一步步优化JVM
来源:互联网 发布:linux 获取网卡流量 编辑:程序博客网 时间:2024/06/06 04:18
一:概述、方法及需求
二:JVM部署模型和JVM Runtime
三:GC优化基础
四:决定Java堆的大小以及内存占用
五:优化延迟或者响应时间(1)
五:优化延迟或者响应时间(2)
五:优化延迟或者响应时间(3)
六:优化吞吐量
七:其他
一:概述、方法及需求
现代JVM是一个具有灵活适应各种应用能力的软件,尽管很多应用能够在JVM的默认配置下运行良好,但是有些应用还是需要优化JVM配置以达到其性能要求。由于各种各样的应用能够运行在现在JVM上面,所以大量的JVM选项可以配置来提升应用的性能。不幸的是,对一个应用而言优化得很好的JVM配置,对应另外的应用不一定适合。所以,真正理解怎样优化JVM配置是非常有必要的。
优化现代JVM是一门很大的艺术,但是理解和应用一些基本知识能够让优化JVM的任务变得更加简单。本章就是介绍这些基本知识和一些常规的步骤去优化Java HotSpot虚拟器。为了更好的理解本章的内容,你应该对JVM和垃圾回收器有一些基本的了解。
本章以一步步的优化方法包括一些假设开始,在优化JVM之前,你需要先知道怎样测试应用性能、性能需求、测试的基础工具以及用来收集数据的垃圾回收器的命令行选项。接下来有几个章节来说明怎么样一步步优HotSpot虚拟器行为——启动、内存的占用、吞吐量、延迟等。
1、方法
下面这张图片展示了本章要说明的方法。他由一些清晰的应用性能需求开始,这个性能需求应该是应用负责人排过优先级的。与描述计算什么及输出什么的功能层面需求相比较,系统层面需求描述了系统的一些指标,比如:吞吐量、响应时间、内存消耗、启动时间、可用性以及易管理性等等。
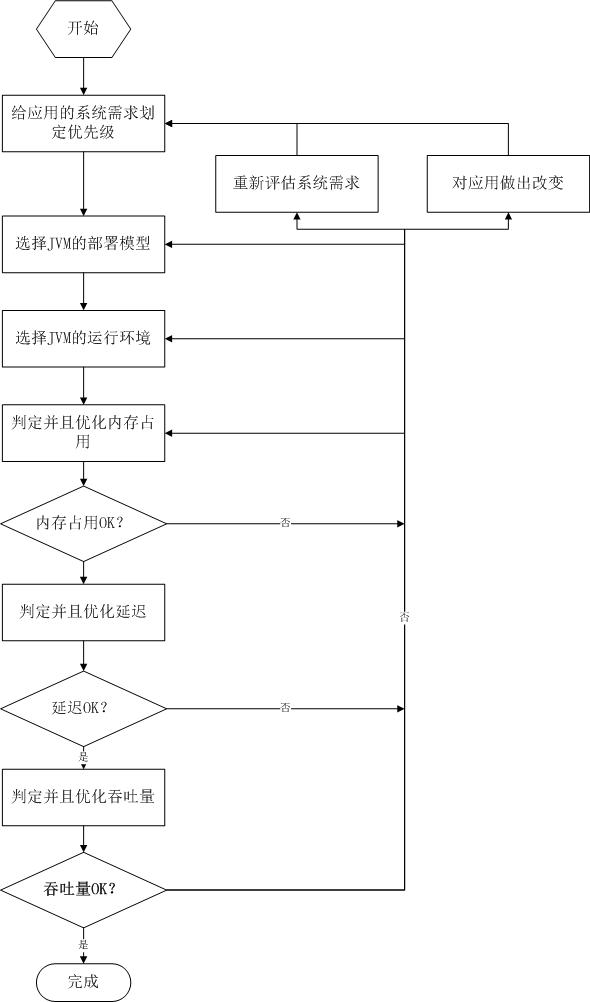

下一节,我们仔细看看每项系统指标对优化JVM的重要作用。
优化JVM性能涉及很多权衡,当你提升某一项性能指标的时候,往往需要牺牲其他指标。比如说,为了最少的消耗内存,往往需要以延迟或者响应时间作为代价。或者,你想要提升应用的易管理性,你需要降低应用的的可用性的级别,由于可用性的提升是建立在多个JVM上的,多个JVM可用降低一个JVM出错造成整个应用的无法使用的风险。由于有很多的取舍需要做,理解真正性能需求就变得极其重要了,理解需求才能够正确的使用方法。
一旦你知道了哪一些系统指标是重要的,接下来要做的就是选择JVM的部署模型,选择是部署在多JVM上面还是单个JVM上面。可用性、易管理性以及内存的占用等系统指标在选择合适的部署模型的时候都扮演了重要角色。
接下来就是选择JVM的Runtime,HotSpot虚拟器提供了聚焦在更快的启动速度和更小的内存占用的32位的client虚拟器,以及在32位和64位系统中有更高的吞吐量server虚拟器。系统对吞吐量、响应时间以及启动时间的需求决定了对JVM Runtime的选择。
接下来就是要优化垃圾回收器,以满足系统对内存占用、延迟以及吞吐量的需求,我们按照首先内存占用,其次延迟时间,最后吞吐量的顺序来进行优化。
优化是在不停地测试和调整配置中循环的,需要数次循环以达到性能的需求,另外,也有可能优化了一个点的时候,但是需要回到前面几个步骤重新进行检查。比如,假如你在几次优化垃圾回收器之后,对应用的延迟还是不满意,这个时候就有必要调整JVM的部署模型。另外一种可能是,应用程序有修改或者需要重新设定应用程序的性能需求。
对于一些应用以及它们的系统需求来说,需要循环几次这样的操作,直到应用责任人对应用的性能满意为止。
2、假设
这个一步步的优化步骤,是基于应用都有以下执行过程的假设:
1、初始化阶段——初始化重要的数据结构和其他需要使用的依赖库。
2、稳定阶段——应用消耗大部分的时间执行其核心函数。
3、可选的总结阶段——比如需要制作报告。
稳定阶段是我们需要主要关注的地方。
3、测试基础设施
为了做出关于内存占用、延迟、吞吐量以及启动时间等优化有根据的决定,并且为了证实选择的JVM运行环境是正确的,我们需要从试验中收集数据(需要注意的是这个试验要能够反映生产环境的实际情况)。因此,有一个能够代表生产环境的性能测试环境就相当重要了。包括硬件和软件都需要代表生产环境。简单的说,测试环境和生产环境越接近,做出来的优化决定越靠谱。
下面,我们详细介绍需求的定义。
4、性能需求详细描述
从前面我们知道,系统层面的需求决定应用的某一方面的特性,比如它的吞吐量、响应时间、消耗的内存、它的可用性以及易管理性等等。另外,功能需求决定了应用计算的内容或者产生的输出。


[PSYoungGen: 295648K->32968K(306432K)]提供了young代的空间信息,PSYoungGen表示young代的垃圾回收是使用throughput垃圾回收器。其他可能的young代垃圾回收有ParNew(使用CMS垃圾回收器多线程回收young代空间)、DefNew(使用serial垃圾回收器单线程回收young代空间)。

.png)


