Tesseract:安装与命令行使用
来源:互联网 发布:软件的可维护性 编辑:程序博客网 时间:2024/05/17 16:46
目录
- 简介
- 获取,安装与配置
- Linux
- Windows
- 命令行使用
Tesseract 是一款被广泛使用的开源 OCR 工具,本文将对其进行简单的介绍.
简介

Tesseract(/'tesərækt/) 这个词的意思是"超立方体",指的是几何学里的四维标准方体,又称"正八胞体"。右图是一个正八胞体绕着两个四维空间中互相正交的平面进行双旋转时的透视投影。不过这里要讲的,是一款以其命名的开源 OCR(Optical Character Recognition, 光学字符识别) 软件。
所谓 OCR 是图像识别领域中的一个子领域,该领域专注于对图片中的文字信息进行识别并转换成能被常规文本编辑器编辑的文本。
Tesseract 已经有 30 年历史,开始它是惠普实验室的一款专利软件,然后在 2005 年开源,自 2006 年后由 Google 赞助进行后续的开发和维护。
在 1995 年 Tesseract 曾是世界前三的 OCR 引擎,而且在现在的免费 OCR 引擎中,其识别精度也仍然是出类拔萃的。因为其免费与较好的效果,许多的个人开发者以及一些较小的团队在使用着 Tesseract ,诸如验证码识别、车牌号识别等应用中,不难见到 Tesseract 的身影。
获取,安装与配置
Linux
主流的 Linux 发行版都可以通过包管理器来安装 Tesseract,以 Debian 及其衍生版为例:
sudo apt-get install tesseract-ocr
如果想用 Tesseract 对图像进行识别,还需要对应的语言文件。所谓的语言文件是 Tesseract 识别某种语言的文字图像时需要的一些资源,这些东西也可以通过包管理器获取。比如我们需要识别英语和简体中文,那么:
sudo apt-get install tesseract-ocr-eng tesseract-ocr-chi-sim
当然了,这是通过包管理器的方式进行安装,如果需要,还可以通过编译安装的方式来构建最新版的 Tesseract.
Tesseract 的项目托管在 Google Code 上,在下载页面可以自己选择需要的版本,假如我们需要安装 tesseract-ocr-3.02.02.tar.gz 这个版本:
wget https://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.02.tar.gztar xzvf tesseract-ocr-3.02.02.tar.gz
Tesseract 的编译需要 automake, autoconf, libtool 支持,所以这几个工具得装上:
sudo apt-get install autoconf automake libtool
当然了, Tesseract 还依赖一些图像库:
sudo apt-get install ligjpeg62-dev libtiff4-dev libpng12-dev libleptonica-dev
注意: 以上安装的包的名称可能在不同发行版上略有不同
需要注意的是,Leptonica 是 Tesseract 的一个比较重要的依赖,而且不同版本的 Tesseract 对 Leptonica 的版本要求也不一样,需要留意包管理器所安装的 Leptonica 版本是否满足要求,如果不满足要求,最好还是下载 Leptonica 的源代码编译安装。
- Tesseract 3.01: Leptonica 版本不低于 1.67
- Tesseract 3.02: Leptonica 版本不低于 1.69
- Tesseract 3.03: Leptonica 版本不低于 1.70
解决依赖后按常规方法编译安装即可:
./configuremakesudo make installsudo ldconfig
在 3.03 及以上版本中,用于训练产生语言文件的工具需要单独编译和安装:
make trainingsudo make training-install
建议在执行 ./configure 时加上参数 –prefix=xxx 来指定安装路径,这样以后要卸载会方便一些——当然如果这样做的话在安装完后需要做一些额外的工作,包括:
- 添加 Tesseract 的可执行程序路径到环境变量 PATH 中
- 在 /usr/include 目录或者 /usr/local/include 目录下建立 Tesseract 安装目录下 include/tesseract 的符号链接
- 在 /usr/lib 目录或者 /usr/local/lib 目录下建立 Tesseract 安装目录下的 lib 目录下的静态链接库、动态链接库的符号链接
安装完成后,无论是通过包管理器安装的还是通过编译源代码安装的,建立都配置一下 TESSDATA_PREFIX 这个环境变量。在这个环境变量未设置的情况下,Tesseract 将会在安装目录中的 share/tessdata 这个目录下去寻找、加载语言文件,这本身当然没什么问题。
