部署AlwaysOn第三步:集群资源组的健康检测和故障转移
来源:互联网 发布:用友软件体系 编辑:程序博客网 时间:2024/06/06 03:35
资源组是由一个或多个资源组成的组,WSFC的故障转移是以资源组为单位的,资源组中的资源是相互依赖的。一个资源所依赖的其他资源必须和该资源处于同一个资源组,跨资源组的依赖关系是不存在的。在任何时刻,每个资源组都仅属于集群中的一个结点,该结点就是资源组的活跃结点(Active Node),由活跃结点为应用程序提供服务。AlwaysOn建立在WSFC的健康检测和故障转移的特性之上,和故障转移集群有了不可分割的关系,因此,从底层的集群资源来理解可用性组,知其然知,其所以然,有助于更好地维护AlwaysOn。
一,AlwaysOn的可用性组是集群的资源组
AlwaysOn的可用性组(Availability Group)是集群的资源组,其资源类型是“SQL Server Availability Group”,由于,WSFC的故障转移是以资源组为单位的,因此,AlwaysOn的每次故障转移都会将整个可用性组里的数据库一起转移。
1,查看集群的资源组
打开故障转移集群管理器(Failover Cluster Manager),选中集群结点,点开Roles,集群的每个角色就是一个资源组,在右边的资源组监控器面板中,能够看到创建成功的可用性组 TestAG,角色类型(Type)是Other;

2,资源组的故障转移属性
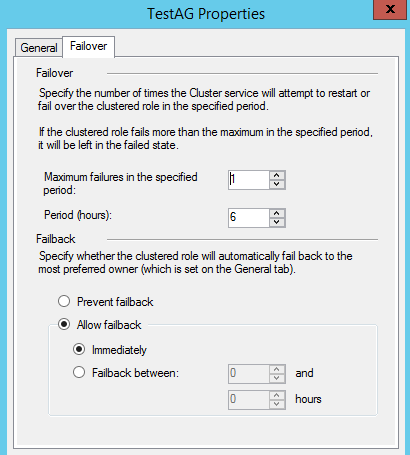
右击角色的属性,在Failover Tab中,查看集群的故障转移属性的设置,默认设置如下图:
- 故障转移(Failover)属性:设置集群在指定的时间区间内执行故障转移的次数;
- 故障恢复(Failback)属性:设置集群在发生故障转移之后,把资源组移回到最优先节点;
两者的区别是:
- 故障转移(Failover)是指:出现故障后转移,集群把故障结点拥有的资源组转移到另一个可用的结点上;
- 故障恢复(Failback)是指:出现故障后恢复,在发生故障转移之后,如果最优先结点恢复正常,把资源组移回到最优先节点;
3,切换到General Tab
首选结点(Preferred Owners)选项的默认设置是勾选集群中的所有结点,优先顺序是从上到下,第一个勾选的结点是最优先结点(Most Preferred Owners)。
在发生故障转移之后,如果最优先结点恢复健康,那么故障恢复(Failback)将资源组移回到最优先选结点;

二,从集群资源的角度来看待SQL Server 可用性组
由于AlwaysOn 可用性组建立在故障转移集群之上,可用性组就是Windows 集群的资源组,在故障转移集群管理器中,通过配置集群资源的属性,控制AlwaysOn 可用性组的健康检测和故障转移特性的底层特性。
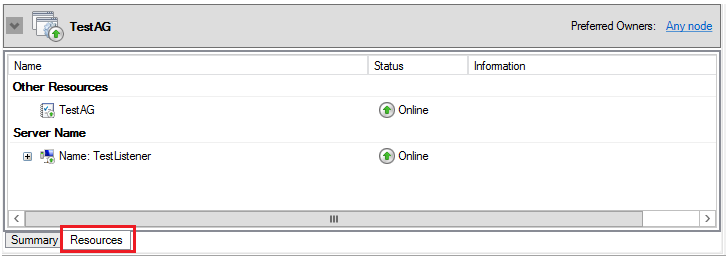
点击角色TestAG下方面板Resource选项卡,能够看到该资源组拥有两个资源:可用性组TestAG和侦听器TestListener。这两个资源在创建AlwaysOn时,由系统自动创建。每个资源,都有Status标识该资源的健康状态。
在Server Name 选项卡中,列出AlwaysOn可用性组中包含的Listener,该Listener 的集群资源类型是Network Name,这就是说,AlwaysOn不使用Windows集群的虚拟网络名和虚拟IP地址,而是使用Listener来作为访问可用性组的网络接口。无论Windows 集群的虚拟网络名,还是AlwaysOn的侦听器Listener,其资源类型都是相同的(Network Name),都有虚拟网络名(DNS Name)和虚拟IP地址,只是一个服务于Windows集群,一个服务于AlwaysOn,其行为是相同的:
- 使用Windows集群的虚拟网络名,用户看不到集群背后的一堆Windows Server,当资源发生故障时,WSFC自动将资源转移到健康的结点上;
- 使用Listener,用户看不到AlwaysOn集群背后的一堆可用性副本,当一个副本发生故障时,AlwaysOn自动转移到健康的副本上;
- 根本差异在于:集群使用共享资源,没有数据的冗余,而AlwaysOn的各个可用性副本(Availability Replica)上都存储数据的一个副本;
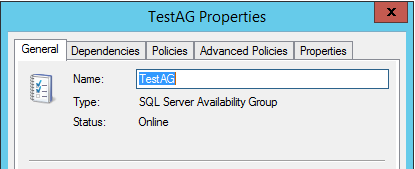
