面试问答
来源:互联网 发布:网络作家如何挣钱 编辑:程序博客网 时间:2024/05/22 03:32
1、进程跟线程之间的区别,线程有独立的资源吗?
答:进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,线程只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
2、介绍下左连接,右连接,内连接,外链接。
答:左连接是显示左边表的全部内容,根据左表primary key找右表,能找到的就显示,不能找到的返回null。右连接正好相反。内连接通过两个表的primary key连接,只返回左右表都存在的行。外链接,相当于左右表进行笛卡尔积,返回所有行。
附加:
1、SQL查询的基本原理:两种情况介绍。
第一、单表查询:根据WHERE条件过滤表中的记录,形成中间表(这个中间表对用户是不可见的);然后根据SELECT的选择列选择相应的列进行返回最终结果。
第二、两表连接查询:对两表求积(笛卡尔积)并用ON条件和连接连接类型进行过滤形成中间表;然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
第三、多表连接查询:先对第一个和第二个表按照两表连接做查询,然后用查询结果和第三个表做连接查询,以此类推,直到所有的表都连接上为止,最终形成一个中间的结果表,然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
理解SQL查询的过程是进行SQL优化的理论依据。
2、ON后面的条件(ON条件)和WHERE条件的区别:
ON条件:是过滤两个链接表笛卡尔积形成中间表的约束条件。
WHERE条件:在有ON条件的SELECT语句中是过滤中间表的约束条件。在没有ON的单表查询中,是限制物理表或者中间查询结果返回记录的约束。在两表或多表连接中是限制连接形成最终中间表的返回结果的约束。
从这里可以看出,将WHERE条件移入ON后面是不恰当的。推荐的做法是:
ON只进行连接操作,WHERE只过滤中间表的记录。
例子:
-------------------------------------------------
a表 id name b表 id job parent_id
1 张3 1 23 1
2 李四 2 34 2
3 王武 3 34 4
a.id同parent_id 存在关系
--------------------------------------------------
1) 内连接
select a.*,b.* from a inner join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
2)左连接
select a.*,b.* from a left join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
3 王武 null
3) 右连接
select a.*,b.* from a right join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
4) 完全连接
select a.*,b.* from a full join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
3 王武 null
3、在Linux系统中,如何查看内存大小?
答:使用命令:free -m ,查看CPU 信息:lscpu或者是cat /proc/cpuinfo
附加:其他常用Linux命令,只要输入#以后命令。
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态用户
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务服务
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务程序
# rpm -qa # 查看所有安装的软件包
3、apriori算法和聚类之间的区别?
答:apriori算法找出来的是频繁模式,指的是两个或者多个事务之间的关联关系,比如强关联规则。
聚类算法找出来的是具有相同属性的事物归为一个类,这个类里的所有事物都具有同一个或者多个相同或相似的属性。
ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
2.在ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
3.LinkedList不支持高效的随机元素访问。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
5、常用的排序算法有哪些?哪些是稳定的?
快速排序,希尔排序,选择排序,堆排序,冒泡排序
稳定的有:冒泡排序,插入排序
不稳定的有:希快选堆
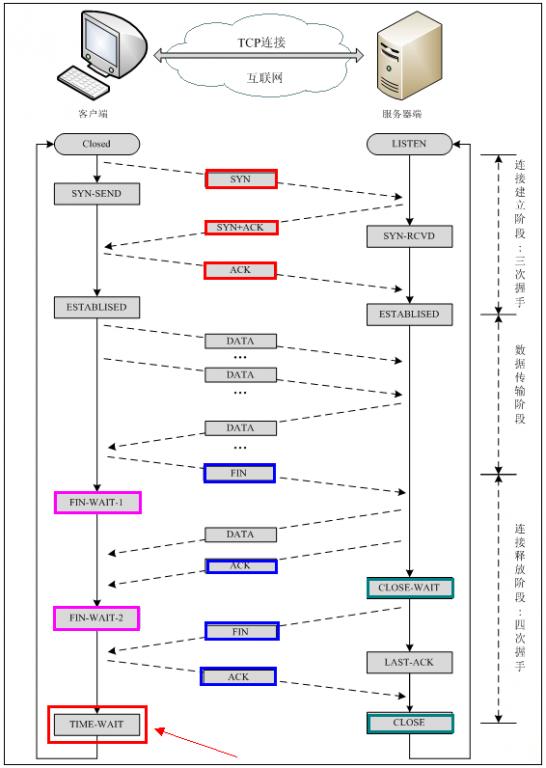
【注意】中断连接端可以是Client端,也可以是Server端。
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"告诉Client端,好了,我这边数据发完了,准备好关闭连接了"。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,"就知道可以断开连接了"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 面试问答
- 面试问答
- 面试问答
- [面试]英文面试问答
- 英语面试问答大全
- 面试问答详解(一)
- 面试问答详解(二)
- 招考城管面试问答
- 面试英语经典问答
- 英语面试问答大全
- 英语面试问答
- 面试英语经典问答
- 面试英语经典问答
- Linux面试一句话问答
- Java程序员面试问答
- 面试问答精髓
- 面试问答精髓
- 笔试面试常见问题问答
- easyui日期自定义到分钟
- 如何制作基于AimOffset的动画
- D2数据类型
- c#中异常处理
- sketch常用快捷键键盘对应
- 面试问答
- 第三周 顺序表的基本运算
- 字节流转换为字符流
- 最大/小子数组
- 第五周项目3-括号的匹配
- 发送JSON数据到服务器
- 调度
- lecture6,Training Neural Networks, Part I
- 剑指offer 33 把数组排成最小的数


