Hive安装及基本命令整理超详细超详细超详细重要的事情说三遍以及连接错误问题处理
来源:互联网 发布:淘宝手机模板 编辑:程序博客网 时间:2024/06/05 10:57

在~下创建hive文件夹,再在hive下创建ubunt0文件夹



$>/have/bin/schemaTool -initSchema -dbType mysql
删除之前生成的元数据库和hdfs上的/usr/hive/
jar -tf xxx.jar //查看jar包
hive下按两次tab键可以显示所有函数提示

<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1</version>
</dependency>

$hive>create table hive1.t as select * from othertable;

--[table]this is a comment ! 这个是hive中的注释,跟MySQL中是一样的


传统数据库是写时模式,在写入的时候校验,hive是读时模式,在写入的时候不校验,查询的时候校验
级联删除库:drop database if exists xxx cascade;
指定目录下创建数据库:create database hive2 location '/usr/ubuntu/hive2.db';
创建库有扩展信息:create database hive3 with dbproperties(''='',''='');
描述:desc database extended hive3;
hive默认创建的表都是托管表managed table.hive 控制其数据的生命周期,默认将这些表的数据存在hive.metastore.warehouse.dir.
创建外部表:create external table hive1.test like hive2.test //只有表结构
创建表:create table hive1.test as select * from hive2.test //带数据,不能用于创建外部表





一)hive中支持两种类型的分区:
- 静态分区SP(static partition)
- 动态分区DP(dynamic partition)
二)实战演示如何在hive中使用动态分区
1、创建一张分区表,包含两个分区dt和ht表示日期和小时
2、启用hive动态分区,只需要在hive会话中设置两个参数:
使用静态分区时,必须指定分区的值,如:
此时我们发现一个问题,如果希望插入每天24小时的数据,则需要执行24次上面的语句。而动态分区会根据select出的结果自动判断数据改load到哪个分区中去。
4、使用动态分区
hive先获取select的最后两个位置的dt和ht参数值,然后将这两个值填写到insert语句partition中的两个dt和ht变量中,即动态分区是通过位置来对应分区值的。原始表select出来的值和输出partition的值的关系仅仅是通过位置来确定的,和名字并没有关系,比如这里dt和st的名称完全没有关系。只需要一句SQL即可把20150617下的24个ht分区插到了新表中。
三)静态分区和动态分区可以混合使用
1、全部DP
2、DP/SP结合
3、当SP是DP的子分区时,以下DML会报错,因为分区顺序决定了HDFS中目录的继承关系,这点是无法改变的
4、多张表插入
5、CTAS,(CREATE-AS语句),DP与SP下的CTAS语法稍有不同,因为目标表的schema无法完全的从select语句传递过去。这时需要在create语句中指定partition列
6、上面展示了DP下的CTAS用法,如果希望在partition列上加一些自己的常量,可以这样做


左半连接:查询显示左边的信息,前提满足右边的条件。左半连接select和where子句中不能包含右边表的字段
hive不支持右半开连接


set hive.mapjoin.smalltable.filesize=25000000 //设置小表的阈值,小于这个值就开始在map端连接
设置后直接查询即可,可不用写/*+maojoin(x)*/.加上这个标记也是可用的。
hive对于右外连接(right out join)和全外连接(full out join)不支持这个优化。
sort by:局部排序 order by:全排序








只能对内部表进行归档,外部表不能归档。


如果还不行就把hadoop-archives-2.7.2.jar放到/soft/hive/lib/下




浮点数比较规避方案:select cast(0.2 as float);
%在sql语句中表示通配符,,在模糊查询中用到 如查询姓名以 张开头的 就写成 like ‘张%’ 如 姓名以 国结尾的 写成 like ‘%国’。。。 姓名中包含 峰的 写成 like '%峰%'.
limit(1,2) 1:偏移量 ; 2:取的个数
join:hive只支持等值连接,即运算符是“=”。