1,集群资源(可用性组)的属性
TestAG资源的类型是SQL Server Availability Group,状态是Online
2,切换到Dependencies Tab,查看资源的依赖关系
资源组中的资源是相互依赖的,一个资源所依赖的其他资源必须和该资源处于同一个资源组,跨资源组的依赖关系是不存在的。资源TestAG 和 资源Server Name之间是“and”的关系,这就是说,只有这两个资源都处于Online状态之后,整个资源组才处于可用的Online状态。
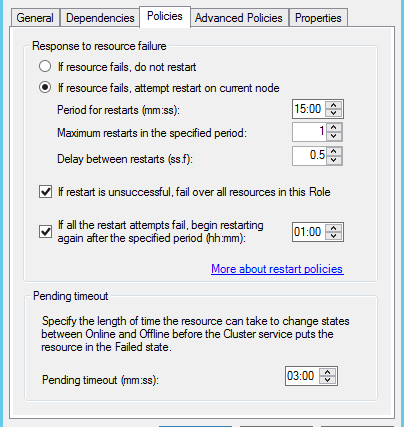
3,切换到Policies Tab,查看资源出现故障时,集群监控器的响应策略
该选项卡的选项决定了资源发生故障转移时的行为,建议保留其默认设置,默认设置是当资源出现故障时,会在15分钟内尝试在当前结点重启(一般是立即尝试重启,不需要等待15分钟),第一次尝试重启失败,就会将整个资源组转移到其他的结点上,默认的关键选项:
选项“If resource fails, attempt restart on current node”:选择该选项,WSFC在检测到当前资源出现故障后,尝试在当前结点重启;
选项 “If restart is unsuccessufll, fail over all resources in this service or application” :勾选该选项,WSFC在第一次重启失败后,将整个资源组转移到集群中的其他结点上;如果不勾选该选项,该资源出现故障,并不会导致整个资源组的故障转移。
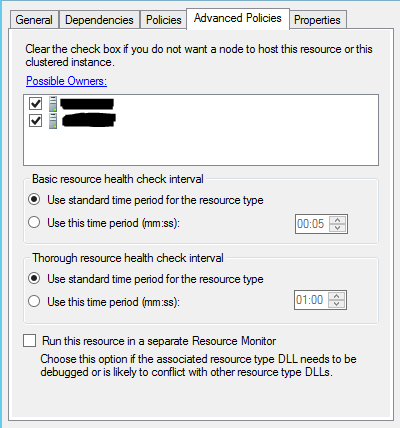
4,切换到Advanced Policies Tab
配置持有资源的集群结点:在Possible Owners 选项卡中,罗列出当前资源能够转移到的结点,也就是指定哪些结点会是当前资源的拥有者;如果一个结点没有被勾选,就意味着当前资源不会在该结点上运行。
配置检测资源健康的时间间隔:WSFC为了检测每个资源是否工作正常,会使用不同的时间间隔来做两种不同程度的检查,对于SQL Server可用组资源类型:
- “Basic resource health check interval” 称作“Looksalive check”,默认的时间间隔是5s;
- “Thorough resource health check interval”称作“Isalive check”,默认的时间间隔是30s;
第三章节会详细描述集群资源的检查检测。
- 部署AlwaysOn第三步:集群资源组的健康检测和故障转移
- 部署AlwaysOn第一步:搭建Windows服务器故障转移集群
- 部署AlwaysOn第一步:搭建Windows服务器故障转移集群
- 部署AlwaysOn第一步:搭建Windows服务器故障转移集群
- 部署AlwaysOn第一步:搭建Windows服务器故障转移集群
- alwayson 故障转移 的 looksalive check和is alive check
- 故障转移集群的仲裁
- 故障转移集群的仲裁
- 故障转移集群的仲裁
- Wind2008 服务器故障转移集群的准备
- Redis集群--故障转移
- Windows 2012配置故障转移(For SQLServer 2014 AlwaysOn)
- SQL Server故障转移集群
- 搭建和部署Windows Server 2008故障转移群集
- Redis + Keepalived主从集群的搭建及故障转移
- SQL Server 2008故障转移集群概述
- 配置Windows Server2008故障转移集群
- 轻松学会 SQL Server集群故障转移
- Linux下安装redis的安装与测试运行详细解析
- 【安全牛学习笔记】proxytunnle
- Kubernetes应用健康检查
- 关于服务
- mission信息
- 部署AlwaysOn第三步:集群资源组的健康检测和故障转移
- tensorflow 计算两个序列的co-attention矩阵
- 阿莫电子论坛 莫进明 涉嫌用户数量造假
- iOS开发中字符串和字典的转换
- 南阳理工_48小明的调查作业
- 建造者模式
- linux head命令
- java中List按照指定字段排序工具类
- 负载均衡原理与实践详解 第六篇 健康检查机制详解(上)