.png)

.png)
.png)
接下来的我们描述一下我们会涉及到层面的需求。
可用性
可用性是衡量应用处于可用状态的指标。可用性需求表明了当应用的某些组件损坏或者遇到错误的时候,整个应用或应用的其他部分处于可用状态。
在Java应用领域,高可用性可以通过把系统的分隔成各个组件,然后运行在不同JVM上面或者在多个JVM上面运行相同应用实例来实现。一个需要平衡的点是,当提升系统的可用性,系统的维护成本会升高。引入更多的JVM或者机器,那么就有更多的JVM需要管理,这个就是造成了成本的升高和复杂性的提升。
我们常见的可用性需求例子:“当系统某一部分出现错误的时候,不要让整个应用程序崩溃”。
易管理性
易管理性是衡量系统的运行和监控的成本以及配置应用的成本。易管理性的需求表明了这个应用被管理的容易程度。通常来讲,用更少的JVM去运行应用,那么需要付出更小的成本去维护和监控应用。而且更少的JVM应用配置也更加简单,但是这个是建立牺牲应用的可用性上面的。
一个简单的易管理性需求例子:“由于有限的资源,应用只能部署到尽量少的JVM上面。”
吞吐量
吞吐量是衡量系统在单位时间里面完成的工作数量。吞吐量需求通常忽略延迟或者响应时间。通常情况下,提升吞吐量需要以系统响应变慢和更多内存消耗作为代价。
一个吞吐量的例子:“这个应用需要每秒完成2500个事务。”
延迟和响应时间
延迟或者响应时间是衡量应用从接收到一个任务到完成这个任务消耗的时间。一个延迟或者响应时间的需求需要忽略吞吐量。通常来讲,提升应用的响 应时间需要以更低吞吐量或提高应用的内容消耗。
一个延迟或者响应时间的例子:"这个应用会在60毫秒内,执行完成交易操作。"
内存占用
内存占用是衡量应用消耗的内存,这个内存占用是指应用在运行在某一个吞吐量、延迟以及可用性和易管理性指标下的内存消耗,内存占用是通常描述为应用运行的时候Java堆的大小或者总共需要消耗内存。通常情况下,通过增加Java堆的大小以增加应用内存占用可以提升吞吐量或者减少延迟,或者两者兼具。当应用可用的内存减少的时候,吞吐量和延迟通常会受到损失。在给定内存的情况下,应用占用的内存可以限制应用的实例数(这个会影响可用性)。
一个例子说明内存占用的需求是:“这个应用会单独运行在一个8G的系统上面或者多出3个应用实例运行在一个24G的应用系统上面。”
启动时间
启动时间是衡量应用初始化的时间(如:eclipse的启动时间)。在Java应用中,大家可能对JVM优化应用的热点需要的时间感兴趣。Java应用初始化需要消耗的时间依赖于很多因素包括单不仅限于需要装载的类的数量、需要初始化的对象数量、并且这些对象怎么初始化,以及HotSpot虚拟器运行环境的选择(client or server,eclipse使用的HotSpot Client,Jboss会使用HotSpot Server,两者在初始化时间上和运行过程中对热点的优化不一样)。
抛开需要加载的类的数量、需要初始化的对象的数量以及对象如何初始化,使用HotSpot client运行环境会获得更快的启动速度,由于他没有做足够的优化,这些优化可以提供更高吞吐量和更低的延迟。相反,HotSpot Server运行环境需要更长的启动时间,由于它需要更好多的获得应用关于Java代码的信息,并且对生成的机器码进行了很高优化。
启动时间需求的例子如:“这个应用会再15秒内完成初始化。”
5、对系统需求进行优先级排序
优化操作的第一步就是对系统层面的需求进行优先级排序。做这个需要把主要的应用负责人叫到一起来商定优先级的排序,并且最终达成一致。这个讨论需要在应用的架构和设计阶段完成,由于这个讨论可以提供非常明确的结论,比如说:什么系统需求是最重要的。
对于应用的负责人来说,系统需求的优先级决定了优化操作。最重要的系统需求促使形成一些基本决定。比如说:可用性比易管理性重要,那么JVM部署模型就会采用部署多个JVM。相反如果易管理性比可用性重要,那么就更加倾向于选择单个JVM的部署模型。
如何选择JVM部署模型和JVM Runtime会在接下来的一节中讲到。
二:JVM部署模型和JVM Runtime
1、选择JVM部署模型
JVM部署模型的选择总体来说就是决定应用是部署在单个JVM实例还是多个JVM实例上(这里简单举例说明一下JVM实例,比如:我们常用eclipse开发,启动一个eclipse就是启动了一个JVM实例,然后在JVM中运行一个main程序,又会启动一个JVM实例,两个JVM实例是隔离开的)。哪一个是最适合你的应用的呢?这个是前面说到系统需求和潜在规则来决定的。比如说:假如你要部署您的应用在一个64位的机器上面,可以支持更大Java堆,如果应用依赖第三方的本地代码组件,而且这个第三方暂时不支持64位机器,那么你就必须要强制使用32位的JVM而且要使用更小优化的Java堆。
2、单实例JVM模型
在单实例的JVM上部署应用,有一个好处,就是可以减低管理成本,毕竟有更少的JVM需要去维护嘛。应用能够使用的总内存更小,由于每一个单独部署的JVM有能够使用的内存上限。