Hive的meta数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储。远端存储比较适合生产环境。Hive官方wiki详细介绍了这三种方式,链接为:Hive Metastore。
我们先建立一个分桶表,并尝试直接上传一个数据
create table student4(sno int,sname string,sex string,sage int, sdept string) clustered by(sno) into 3 buckets row format delimited fields terminated by ',';set hive.enforce.bucketing = true;强制分桶。load data local inpath '/home/hadoop/hivedata/students.txt' overwrite into table student4;

我们看到虽然设置了强制分桶,但实际student表下面只有一个students一个文件。分桶也就是分区,分区数量等于文件数,所以上面方法并没有分桶。
现在,我们用插入的方法给另外一个分桶表传入同样数据

create table student4(sno int,sname string,sex string,sage int, sdept string) clustered by(sno) into 3 buckets row format delimited fields terminated by ',';set hive.enforce.bucketing = true;强制分桶。load data local inpath '/home/hadoop/hivedata/students.txt' overwrite into table student4;我们看到虽然设置了强制分桶,但实际STUDENT表下面只有一个STUDENTS一个文件。分桶也就是分区,分区数量等于文件数,所以上面方法并没有分桶。#创建第2个分桶表create table stu_buck(sno int,sname string,sex string,sage int,sdept string)clustered by(sno) sorted by(sno DESC)into 4 bucketsrow format delimitedfields terminated by ',';#设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数set hive.enforce.bucketing = true;set mapreduce.job.reduces=4;#开会往创建的分通表插入数据(插入数据需要是已分桶, 且排序的)#可以使用distribute by(sno) sort by(sno asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段)#注意使用cluster by 就等同于分桶+排序(sort)insert into table stu_buckselect sno,sname,sex,sage,sdept from student distribute by(sno) sort by(sno asc);
Query ID = root_20171109145012_7088af00-9356-46e6-a988-f1fc5f6d2e13
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 4
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1510197346181_0014, Tracking URL = http://server71:8088/proxy/application_1510197346181_0014/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1510197346181_0014
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 4
2017-11-09 14:50:59,642 Stage-1 map = 0%, reduce = 0%
2017-11-09 14:51:38,682 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.04 sec
2017-11-09 14:52:31,935 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 7.91 sec
2017-11-09 14:52:33,467 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 15.51 sec
2017-11-09 14:52:39,420 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 22.5 sec
2017-11-09 14:52:40,953 Stage-1 map = 100%, reduce = 92%, Cumulative CPU 25.86 sec
2017-11-09 14:52:42,243 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 28.01 sec
MapReduce Total cumulative CPU time: 28 seconds 10 msec
Ended Job = job_1510197346181_0014
Loading data to table default.stu_buck
Table default.stu_buck stats: [numFiles=4, numRows=22, totalSize=527, rawDataSize=505]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 4 Cumulative CPU: 28.01 sec HDFS Read: 18642 HDFS Write: 819 SUCCESS
Total MapReduce CPU Time Spent: 28 seconds 10 msec
OK
Time taken: 153.794 seconds
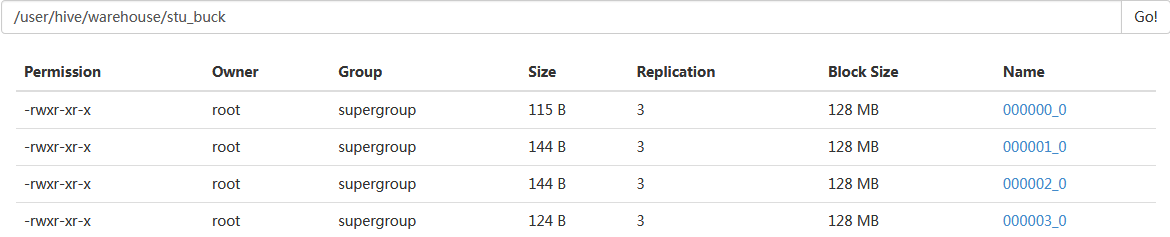
我们设置reduce的数量为4,学过mapreduce的人应该知道reduce数等于分区数,也等于处理的文件数量。
把表或分区划分成bucket有两个理由1,更快,桶为表加上额外结构,链接相同列划分了桶的表,可以使用map-side join更加高效。2,取样sampling更高效。没有分区的话需要扫描整个数据集。hive> create table bucketed_user (id int,name string)> clustered by (id) sorted by (id asc) into 4 buckets;重点1:CLUSTERED BY来指定划分桶所用列和划分桶的个数。HIVE对key的hash值除bucket个数取余数,保证数据均匀随机分布在所有bucket里。重点2:SORTED BY对桶中的一个或多个列另外排序总结:我们发现其实桶的概念就是MapReduce的分区的概念,两者完全相同。物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。而分区表的概念,则是新的概念。分区代表了数据的仓库,也就是文件夹目录。每个文件夹下面可以放不同的数据文件。通过文件夹可以查询里面存放的文件。但文件夹本身和数据的内容毫无关系。桶则是按照数据内容的某个值进行分桶,把一个大文件散列称为一个个小文件。这些小文件可以单独排序。如果另外一个表也按照同样的规则分成了一个个小文件。两个表join的时候,就不必要扫描整个表,只需要匹配相同分桶的数据即可。效率当然大大提升。同样,对数据抽样的时候,也不需要扫描整个文件。只需要对每个分区按照相同规则抽取一部分数据即可。