问题在于当我们想添加新的语言文件时,会遇到一些麻烦——程序一般都是安装的系统目录中,也就是说,我们需要提升权限才能将语言文件放到正确的地方。假如是在公司的服务器上进行相关的操作,普通用户一般都是没有 sudo 权限的。将语言文件放置在用户目录中可以解决这个问题,方法是在 .bashrc (假设您使用 bash 作为日常的 shell)中设置
export TESSDATA_PREFIX=$HOME/
如上设置时,将语言文件放在 ~/tessdata/ 下面即可。
Windows
Windows 上的安装也很简单,下载对应的安装程序,双击运行,按照提示进行即可。
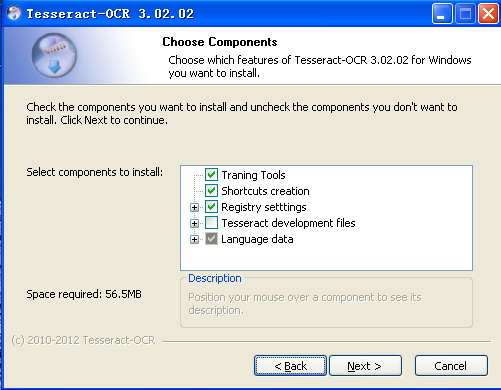
注意在 "Language data" 那个选项里,默认是只勾选了英文的,如果需要进行其他语言的识别,记得勾选对应的语言。
再一个是,如果需要进行相应的开发工作,建立把 "Tesseract development files" 这个选项也勾选。
安装完成后如无异常,会将安装目录添加到环境变量 PATH 中,这样就可以在 cmd 中直接运行程序了——Tesseract 并没有提供图形界面的工具,只能在命令行中使用,当然了,我们可以自己编写 GUI 应用程序来调用它,这个准备后面再讲。
命令行使用
这里只简单讲一下 Tesseract 识别图像的基本用法,关于训练和开发将另开新篇来专门讲述。
由于 Tesseract 只提供命令行工具,这里讲到的用法对 Linux 和 Windows 平台都适用。
首先可以通过 "–list-langs" 来查看有哪些可用的 "语言" ,如果之前的 TESSDATA_PREFIX 环境变量没有设置错,将会看到这样的输出:
bash > tesseract --list-langsList of available languages (17):mathchichi_simeng
这里的 "eng" 和 "chi_sim" 是 Tesseract 提供的英文和简体中文的语言文件,而其他的几个则是我自己训练得到的。
另外要说明的是,这里的 "语言文件" 的本质是包含了某种 "自然语言" 的文字的特征等辅助识别的一些资源,但像 chi_sim 这个中文简体里也包含了英文字母与阿拉伯数字的资源。而我们也可以为了特定的用途而去训练产生对应的资源,这里的 "math" 是用于识别简单数学表达式的一个资源,并不是说有一种叫做 "math" 的语言。
如果发现以上命令的输出为空,那应该去检查一下 TESSDATA_PREFIX 这个环境变量。在这个环境变量无误且 "语言文件" 存在的情况下,假设我们有一张名为 paper.png 的图片,则通过以下命令对图片进行识别,
tesseract paper.png paper -l chi_sim
- 第一个参数是待识别的图像的文件名
- 第二个参数用于指定输出,如果希望直接输出而不是保存到文件,那么就使用 stdout,否则这个参数将会作为保存结果的文件的前缀
- -l chi_sim 这个应该很好理解,就是用来指定使用哪个 "语言文件",如果是使用 英文(eng) ,这个参数可以不加,因为默认就是使用英文的 "语言文件" 来进行识别
以上命令如不出错,结果将会保存到 paper.txt 这个文本文件中。
此外 Tesseract 还提供非常丰富的可选参数来对识别过程进行调整,可用的参数及其默认值可以通过以下命令进行查看:
tesseract --print-parameters
参数的使用有两种:
使用 -c 选项来设定单项参数的值,比如:
tesseract paper.png paper -l chi_sim -c language_model_ngram_on=1允许使用多个 -c 选项来设置多个参数的值。
将多项参数设置写入文件,然后在识别时使用该文件,比如:
tesseract paper.png paper -l chi_sim tess.conf
需要注意的是,如果使用配置文件,用作参数的配置文件名要放在最后面——这里也支持多个配置文件,但它们必须要在最后面。假如我有两个配置文件 tess_1.conf 和 tess_2.conf,那么这样是正确的:
tesseract paper.png paper -l chi_sim tess_1.conf tess_2.conf
而这样则是错误的:
tesseract paper.png paper tess_1.conf -l chi_sim tess_2.conf
至于 Tesseract 那些参数各有什么含义,官方没有提供任何文档来进行解释,这里有一个链接提供了部分参数的用处说明,应该是阅读了 Tesseract 源代码后得到的结论。
其他源代码安装参考资料
http://blog.csdn.net/yimingsilence/article/details/51276138
注意:下面的下载网址和版本有更新的以最新的为准
1. 在ubuntu下可以自动安装
- sudo apt-get install tesseract-ocr
2.编译安装