部署应用在单个JVM上存在的挑战是应用的可用性存在极高的风险,比如:JVM失败或者应用灾难性错误。
3、多实例JVM模型
部署Java应用在多个JVM上面有提高可用性和能够间接降低延迟的好处,由于应用部署在多个JVM上,某一个JVM出错,只会导致应用某部分无法使用,不会导致整个应用无法使用。多JVM部署可以提供低延迟,在多JVM部署中,Java堆的大小倾向于更小,更小Java堆可以允许有更小的垃圾回收暂停,垃圾回收器的暂停是明显影响延迟。另外,如果应用存在明显瓶颈,多个JVM部署可能帮助提升吞吐量,把压力分布到多个JVM上面,可以让用承受更大的压力。
使用多个JVM,JVM可能会和处理器绑定。把JVM和处理器绑定在一起,可以避免应用和JVM的线程在多个CPU上切换,提升CPU cache的命中率。
部署多JVM的挑战在于管理、监控和维护需要更多的努力。
4、一般的建议
没有最好的JVM部署模型,做出最合适的选择依赖于系统的需求,系统的需求才是最重要的。
一个约束需要意识到的是,如果Java应用需要大量的内存占用,把应用部署在单个JVM上面可能需要使用64位JVM上,64位可以提供比32位JVM更大Java堆大小。如果使用64位JVM,需要保证应用使用的任何第三方软件需要支持64位。另外,如果任何使用JNI去调用本地组件,不管是第三方组件还是自己应用开发的程序,需要确保的是他们必须在64位环境下编译。
根据作者的经验来看,越少的JVM数量越好,毕竟越容易维护。
5、选择JVM Runtime
为Java应用选择JVM Runtime,就是根据实际情况来选择使用合适的client或者server。
6、Client或者Server Runtime
当使用HotSpot VM的时候,有两种可以选择的JVM runtime。client runtime是快速启动,更小的内存占用以及快速代码(机器码)生成的JIT编译器。server runtime有更复杂的代码生成优化,作为服务型应用更为靠谱。在server runtime中可以发现针对JIT编译器有很多的优化,主要是收集了更多的关于程序的信息,以生成更高性能的代码。
第三种HotSpot VM runtime还在开发中,叫做tiered,他结合了client和server runtime优秀面,即更快的的启动时间和更高性能的生成代码。如果你使用的是Java 6 Update 25,Java 7或者更新的版本,你也许可以考虑使用tiered server runtime替换client runtime。要使用tiered server runtime可以使用这个命令行选项:-server -XX:+TieredCompilation。在这本书编写的时候,还不是极力推荐替换掉client runtime或者server runtime。
小提示:如果你不知道该如何选择,可以先选择server runtime。如果启动时间和内存占用无法接受,可以考虑切换成client runtime或者tiered runtime。依赖于你是使用什么版本的JVM。
7、32位或者64位JVM
除了client和server runtime的选择,还需要在32位或者64位之间做出选择,HotSpot VM的默认配置是32位的。做出32位和64位的选择取决于应用需要的内存占用以及依赖的第三方库是否支持64位系统——如果有通过JNI使用本地接口。决定应用需要消耗的内存占用,会在下节中介绍。下面的表格列出了一些指导帮助在32位JVM或者64位JVM之间做出选择。注意的是HotSpot VM还没有64位的client runtime。
8、垃圾回收器
在进入下一步优化之前,需要先做出选择初始的垃圾回收器。在HotSpot VM里面有好几种垃圾回收器可以使用:serial,throughput,mostly concurrent以及garbage first。
由于使用throughput垃圾回收器有可能能够满足应用对暂停时间的需要,可以优先选择throughput垃圾回收器,如果有需要再切换到concurrent垃圾回收器(CMS)。如果有切换到concurrent垃圾回收器的需要,我们将会在后面的优化延迟的时候讨论 。
使用throughput垃圾回收器可以通过HotSpot VM的命令行参数来指定:-XX:+UseParallelOldGC或者-XX:+UseParallelGC。 如果在你的HotSpont VM的版本上-XX:+UseParallelOldGC选项不能使用,使用+XX:UseParallelGC。两者的不同点在于,-XX:+UseParallelOldGC促发了多线程young代的垃圾回收和多线程old代的垃圾回收,也就是说minor垃圾回收和full垃圾回收都是多线程的。+XX:+UseParallelGC仅仅是young代的垃圾回收是多线程的,old代的垃圾回收的单线程的。因此,如果你想要young代和old代的垃圾回收都是多线程的就配置-XX:+UserParallelOldGC。而且-XX:+UserParallelOldGC是兼容-XX:+UseParallelGC。