一、本地derby
这种方式是最简单的存储方式,只需要在hive-site.xml做如下配置便可
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误
二、本地mysql
这种存储方式需要在本地运行一个mysql服务器,并作如下配置(下面两种使用mysql的方式,需要将mysql的jar包拷贝到$HIVE_HOME/lib目录下)。三、远端mysql
这种存储方式需要在远端服务器运行一个mysql服务器,并且需要在Hive服务器启动meta服务。
这里用mysql的测试服务器,ip位192.168.1.214,新建hive_remote数据库,字符集位latine1
注:这里把hive的服务端和客户端都放在同一台服务器上了。服务端和客户端可以拆开,将hive-site.xml配置文件拆为如下两部分
1)、服务端配置文件
2)、客户端配置文件
启动hive服务端程序
客户端直接使用hive命令即可
问题导读
1、如何加载分区表数据?2、Hive中如何查询使用多少个MapReduce作业 ?
3、查看数组、map、结构?
创建表:
创建一个新表,结构与其他一样
创建分区表:
加载分区表数据:
展示表中有多少分区:
展示所有表:
显示表的结构信息
更新表的名称:
添加新一列
删除表:
删除表中数据,但要保持表的结构定义
从本地文件加载数据:
显示所有函数:
查看函数用法:
查看数组、map、结构
内连接:
查看hive为某个查询使用多少个MapReduce作业
外连接:
in查询:Hive不支持,但可以使用LEFT SEMI JOIN
Map连接:Hive可以把较小的表放入每个Mapper的内存来执行连接操作
INSERT OVERWRITE TABLE ..SELECT:新表预先存在
CREATE TABLE ... AS SELECT:新表表预先不存在
创建视图:
查看视图详细信息:
9. <property>
<name>hive.metastore.uris</name>
<value>uri1,uri2,... </value>//可配置多个 uri
<description>JDBC connect string for a JDBC metastore</description>
</property>
这个配置的含义是什么?
10.当在Hadoop的HA环境中Hive Server安装在哪里比较合适?
11.每个DataNode上都已经安装了Hbase,是否都要安装Hive?