a.编译环境: gcc gcc-c++ make(这个环境一般机器都具备,可以忽略)
- yum install gcc gcc-c++ make
b.安装tesseract-ocr编译必须的包
- yum/apt-get install autoconf automake libtool
- yum install libjpeg-devel libpng-devel libtiff-devel zlib-devel
ubuntu
- sudo apt-get install libpng12-dev
- sudo apt-get install libjpeg62-dev
- sudo apt-get install libtiff4-dev
d.下载 leptonica 包: http://www.leptonica.org/source/leptonica-1.71.tar.gz
- wget http://www.leptonica.org/source/leptonica-1.71.tar.gz
- tar -zxvf ...
- ./configure
- make
- make install
需要注意,leptonica的版本问题
3.01 requires at least v1.67 of Leptonica.
3.02 requires at least v1.69 of Leptonica. (Both available in Ubuntu 12.04 Precise Pangolin.)
3.03 requires at least v1.70 of Leptonica. (Both available in Ubuntu 14.04 Trusty Tahr.)
如果版本不一致,会出现问题如下:
- Tesseract Open Source OCR Engine v3.02.02 with Leptonica
- Error in findTiffCompression: function not present
- Error in pixReadStreamTiff: function not present
- Error in pixReadStream: tiff: no pix returned
- Error in pixRead: pix not read
- Unsupported image type.
e.下载 tesseract-3.02 安装包: http://tesseract-ocr.googlecode.com/files/tesseract-3.02.02.tar.gz
- wget http://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.02.tar.gz
- ./autogen.sh
- ./configure
- make
- make install
- ldconfig
f.下载 tesseract-3.02 英文语言包: http://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.eng.tar.gz,解压后将 tesseract-ocr/tessdata 下的所有文件全部拷贝到 /usr/local/share/tessdata 下。
测试
- tesseract phototest.tif phototest -l eng


- Tesseract:安装与命令行使用
- Tesseract:安装与命令行使用
- Tesseract安装使用
- tesseract安装使用
- Tesseract-OCR 3.02命令行程序的使用
- Tesseract-OCR 3.02命令行程序的使用
- Tesseract-OCR入门使用(1)-安装包获取和命令行调用
- tesseract-ocr ubuntu 安装使用
- tesseract-ocr ubuntu 安装使用
- [TesserAct学习笔记1]TesserAct的安装、训练、使用
- python-tesseract下载安装及使用
- tesseract-ocr 4.0 安装及使用
- Tesseract-OCR 3.0+ 安装和使用
- Tesseract安装
- tesseract 安装
- Tesseract-OCR的训练与使用
- Tesseract-OCR的简单使用与训练
- Tesseract-OCR的简单使用与训练
- Http请求中Content-Type,以及在Spring MVC中的应用
- PHP(数组排序) 判断系统时间与输入时间的差异
- Servlet jsp跳转到Servlet 出现404错误的路径设置方法
- 文章标题
- 异常处理
- Tesseract:安装与命令行使用
- 一加5简单体验Google ARCore
- nginx配置总结
- Java AOP 动态代理 配置表达式
- postman使用教程
- unity对象池
- Ubuntu12.04 搭建smb共享目录(包含权限管理)
- mysql 时间段查询,无数据时补0
- 不能使用箭头函数的场景