三:GC优化基础
本节主要描述关于垃圾回收器性能的三个指标,三个关于垃圾回收器优化的基本原则,以及优化HotSpot VM的垃圾回收器的信息收集,在这些指标中权衡以及信息的收集是非常重要的。
1、性能指标
吞吐量:衡量垃圾回收器运行在性能峰值的时候不需要关心垃圾回收器暂停的时间或者需要占用内存的能力。
延迟:衡量垃圾回收器最小化甚至消灭由垃圾回收器引起的暂停时间和应用抖动的能力。
内存占用:衡量为了高效的运行,垃圾回收器需要的内存。
一项指标的提升,往往需要牺牲其他一项或者两项指标。换一句话说,一项指标的妥协通常是为了支持提升其他一项或者两项指标。然而,对于大多数应用来说,很少有3项指标都非常重要,通常,一项或者两项比其他的更重要。
由于始终需要各种权衡,那么知道哪项指标对应用是最有必要的就显得非常重要。
2、原则
在优化JVM垃圾回收器的时候,有3项基本原则
- 在minor垃圾回收器中,最大量的对象被回收,这个被称为Minor GC回收原则。秉承这个原则可以减少由应用产生的full垃圾回收数量和频率,Full垃圾回收往往需要更长的时间,以致于应用无法达到延迟和吞吐量的需求。
- 更多的内存分配给垃圾回收器,也就是说更大的Java堆空间,垃圾回收器和应用在吞吐量和延迟上会表现得更好,这条原则被称为GC最大内存原则。
- 优化JVM垃圾回收器的3个指标中的2个,这个被称为2/3 GC优化原则。
在进行优化JVM垃圾回收器的时候, 牢牢记住这三条原则会让你的优化任务更容易完成。
3、命令行选项和GC日志
从垃圾回收器获取监控信息,是优化JVM的重要操作。收集垃圾回收器信息的最好办法就是收集日志。这个意味着通过HotSpot VM的命令行选项可以收集垃圾回收器的统计信息。开启垃圾回收器日志(即使在生产环境)是很好的主意,其实开启垃圾回收器的开销很小而且可以提供丰富的信息,这些信息和垃圾回收器应用事件或者JVM事件有关系,比如说:一个应用在运行过程中出现了一个比较长的暂停,如果有垃圾回收信息,就可以判断出是垃圾回收器引起的暂停还是应用进行的其他操作引起的暂停。
有很多的HotSpot VM命令行选项可以用在垃圾回收的日志上面,下面列举几个推荐使用的命令行选项:
-XX:+PrintGCTimeStamps打印出垃圾回收发生的时间是距离HotSpot VM启动时间的秒数。-XX:+PrintGCDetails提供了垃圾回收特有的统计信息而且具体信息依赖于使用的垃圾回收器类型。-Xloggc:<filename>表示垃圾回收器的信息输出到叫<filename>的文件。
下面是通过使用-XX:+UseParallelOldGC或者-XX:+UseParallelGC选项来打印出来的垃圾回收信息,而且使用了前面列出的3个选项。
45.152是表明距离JVM启动到垃圾回收的秒数,GC标签表明是Minor GC或者young代垃圾回收。
[PSYoungGen: 295648K->32968K(306432K)]提供了young代的空间信息,PSYoungGen表示young代的垃圾回收是使用throughput垃圾回收器。其他可能的young代垃圾回收有ParNew(使用CMS垃圾回收器多线程回收young代空间)、DefNew(使用serial垃圾回收器单线程回收young代空间)。
在“->”左边的数字(295648K)表示垃圾回收前young代的空间大小,右边数字(32968K)表示垃圾回收后的young代空间大小。young代被分为eden区域和survivor区域。由于在垃圾回收之后,eden区域是空的,右边的数字其实就是survivor区域的空间。在括号里面的数字(306432K)表示young代的总空间。
296198K->33518K(1006848K)提供了Java堆在垃圾回收前后的使用情况。另外,他提供Java堆的总大小,是young代和old代的和。在->左边的数字(296198K)表示,在垃圾回收前Java堆占用的空间,->右边的数字(33518K)表示垃圾回收后Java堆占用空间。括号里面的数字(1006848K)表示Java堆总共的空间。
通过young代的占用空间和Java堆占用的空间,可以快速的计算出old代占用的空间。比如:Java堆的大小是1006848K,young代的空间大小是306432K,因此可以计算出old代的空间大小是1006848K-306432K=700416K。在垃圾回收之前,296198K-295648K=550K是old代使用了的空间。在垃圾回收后33518K-32968K=550K。在这个例子中,在垃圾回收前后没有对象从young代移动到old代。这是一个重要的观察说明了Minor GC回收原则。如果有对象被移动到old代,然后变成不可读取的,就不是最大量的对象被回收,会违反Minor GC回收原则。
0.1083183 secs表明垃圾回收执行的时间。