第8问回答:Hive的安装其实有两部分组成,一个是Server端、一个是客户端,所谓服务端其实就是Hive管理Meta的那个Hive,服务端可以装在任何节点上,可以是Namenode上也可以是Datanode的任意一个节点上,至于哪个节点做Hive的服务端,由自己决定,不过在Hadoop的HA环境里我想应该是在两个NameNode里都装成Hive的Server,并且hive.metastore.warehouse.dir 配置成hdfs://****,这样其他节点安装的Hive就都是客户端了,并且hive.metastore.uris值可以指向这两个NameNode的Ip.(仅代表个人理解,如果有不对的地方请多多指教)
主要属性解释:
hive.metastore.uris:指定hive元数据访问路径
hive.metastore.warehouse.dir:(HDFS上的)数据目录
hive.exec.scratchdir:(HDFS上的)临时文件目录
hive.metastore.warehouse.dir默认值是/user/hive/warehouse
hive.exec.scratchdir默认值是/tmp/hive-${user.name}
第9问回答:这个属性都配置在客户端,ip地址指向的是Hive服务端Ip地址,端口是默认的。 可以看到value可以指向多个ip,意思应该是多个Hive Server所在主机。(仅代表个人理解,不吝赐教)
第10问回答:个人认为安装在NameNode所在节点(假如集群有两个NameNode,那么两个NameNode都要安装)。
第11问回答:其实根据前面问题的回答,这个问题已经不需解释,这个问题的底层意思应该是说Hive数据的存储问题,比如Hbase在每个节点上都部署了,并且存储会根据数据的分裂存储在各个Datanode上,那么是不是没有安装Hive的DataNode上就无法存储Hive的数据?其实,Hive数据的存储是根据hive.metastore.warehouse.dir这个属性来配置,这个属性加入制定的是HDFS集群,那么Hive数据的存储已经指向了所有的DataNode了。
对于以上这些疑问已经纠结两天,这是我昨天在论坛的提问http://www.aboutyun.com/thread-10917-1-1.html;对于以上有说错的地方,请不吝赐教,以免误人子弟,谢谢!
下面分享个Hive三种配置的介绍,加深下概念的理解:
一、本地derby这种方式是最简单的存储方式,只需要在hive-site.xml做如下配置便可
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个
metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误
hive> show tables;
FAILED: Error in metadata: javax.jdo.JDOFatalDataStoreException: Failed to start database 'metastore_db', see the next exception for details.
NestedThrowables:
java.sql.SQLException: Failed to start database 'metastore_db', see the next exception for details.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
二、本地mysql这种存储方式需要在本地运行一个mysql服务器,并作如下配置(下面两种使用mysql的方式,需要将mysql的jar包拷贝到$HIVE_HOME/lib目录下)。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
</configuration>
三、远端mysql
这种存储方式需要在远端服务器运行一个mysql服务器,并且需要在Hive服务器启动meta服务。这里用mysql的测试服务器,ip位192.168.1.214,新建hive_remote数据库,字符集位latine1
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.214:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.1.188:9083</value>
</property>
</configuration>
注:这里把hive的服务端和客户端都放在同一台服务器上了。服务端和客户端可以拆开,将hive-site.xml配置文件拆为如下两部分
1)、服务端配置文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.214:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>test1234</value>
</property>
</configuration>
2)、客户端配置文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.1.188:9083</value>
</property>
</configuration>
启动hive服务端程序
$ hive --service metastore
客户端直接使用hive命令即可
root@my188:~$ hive
Hive history file=/tmp/root/hive_job_log_root_201301301416_955801255.txt
hive> show tables;
OK
test_hive
Time taken: 0.736 seconds
hive>
问题重现1:
开始定义的 url ="jdbc:hive://master:10000/default"; 结果报如下错误:
java.sql.SQLException: No suitable driver found forjdbc:hive://master:10000/default
atjava.sql.DriverManager.getConnection(DriverManager.java:596)
atjava.sql.DriverManager.getConnection(DriverManager.java:215)
at com.berg.hive.test1.api.Test01Hive.getConn(Test01Hive.java:50)
atcom.berg.hive.test1.api.Test01Hive.main(Test01Hive.java:37)
问题1解决:
将url更改为: url = "jdbc:hive2://master:10000/default";
问题1解决思路来源:
http://stackoverflow.com/questions/33722139/java-sql-sqlexception-no-suitable-driver-found-for-jdbchive-localhost10000
