二叉树深度优先遍历和广度优先遍历
来源:互联网 发布:贵州大数据 编辑:程序博客网 时间:2024/06/06 10:56
二叉树深度优先遍历和广度优先遍历
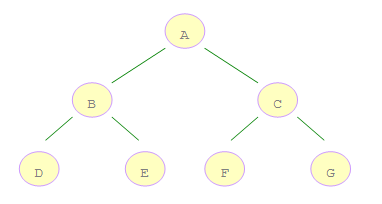
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。以上面二叉树为例,深度优先搜索的顺序
为:ABDECFG。怎么实现这个顺序呢 ?深度优先搜索二叉树是先访问根结点,然后遍历左子树接着是遍历右子树,因此我们可以利用堆栈的先进后出的特点,
现将右子树压栈,再将左子树压栈,这样左子树就位于栈顶,可以保证结点的左子树先与右子树被遍历。
广度优先搜索(Breadth First Search),又叫宽度优先搜索或横向优先搜索,是从根结点开始沿着树的宽度搜索遍历,上面二叉树的遍历顺序为:ABCDEFG.
# 广度优先/深度优先遍历二叉树
class Node:
def __init__(self, data, left, right):
self._data = data
self._left = left
self._right = right
class BinaryTree:
def __init__(self):
self._root = None
def make_tree(self, node):
self._root = node
def insert(self, node):
# 这里是建立一个完全二叉树
lst = []
def insert_node(tree_node, p, node):
if tree_node._left is None:
tree_node._left = node
lst.append(tree_node._left)
return
elif tree_node._right is None:
tree_node._right = node
lst.append(tree_node._right)
return
else:
lst.append(tree_node._left)
lst.append(tree_node._right)
if p > (len(lst) -2):
return
else:
insert_node(lst[p+1], p+1, node)
lst.append(self._root)
insert_node(self._root, 0, node)
def breadth_tree(tree):
lst = []
def traverse(node, p):
if node._left is not None:
lst.append(node._left)
if node._right is not None:
lst.append(node._right)
if p > (len(lst) -2):
return
else:
traverse(lst[p+1], p+1)
lst.append(tree._root)
traverse(tree._root, 0)
# 遍历结果就存在了lst表里
for node in lst:
print node._data
def depth_tree(tree):
lst = []
lst.append(tree._root)
while len(lst) > 0:
node = lst.pop()
print node._data
if node._right is not None:
lst.append(node._right)
if node._left is not None:
lst.append(node._left)
if __name__ == '__main__':
lst = [12, 9, 7, 19, 3, 8, 52, 106, 70, 29, 20, 16, 8, 50, 22, 19]
tree = BinaryTree()
# 生成完全二叉树
for (i, j) in enumerate(lst):
node = Node(j, None, None)
if i == 0:
tree.make_tree(node)
else:
tree.insert(node)
# 广度优先遍历
breadth_tree(tree)
# 深度优先遍历
depth_tree(tree)
class Node:
def __init__(self, data, left, right):
self._data = data
self._left = left
self._right = right
class BinaryTree:
def __init__(self):
self._root = None
def make_tree(self, node):
self._root = node
def insert(self, node):
# 这里是建立一个完全二叉树
lst = []
def insert_node(tree_node, p, node):
if tree_node._left is None:
tree_node._left = node
lst.append(tree_node._left)
return
elif tree_node._right is None:
tree_node._right = node
lst.append(tree_node._right)
return
else:
lst.append(tree_node._left)
lst.append(tree_node._right)
if p > (len(lst) -2):
return
else:
insert_node(lst[p+1], p+1, node)
lst.append(self._root)
insert_node(self._root, 0, node)
def breadth_tree(tree):
lst = []
def traverse(node, p):
if node._left is not None:
lst.append(node._left)
if node._right is not None:
lst.append(node._right)
if p > (len(lst) -2):
return
else:
traverse(lst[p+1], p+1)
lst.append(tree._root)
traverse(tree._root, 0)
# 遍历结果就存在了lst表里
for node in lst:
print node._data
def depth_tree(tree):
lst = []
lst.append(tree._root)
while len(lst) > 0:
node = lst.pop()
print node._data
if node._right is not None:
lst.append(node._right)
if node._left is not None:
lst.append(node._left)
if __name__ == '__main__':
lst = [12, 9, 7, 19, 3, 8, 52, 106, 70, 29, 20, 16, 8, 50, 22, 19]
tree = BinaryTree()
# 生成完全二叉树
for (i, j) in enumerate(lst):
node = Node(j, None, None)
if i == 0:
tree.make_tree(node)
else:
tree.insert(node)
# 广度优先遍历
breadth_tree(tree)
# 深度优先遍历
depth_tree(tree)
阅读全文
0 0
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的广度优先遍历和深度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- 二叉树的深度优先遍历和广度优先遍历
- Qt正则表达式
- Docker(初识整理)
- 输入框
- XSLT常见问题(一)转化后如何输出文件头
- 实践题目——指针及其运算
- 二叉树深度优先遍历和广度优先遍历
- PostgreSQL列举所有的表空间及schema及角色
- 企业现金流和资金链区别
- js获取table的行数与列数
- 关于tcp三次握手的学习
- HttpClient入门教程
- spark mongo
- XSLT常见问题(二)XSLT中变量的使用(variable)
- stm32f10x在keil环境下的配置