[Times: user=1.83 sys=0.01, real=0.11 secs]提供了CPU和占用时间。user表明垃圾回收在用户模式下执行消耗的CPU时间,即:在JVM里面运行的时间,在这个例子中,垃圾回收器在用户模式下消耗1.83秒的CPU时间。sys表示操作系统代表垃圾回收器消耗的时间,在这里例子中,垃圾回收器使用0.01秒的操作系统CPU时间。real表示垃圾回收执行的时间的。这几个数字精确到0.01秒。
如果你对垃圾回收的实际时间感兴趣,可以设置-XX:+PrintGCDateStamps选项。-XX:+PrintGCDateStamps显示垃圾回收发生的年,月,日和时间。这个选项是在Java 6 Update 4引入的。下面的例子是同时使用-XX:+PrintGCDateStamps和-XX:+PrintGCDetails选项的结果:
2012-06-21T09:57:10.518-0500字段是使用了ISO 8601日期和时间戳。格式是YYYY-MM-DDTHH-MM-SS.mmm-TZ,分别的意思是:
YYYY表示4位数的年
MM表示2位数月,如果只有一位数,前面加0
DD表示2位数的天,如果只有一位数,前面加0
T是一个字符用来隔开日期和时间
HH表示2位数小时,如果只有一位数,前面加0
MM表示2位数分钟,如果只有一位数,前面加0
SS表示2位数秒,如果只有一位数,前面加0
mmm表示3位数毫秒,如果不足三位,前面加0或者00
TZ表示格林尼治时间的时区
尽管时区已经包含在输出里面了,但是输出日期和时间不是GMT时间,而是本地化过的时间。
当为了低延迟而优化HotSpot VM的时候,下面的两个选项是非常有用的,这两个选项会报告应用由于虚拟机的安全点(Safepoint)操作而阻塞的时间以及应用程序在安全点(Safepoint)执行了多长的时间。
安全点(Safepoint)操作会让JVM进入一种所有应用程序的线程都被阻塞以及阻止任何正在执行的本地程序把结果返回给Java代码的状态。当需要进行优化虚拟机内部操作的时候,安全点(Safepoint操作会被执行以使得所有线程都进入阻塞状态避免影响Java堆(垃圾回收是一种安全点(Safepoint操作)。
由于安全点(Safepoint)操作阻塞了所有Java程序的执行,所以知道程序的响应时间延迟是否和安全点(Safepoint)操作有关系就显得非常重要了。因此,能够观察程序什么时候被阻塞( 通过设置-XX:+PrintGCApplicationStoppedTime选项)通过应用的日志信息能够帮组你识别出,当应用的响应时间超过预期的时候,是安全点(Safepoint)操作引起的还是应用或者操作系统的其他操作引起的。-XX:+PrintSafepointStatistics可以帮助区别垃圾回收的安全点(Safepoint)以及其他的安全点(Safepoint)。
在发现应用的响应时间超过预期的预期的时候,-XX:+PrintGCApplicationConcurrentTime选项可以用来判断程序是否被执行以及执行了多长时间。
下图总结了前面提到的垃圾回收器的选项以及给出了使用它们的合适情况。
四:决定Java堆的大小以及内存占用
到目前为止,还没有做明确的优化工作。只是做了初始化选择工作,比如说:JVM部署模型、JVM运行环境、收集哪些垃圾回收器的信息以及需要遵守垃圾回收原则。这一步将介绍如何评估应用需要的内存大小以及Java堆大小。首先需要判断出应用存活的数据的大小,存活数据的大小是决定配置应用需要的Java堆大小的重要条件,也能够决定是否需要重新审视一下应用的内存需求或者修改应用程序以满足内存需求。 注意:存活数据是指,应用处于稳定运行状态下,在Java堆里面长期存活的对象。换一句话说,就是应用在稳定运行的状态下,Full GC之后,Java堆的所占的空间。
1、约束
有多少物理内存可以供JVM使用?是部署多个JVM或者单个JVM?对做出的决定有重要影响。下面列出了一些要点可以帮助决定有多少物理内存可以供使用。
1、一个机器上面只是部署一个JVM,且就一个应用使用?如果是这种情况,那么机器的所有物理内存可以供JVM使用。
2、一个机器上部署了多个JVM?或者一个机器上部署了多个应用?如果是这两个中的任何一种情况,你就必须要决定每一个JVM或者应用需要分配多少内存了。
无论是前面的哪种情况,都需要给操作系统留出一些内存。
2、HotSpot VM的堆结构
在做内存占用测量之前,我们必须要先理解HotSpot VM Java堆的结构,理解这个对决定应用需要的Java堆大小以及优化垃圾收器性能有很好的帮助。
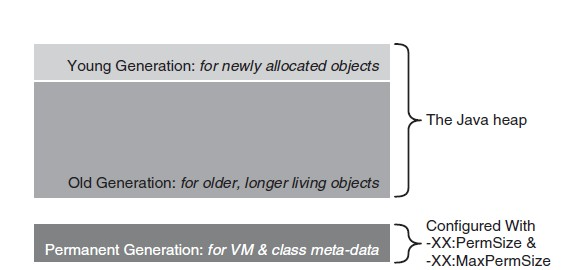
HotSpot VM有3个主要的空间:young代、old代以及permanent代,如上图所示。
当Java应用分配Java对象时,这些对象被分配到young代。在经历过几次minor GC之后,如果对象还是存活的,就会被转移到old代空间。permanent代空间存储了VM和Java类的元数据,比如内置的字符串和类的静态变量。
