文章标题
来源:互联网 发布:如何计算算法复杂度 编辑:程序博客网 时间:2024/06/09 14:21
1.代价敏感错误率与代价函数
“代价敏感”错误率为
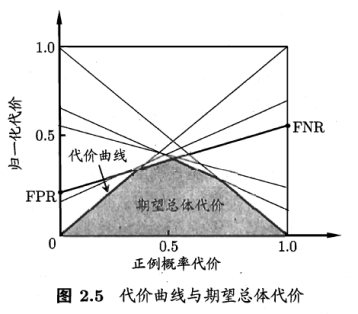
在非均衡代价下,ROC曲线不能满足学习器的期望总体代价,而“代价曲线”则可达到该目的。横轴为正例概率代价:
纵轴为归一化代价:
FNR为假阴性率,FPR为假阳性率。
2.比较检验
2.1 假设检验
假设检验中的“假设”是对于学习器泛化错误率分布的某种判断或者猜想。现实中我们并不知道泛化错误率,只能获知其测试错误率
对于泛化错误率为

我们根据图表粗略估计ε0,比如这幅图当中ε0可取5,6,7都可以,然后求出总体概率α,我们把大多数样本分布的区间1-α称为置信区间,所以只要不超过ε0,即在置信度下就是符合条件的假设 ,否则被抛弃,即在α显著度下。

包含m个样本的测试集上,泛化错误率为的学习器被测得测试错误率为的概率:
很多时候我们并非仅做一次留出估计,而是通过多次留出法或是交叉验证法,得到k个测试错误率
平均错误率
考虑到这k个测试错误率可看成泛化错误率
服从自由度为k-1的t分布。
对假设“

2.2交叉验证t检验
对于学习器A、B,若我们使用k折交叉验证法得到各种的k组测试错误率。若两个学习器的性能相同,则他们使用相同的训练/测试集得到的测试错误率应相同,即
对每对结果求查
2.3 McNemar 检验
对于二分类问题学习器A和B: 
如果假设两学习器性能相同,则应该有
服从自由度为1的
2.4 Friedman检验与 Nemenyi后续检验
- Friedman检验
多个数据集每个数据集对多个算法A、B、C、D的性能排序,求得服从自由度为k-1的χ2 分布的变量:
τF=(N−1)τχ2N(k−1)−τχ2
检测是否所有算法的性能相同
2.Nemenyi后续检验
若算法的性能是不一样的,则需要进行后续检验来进一步区分各算法。常见的为Nemenyi后续检验。
Nemenyi检验计算平均序列值差别的临界值域:CD=qαk(k+1)6N−−−−−−−√
2.5 偏差和方差
“偏差和方差分解”是分析学习器泛化能力的一种重要工具。
学习器的期望预测为:
不同训练集产生的方差为
偏差为
于是泛化误差为
偏差、方差、噪声的含义为:偏差表示学习器的期望预测与实际之间的偏离程度,表征学习器对数据的拟合能力;方差表示同样大小的训练集的变动导致学习性能的变化,即刻画了数据扰动所造成的影响;噪声表示当前任务下所能达到的期望泛化误差的下限。
偏差和方差是存在冲突的,在训练程度不足时,拟合程度不够,训练数据的扰动不大,偏差主导泛化错误率,称为欠拟合;训练加深后,拟合程度充足,但训练集的轻微扰动都会造成结果的显著波动,方差主导泛化错误率,称为过拟合。

阅读全文
0 0
- 文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题 文章标题 文章标题 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 文章标题
- 大话Vim!!!
- Gym-100851F Froggy Ford 最短路变形 dijkstra || spfa
- 高精度加法和高精度乘法
- 顺序表实现
- sgu-194-Reactor Cooling(无源汇有上下界最大流)
- 文章标题
- pandas描述性统计 (1)
- BP算法
- Android 冷启动(所谓白屏)优化方案
- 空瓶子换汽水的问题
- bzoj 3362: [Usaco2004 Feb]Navigation Nightmare 导航噩梦 带权并查集
- Servlet
- 扇形攻击(判定)
- 01-复杂度2 Maximum Subsequence Sum