问题重现2:
org.apache.hive.service.cli.HiveSQLException:Failed to open new session:
java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException
(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoop is not allowed to impersonate hive
at org.apache.hive.jdbc.Utils.verifySuccess(Utils.java:258)
at org.apache.hive.jdbc.Utils.verifySuccess(Utils.java:249)
atorg.apache.hive.jdbc.HiveConnection.openSession(HiveConnection.java:579)
atorg.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:167)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:107)
atjava.sql.DriverManager.getConnection(DriverManager.java:571)
atjava.sql.DriverManager.getConnection(DriverManager.java:215)
atcom.berg.hive.test1.api.Test01Hive.getConn(Test01Hive.java:50)
at com.berg.hive.test1.api.Test01Hive.main(Test01Hive.java:38)
Caused by: org.apache.hive.service.cli.HiveSQLException: Failed to open newsession:
java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException
(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoop isnot allowed to
impersonate hive
问题2解决:进入hadoop安装目录下,然后切换至etc/hadoop即hadoop-2.6.4/etc/hadoop,修改core-site.xml中文件内容,在原文件内容中添加:
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
如果你的是用neworigin用户访问,就改成:
<property>
<name>hadoop.proxyuser.neworigin.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.neworigin.groups</name>
<value>*</value>
</property>
我的修改后是:
<configuration>
<property><name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property> <property><name>hadoop.tmp.dir</name>
<value>file:/mysoftware/hadoop-2.6.4/tmp</value>
</property> <property><name>hadoop.native.lib</name>
<value>false</value>
</property> <property><name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property> <property><name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property></configuration>
问题2思路解决来源:
http://stackoverflow.com/questions/16582126/getting-e0902-exception-occured-user-oozie-is-not-allowed-to-impersonate-ooz
另外几个链接:
1. 重启mysql服务:
http://wwwlouxuemingcom.blog.163.com/blog/static/209747822013411103950266/
2. Could not open connection to jdbc
http://stackoverflow.com/questions/31150678/java-sql-sqlexception-could-not-open-connection-to-jdbchive2-localhost10000
3.Unable to instantiateorg.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
http://stackoverflow.com/questions/35449274/java-lang-runtimeexception-unable-to-instantiate-org-apache-hadoop-hive-ql-meta
- Hive安装及基本命令整理超详细超详细超详细重要的事情说三遍以及连接错误问题处理
- 超详细的GDB命令
- 超详细
- 超详细的Makefile
- 超详细MySQL安装及基本使用教程
- weblogic11G超详细安装及配置教程
- 常用SVN命令,超详细
- 超详细的图片处理 工具类
- 超详细的Java 异常处理
- linux 安装jdk 超详细
- Git超详细安装教程
- 超详细的sql2005图解安装全过程
- 安装CDH的超详细步骤
- centos6上超详细LAMP编译安装过程以及所遇到的问题
- CentOS6.4 下安装SVN的详细教程(超详细)
- hive udf开发超详细手把手教程
- hive udf开发超详细手把手教程
- ip的划分,超详细
- 实验4:栈和队列的基本操作实现及其应用——链栈
- 数据科学家——数据挖掘与机器学习
- 37. Sudoku Solver
- 数据库优化方案(转载)
- date(参数)里面的参数
- Hive安装及基本命令整理超详细超详细超详细重要的事情说三遍以及连接错误问题处理
- 智能手机全球普及率今年有望达到63%
- Lambda表达式与图灵完备
- 2017-10-16 集训总结
- 基于Qt的收银点餐系统之UI的改进——QStackedLayout和QScrollArea的使用
- View 的绘图流程 (二)
- ARC 076
- 事务的隔离级别
- 在windowns下安装Anaconda3运行spark