-Xmx和-Xms这个两个命令行选项分别指定yound代加上old代空间的总和的初始最大值和最小值,也就是Java堆的大小。当-Xms的值小于-Xmx的值的时候,Java堆的大小可以在最大值和最小值之前浮动。
当Java应用强调吞吐量和延迟的时候,倾向于把-Xms和-Xmx设置成相同的值,由于调整young代或者old代的大小都需要进行Full GC,Full GC降低吞吐量以及加强延迟。
young代的空间可以通过下面的任意一个命令行选项来设置:
young代的初始值和最小值。<n>是大小,[g|m|k]表示单位是G字节,M字节或者千字节。young代的大小不会小于这个值。当设定-XX:NewSize=<n>[g|m|k]的时候,-XX:MaxNewSize=<n>[g|m|k]需要被指定。
young区空间的最大值。同上面反过来,当指定-XX:MaxNewSize=<n>[g|m|k]的需要指定-XX:NewSize=<n>[g|m|k]。
直接指定young代的初始值、最小值以及最大值。也就是说,young区的大小被固定成这个值了。这个值用来锁定young代的大小很方便。
有一点需要注意的是,如果-Xms和-Xmx没有被设定成相同的值,而且-Xmn被使用了,当调整Java堆的大小的时候,不会调整young代的空间大小,young代的空间大小会保持恒定。因此,-Xmn应该在-Xms和-Xmx设定成相同的时候才指定。
old代的空间大小可以基于young代的大小进行计算,old代的初始值的大小是-Xms的值减去-XX:NewSize,最大值是-Xmx减去-XX:MaxNewSize,如果-Xmx和-Xms设置成了相同的值,而且使用-Xmn选项或者-XX:NewSize和-XX:MaxNewSize设置成了相同的值,那么old代的大小就是-Xmx减去-Xmn。
permanent代的大小通过下面命令行参数指定
表示permanent代的初始值和最小值,n表示数值,g|m|k表示单位、permanent的空间一定不会比这个空间小。
permanent代的最大值,permanent代的大小不会超过这个值。
Java应用应该指定这两个值成为同一个值,由于这个值的调整会导致Full GC。
如果上面提到的Java堆大小、young代、permanent代的大小都没有指定,那么JVM会根据应用的情况自行计算。
在young代、old代以及permanent代中任何一个空间里面无法分配对象的时候就会触发垃圾回收,理解这点,对后面的优化非常重要。当young代没有足够空间分配Java对象的时候,触发minor GC。minor GC相对于Full GC来说会更短暂。
一个对象在经历过一定次数的Minor GC之后,如果还存活,那么会被转移到old代(对象有一个“任期阀值”的概念,优化延迟的时候再介绍)。当old代没有足够空间放置对象的时候,HotSpot VM触发Full GC。实际上在进行Minor GC的时候发现没有old代足够的空间来进行对象的转移,就会触发Full GC,相对于在Minor GC的过程中发现对象的移动失败了然后触发Full GC,这样的策略会有更小的花费。当permanent代的空间不够用的时候的,也会触发Full GC。
如果Full GC是由于old代满了而触发的,old代和permanent代的空间都会被垃圾回收,即使permanent代的空间还没有满。同理,如果Full GC是由于permanent代满了而触发的,old代和permanent代的空间都会被垃圾回收,即使old代的空间还没有满。另外,young代同样会被垃圾回收,除非-XX:+ScavengeBeforeFullGC选项被指定了,-XX:+ScavengeBeforeFullGC关闭FullGC的时候young代的垃圾回收。
3、堆大小优化的起点
为了进行Java堆大小的优化,一个合适的起点很重要。这节描述的方案是需要先使用比应用需要量更大的Java堆作为开始。这一步的目的是收集一些初始化信息以及为了进一步优化Java堆大小需要的数据。
就像在“选择JVM runtime”小节里面提到过的,由吞吐量垃圾回收器(throughput garbage collector)开始。记住,使用吞吐量垃圾回收器通过设置-XX:+UserParallelOldGC命令行选项,如果你使用的HotSpot VM不支持的这个选项,那么就使用-XX:+UserParallelGC。
如果你能够准确的预估到应用需要消耗的Java堆空间,可以通过设定-Xmx和-Xms来作为这个步骤的起点。如果你不知道该设定什么值,就让JVM来选择吧,反正后面,都会根据实际情况进行优化调整。
关于如何监控GC日志前面的“GC优化基础”已经描述过了。GC日志会展示在使用中的java堆的大小。初始化和最大的堆大小可以通过-XX:+PrintCommandLineFlags来查看。-XX:+PrintCommandLineFlags打印出在HotSpot VM初始化的时候选择的初始值和最大值比如-XX:InitialHeapSize=<n> -XX:MaxHeapSize=<m>,这里n表示初始化的java堆大小值,m表示java堆的最大值。
