Decision Tree
来源:互联网 发布:java unix时间戳 时区 编辑:程序博客网 时间:2024/05/18 01:29
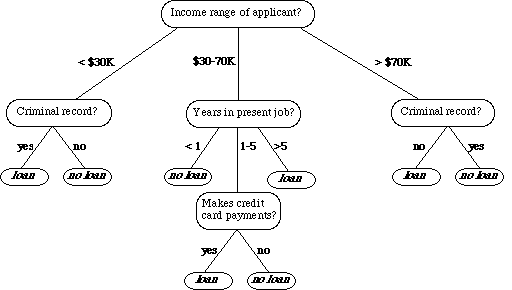
Decision tree learning uses a decision tree (as a predictive model) to go from observations about an item (represented in the branches) to conclusions about the item's target value (represented in the leaves).
information gain
Firstly, we need to talk about what is entropy and conditional entropy.
we assume that probability distribution of X is:
hence we have entropy (A measure of the amount of information, higher means more important):
conditional entropy :
information gain:
information gain ratio
information gain is based on your training set, it doesn't have absolute meaning, we prefer to use information gain ratio to correct it.
Three main algorithms:
ID3
ID3 (Examples, Target_Attribute, Attributes) Create a root node for the tree If all examples are positive, Return the single-node tree Root, with label = +. If all examples are negative, Return the single-node tree Root, with label = -. If number of predicting attributes is empty, then Return the single node tree Root, with label = most common value of the target attribute in the examples. Otherwise Begin A ← The Attribute that best classifies examples(highest information gain). Decision Tree attribute for Root = A. For each possible value, vi, of A, Add a new tree branch below Root, corresponding to the test A = vi. Let Examples(vi) be the subset of examples that have the value vi for A If Examples(vi) is empty Then below this new branch add a leaf node with label = most common target value in the examples Else below this new branch add the subtree ID3 (Examples(vi), Target_Attribute, Attributes – {A}) End Return Root
C4.5
Same process as ID3 execpt C4.5 use highest information gain ratio as the measure to choose the attribute that best classifies examples
CART
Classification and regression trees (CART) are a non-parametric decision tree learning technique that produces either classification or regression trees, depending on whether the dependent variable is categorical or numeric, respectively.
Decision trees are formed by a collection of rules based on variables in the modeling data set:
- Rules based on variables' values are selected to get the best split to differentiate observations based on the dependent variable
- Once a rule(gini impurity usually) is selected and splits a node into two, the same process is applied to each "child" node (i.e. it is a recursive procedure)
- Splitting stops when CART detects no further gain can be made, or some pre-set stopping rules are met. (Alternatively, the data are split as much as possible and then the tree is later pruned.)
Pruning is a technique in machine learning that reduces the size of decision trees by removing sections of the tree that provide little power to classify instances. Pruning reduces the complexity of the final classifier, and hence improves predictive accuracy by the reduction of overfitting.
- decision tree
- decision tree
- decision tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree
- Decision Tree Basic
- data mining decision tree
- Decision Tree 及实现
- Decision Tree forOptimization Software
- Python第三方库安装笔记
- 【Leetcode】【python】Length of Last Word
- QQ邮箱SMTP发送源码及jar包
- JDATA 腾讯广告赛
- ThinkPHP5.0集成七牛云--对象存储服务
- Decision Tree
- 洛谷日记8
- 开发者山行图,找到你的收入和位置
- 创建自己的搜索引擎,利用google进行站内搜索
- Android Studio上进行NDK编程之Hello world
- static 深入理解
- Tensorflow--Day 1
- Reverse Second Half of a Linked List
- String与StringBuffer的区别


