文本挖掘的分词原理
来源:互联网 发布:sqlserver怎么读 编辑:程序博客网 时间:2024/05/17 09:10
from : http://www.cnblogs.com/pinard/p/6677078.html
在做文本挖掘的时候,首先要做的预处理就是分词。英文单词天然有空格隔开容易按照空格分词,但是也有时候需要把多个单词做为一个分词,比如一些名词如“New York”,需要做为一个词看待。而中文由于没有空格,分词就是一个需要专门去解决的问题了。无论是英文还是中文,分词的原理都是类似的,本文就对文本挖掘时的分词原理做一个总结。
1. 分词的基本原理
现代分词都是基于统计的分词,而统计的样本内容来自于一些标准的语料库。假如有一个句子:“小明来到荔湾区”,我们期望语料库统计后分词的结果是:"小明/来到/荔湾/区",而不是“小明/来到/荔/湾区”。那么如何做到这一点呢?
从统计的角度,我们期望"小明/来到/荔湾/区"这个分词后句子出现的概率要比“小明/来到/荔/湾区”大。如果用数学的语言来说说,如果有一个句子
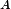








其中下标

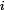




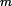







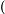


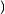
但是我们的概率分布


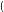

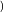
在前面我们讲MCMC采样时,也用到了相同的假设来简化模型复杂度。使用了马尔科夫假设,则我们的联合分布就好求了,即:

而通过我们的标准语料库,我们可以近似的计算出所有的分词之间的二元条件概率,比如任意两个词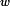




其中
利用语料库建立的统计概率,对于一个新的句子,我们就可以通过计算各种分词方法对应的联合分布概率,找到最大概率对应的分词方法,即为最优分词。
2. N元模型
当然,你会说,只依赖于前一个词太武断了,我们能不能依赖于前两个词呢?即:
,, 这样也是可以的,只不过这样联合分布的计算量就大大增加了。我们一般称只依赖于前一个词的模型为二元模型(Bi-Gram model),而依赖于前两个词的模型为三元模型。以此类推,我们可以建立四元模型,五元模型,...一直到通用的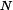
在实际应用中,

3. 维特比算法与分词
为了简化原理描述,我们本节的讨论都是以二元模型为基础。
对于一个有很多分词可能的长句子,我们当然可以用暴力方法去计算出所有的分词可能的概率,再找出最优分词方法。但是用维特比算法可以大大简化求出最优分词的时间。
大家一般知道维特比算法是用于隐式马尔科夫模型HMM解码算法的,但是它是一个通用的求序列最短路径的方法,不光可以用于HMM,也可以用于其他的序列最短路径算法,比如最优分词。
维特比算法采用的是动态规划来解决这个最优分词问题的,动态规划要求局部路径也是最优路径的一部分,很显然我们的问题是成立的。首先我们看一个简单的分词例子:"人生如梦境"。它的可能分词可以用下面的概率图表示:
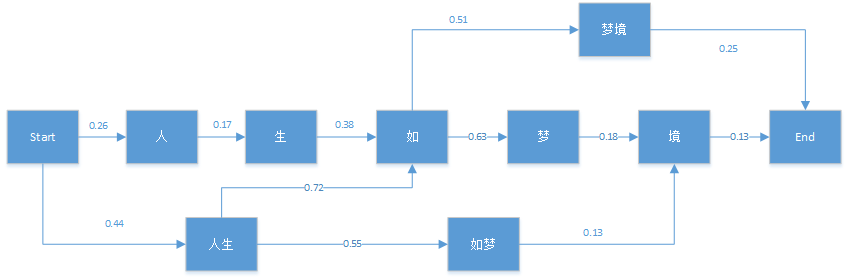
图中的箭头为通过统计语料库而得到的对应的各分词条件概率。比如P(生|人)=0.17。有了这个图,维特比算法需要找到从Start到End之间的一条最短路径。对于在End之前的任意一个当前局部节点,我们需要得到到达该节点的最大概率

我们先用这个例子来观察维特比算法的过程。首先我们初始化有:
人

 人
人 人生
人生 人生
人生对于节点"生",它只有一个前向节点,因此有:
生人生人生人对于节点"如",就稍微复杂一点了,因为它有多个前向节点,我们要计算出到“如”概率最大的路径:
如 生如生,人生如人生
生如生,人生如人生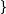


 如人生
如人生类似的方法可以用于其他节点如下:
如梦人生如梦人生如梦人生梦如梦如 梦如境梦境梦如梦境如梦
梦如境梦境梦如梦境如梦 境梦梦境梦境梦境如梦境如
境梦梦境梦境梦境如梦境如最后我们看看最终节点End:

 梦境梦境境境
梦境梦境境境 梦境
梦境 由于最后的最优解为“梦境”,现在我们开始用
梦境 梦境如如人生人生
梦境如如人生人生
从而最终的分词结果为"人生/如/梦境"。是不是很简单呢。
由于维特比算法我会在后面讲隐式马尔科夫模型HMM解码算法时详细解释,这里就不归纳了。
4. 常用分词工具
对于文本挖掘中需要的分词功能,一般我们会用现有的工具。简单的英文分词不需要任何工具,通过空格和标点符号就可以分词了,而进一步的英文分词推荐使用nltk。对于中文分词,则推荐用结巴分词(jieba)。这些工具使用都很简单。你的分词没有特别的需求直接使用这些分词工具就可以了。
5. 结语
分词是文本挖掘的预处理的重要的一步,分词完成后,我们可以继续做一些其他的特征工程,比如向量化(vectorize),TF-IDF以及Hash trick,这些我们后面再讲。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
- 文本挖掘的分词原理
- 文本挖掘的分词原理
- 文本挖掘1分词
- 文本挖掘--LTP-cloud 分词
- 文本挖掘分词mapreduce化
- R语言文本挖掘-分词
- 基于SNS的文本数据挖掘--非监督分词
- 文本挖掘系统的实现之R语言分词
- R语言︱文本挖掘之中文分词包——Rwordseg包(原理、功能、详解)
- 【R文本挖掘】中文分词Rwordseg
- 【R文本挖掘】中文分词Rwordseg
- 【R文本挖掘】中文分词Rwordseg
- R文本挖掘之二分词
- R文本挖掘-中文分词Rwordseg
- 文本挖掘--将分词之后的文档转化为结构化的数据
- 文本挖掘的体会
- 文本挖掘的概述
- 文本挖掘的介绍
- 算数运算符和算术表达式
- 程序底层查看工具之dumpbin
- Codeforces Round #336 (Div. 2)-C Chain Reaction(二分+DP)
- Arduino的toInt()注意事项
- win系统删除,已经注册的服务
- 文本挖掘的分词原理
- Java集合类解析
- FastDFS 图片上传功能实现
- [UE4]编译时的各个平台定义宏
- 调整数组顺序使奇数位于偶数前面(剑指Offer 第 13 题)
- c++ 调用Python接口小问题
- 322. Coin Change
- zookeeper技术原理(转)
- 深度学习Loss function之Softmax中的矩阵求导