不管你是指定java堆的大小还是使用默认的大小,必须让应用进入稳定运行的状态,你必须要有能力和手段让应用处于和线上稳定运行的状态相同的状态。
如果在企图让应用进入稳定状态的时候,你在垃圾回收日志里面观察到OutOfMemoryError,注意是old代溢出还是permanent代溢出。下面一个old代溢出的例子:
上面重要的部分加粗标红了,由于使用的是吞吐量垃圾回收器,old代的统计信息标示为ParOldGen。这行表示了old代的在Full GC的时候占用的空间。从这个结果来看,可以得出的结论是old代的空间太小了,由于Full GC前后old代的被占用的空间和分配的空间基本相等了,因此,JVM报了OutOfMemoryError。相比较,通过PSPermGen这行可以看出permanent代的空间占用是32390K,和他的容量(65536K)比还是有一定的距离。
下面的例子展示了由于permanent太少了而导致的OutOfMemoryError发生的例子:
同上面一样,上面重要的部分加粗标红了,通过PSPermGen这行可以看出在Full GC前后,他的空间占用量都和他的容量相同,可以得出的结论是permanent代的空间条小了,这样就导致了OutOfMemoryError。在这个例子里面,old的占用空间(132538K)远比他的容量(350208K)小。
如果在垃圾回收日志中观察到OutOfMemoryError,尝试把Java堆的大小扩大到物理内存的 80% ~ 90%。尤其需要注意的是堆空间导致的OutOfMemoryError以及一定要增加空间。比如说,增加-Xms和-Xmx的值来解决old代的OutOfMemoryError,增加-XX:PermSize和-XX:MaxPermSize来解决permanent代引起的OutOfMemoryError。记住一点Java堆能够使用的容量受限于硬件以及是否使用64位的JVM。在扩大了Java堆的大小之后,再检查垃圾回收日志,直到没有OutOfMemoryError为止。
如果应用运行在稳定状态下没有OutOfMemoryError就可以进入下一步了,计算活动对象的大小。
4、计算活动对象的大小
.png)
就像前面提到的,活动对象的大小是应用处于稳定运行状态时,长时间存活数据占用的Java堆的空间大小。换句话说,就是应用稳定运行是,在Full GC之后,old代和permanent代的空间大小。
活动对象的大小可以通过垃圾回收日志查看,它提供了一些优化信息,如下:
1、应用处于稳定运行状态下,old代的Java堆空间占用数量。
2、应用处于稳定运行状态下,permanent代的Java堆空间占用数量。
为了保证能够准确的评估应用的活动对象大小,最好的做法是多看几次Full GC之后Java堆空间的大小,保证FullGC是发生在应用处于稳定运行的状态。
如果应用没有发生FullGC或者发生FullGC的次数很少,在性能测试环境,可以通过Java监控工具来触发FullGC,比如使用VisualVM和JConsole,这些工具在最新的JDK的bin目录下可以找到,VisualVM集成了JConsole,VisualVM或者JConsole上面有一个触发GC的按钮。
另外,jmap命令可以选择来强制HotSpot VM进行FullGC。jmap 需要-histo:live命令选项以及JVM进程id。JVM的进程id可以通过jps命令获取。比如JVM的进程id是348,jmap命令用来触发FullGC可以想如下这样写:
jmap不仅仅触发FullGC,而且产生堆的关于对象分配的概要信息。不过就目前这步的目的而言,可以忽略产生的堆概要信息。
5、初始化堆大小配置
本节描述了怎样利用活动对象的大小来决定初始化的Java堆的大小。下面的图,给出了应用存活的对象的大小。比较明智的做法是多收集几次Full GC信息,有更多的信息,能够做出更加好的决定。
通过活动对象大小的信息,可以做出关于Java堆的大小有根据的决定,以及可以估计出最坏情况下会导致的延迟。
比较常规是,Java堆大小的初始化值和最大值(通过-Xms和-Xmx选项来指定)应该是old代活动对象的大小的3到4倍。
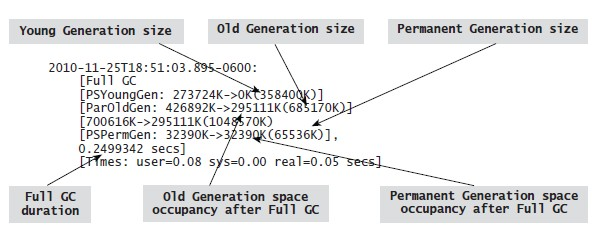
在上图中显示的FullGC信息中,在FullGC之后old代的大小是295111K,差不多是295M,即活动的对象的大小是295M。因此,推荐的Java堆的初始化和最大值应该是885M到1180M,即可以设置为-Xms885m -Xmx1180m。在这个例子中,Java堆的大小是1048570K差不多1048M,在推荐值范围内。
