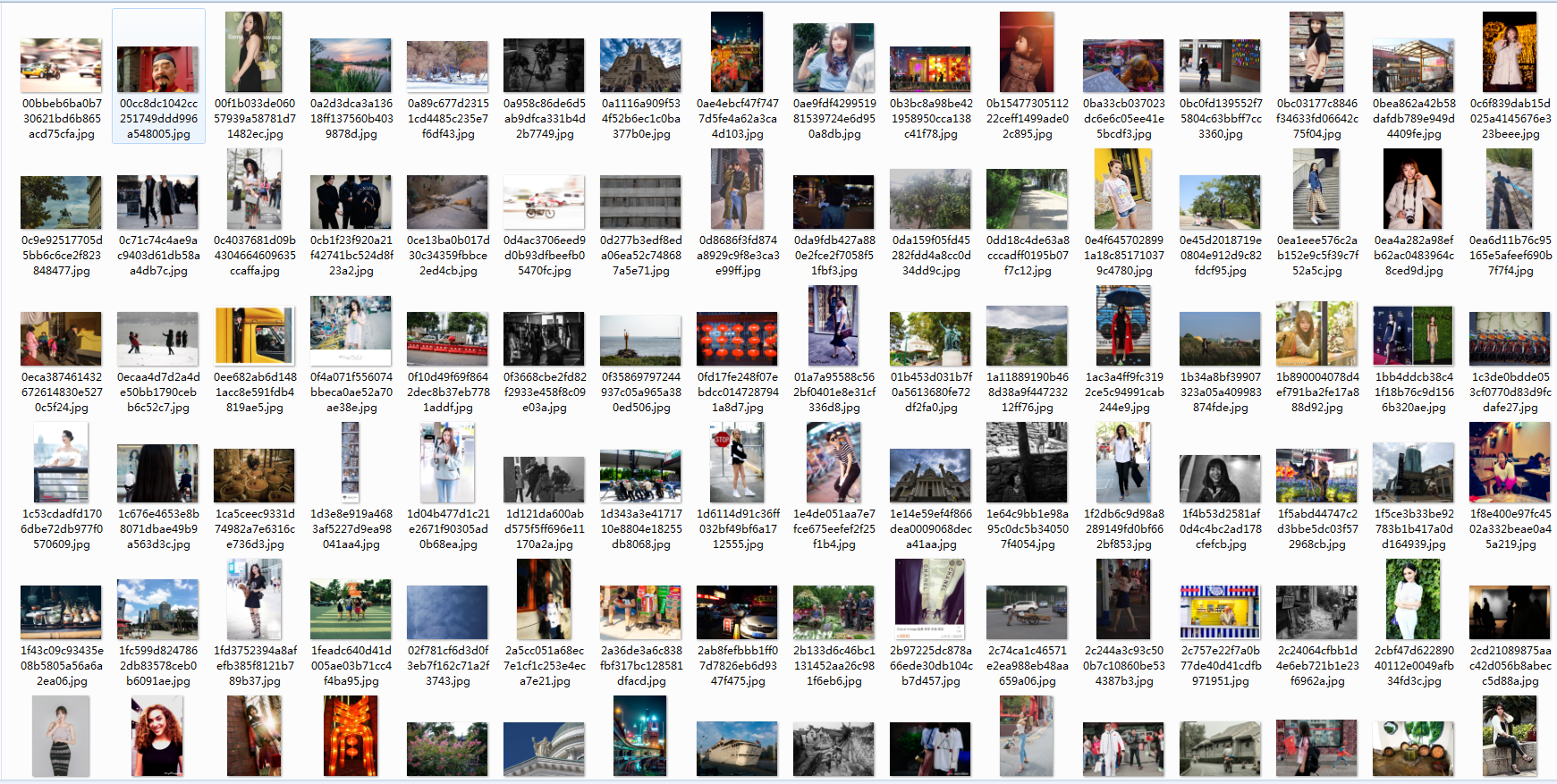
阅读全文
0 0
- 今日头条街拍爬取
- 今日
- 今日
- 今日
- 今日
- 今日
- 今日
- 今日
- 今日事,今日毕
- 今日事今日毕
- 今日事今日毕
- 今日事今日评
- 今日程序今日写
- 今日程序今日写
- 今日事,今日毕
- 今日事今日毕
- 今日事今日毕
- 今日计划
- Hibernate框架
- CSS 分隔线 中间带文字 分隔符
- 访谈:腾讯高级交互设计师C7210的十年设计路(下)
- 构造函数中是否可以调用虚函数
- 机器视觉之HALCON入门之路2-阈值分割与坐标读取
- 今日头条街拍爬取
- 蓝牙的设置
- 《OpenGL超级宝典》中第七章TextureRect示例程序,RenderScene()函数解析
- php绘制双柱形图
- 【项目实践】——java异常A child container failed during start
- explicit
- Selenium 爬取淘宝数据
- The C Programming Language 练习题2-9
- servlet详解