另外一个常规是,permanent的初始值和最大值(-XX:PermSize和-XX:MaxPermSize)应该permanent代活动对象大小的1.2到1.5倍。在上图中看到在FullGC之后permanent代占用空间是32390K,差不多32M。因此,permanent代的推荐大小是38M到48M,即可以设置为-XX:PermSize=48m -XX:MaxPermSize=48m(1.5倍)。这个例子里面,permanent代的空间大小是65536K即64M,大出了17M,不过在1G内存的系统的中,这个数值完全可以忍受。
另外一个常规是,young代空间应该是old代活动对象大小的1到1.5倍。那么在这里例子中,young代的大小可以设置为295M到442M。本例里面,young代的空间大小的358400K,差不多358M,在推荐值中间。
如果推荐的Java堆的初始值和最大值是活动对象大小3到4倍,而young代的推荐只是1到1.5倍,那么old代空间大小应该是2到3倍。
通过以上规则,我们可以使用的Java命令可以是这样的:
6、另外一些考虑
本节将提及到在进行应用内存占用评估的时候,另外一些需要记住的点。首先,必须要知道,前面只是评估的Java堆的大小,而不是Java应用占用的所有的内存,如果要查看Java应用占用的所有内存在linux下可以通过top命令查看或者在window下面通过任务管理器来查看,尽管Java堆的大小可能对Java应用占用内存做出了最大的贡献。 比如说,为了存储线程堆栈,应用需要额外的内存,越多的线程,越多内存被线程栈消耗,越深的方法间调用,线程栈越多。另外,本地库需要分配额外的内存,I/O缓存也需要额外的内存。应用的内存消耗需要评估到应用任何一个会消耗内存的地方。
记住,这一步操作不一定能够满足应用内存消耗的需求,如果不能满足,就回过头来看需求是否合理或者修改应用程序。比较可行的一种办法是修改应用程序减小对象的分配,从而减少内存的消耗。
Java堆的大小计算仅仅只是开始,根据需求,在后面的优化步骤中可能会修改。
五:优化延迟或者响应时间(1)
本节的目标是做一些优化以满足对应用对延迟的需求。这次需要几个步骤,包括完善Java堆大小的配置,评估垃圾回收占用的时间和频率,也许还要尝试切换到不同的垃圾回收器,以及由于使用了不同的垃圾回收器,需要重新优化Java堆空间大小。
这一步有如下可能的结果:
1、应用的延迟需求被满足了。如果这一步的优化操作满足了应用的延迟需求,你可以继续下一步优化(优化吞吐量)。
2、应用的延迟需求未被满足。如果这一步的优化操作未能满足延迟需求,你可能需要重新看看延迟需求是否合理或者修改应用程序。一些可能的问题可以帮助改善应用的延迟问题:
a、优化Java堆以及修改应用以减少对象的分配和对象的长时间存活。
b、修改JVM的部署结构,让每一个JVM做更少的工作。
上面的两个步骤都可以减少JVM的对象分配,因此减少垃圾回收的频率。
这一步从查看垃圾回收对应用的延迟的影响开始,基于前面一节“决定内存消耗”计算出来的Java堆大小。
下面列出了评估垃圾回收对延迟的影响需要进行的几个事情:
1、测量Minor GC的时间。
2、测量Minor GC的频率。
3、测量Full GC的时间。
4、测量Full GC的频率。
测量垃圾回收的时间和频率对于改善Java堆大小配置来说是非常重要的。Minor GC的时间和频率的测量结果可以用来改善young代的空间大小。测量最坏情况下FullGC的时间和频率可以用来决定old代的大小,以及是否需要切换成吞吐量垃圾回收器(通过使用-XX:+UseParalleOldGC或者-XX:+UseParallelGC)或者并发垃圾回收器(CMS,通过使用-XX:+UseConcMarkSweepGC)。在使用吞吐量垃圾回收器的时候,如果垃圾回收的延迟和频率太高以导致应用的延迟需求无法满足的时候才切换到CMS,如果选择了切换,需要对CMS垃圾回收器进行优化,后面会详细介绍这个问题。
接下来详细介绍前面提到的各种情况。
需求
下面列举了几个这一步优化操作需求,它们来源于应用的系统需求:
1、可以接收的平均暂停时间。平均暂停时间需求用于和Minor GC消耗的时间比较。
2、可以接收的Minor GC的频率。其实频道对于应用负责人来说,没有平均延迟时间重要。
3、应用负责人能够接受的最大延迟时间。这个时间受到Full GC的影响。
4、应用负责人能够接收的最大延迟的频率,即Full GC的频率。其实,大多数时间应用管理员还是更加关心应用的的最大延迟时间超过了最大延迟的频率。
一旦确定了需求,这些垃圾回收器的时间消耗和频率都可以通过垃圾回收日志收集到。先把垃圾回收器设置为吞吐量垃圾回收器(设置-XX:+UseParallelOldeGC或者-XX:+UseParallelGC)。通过反复测试,可以让young代和old代满足上面的要求。下面2节介绍如何优化young代和old代空间大小来观察Minor GC和最坏情况的Full GC的消耗时间和频率。
改善young代的大小
确定young代的大小是通过评估垃圾回收的统计信息以及观察Minor GC的消耗时间和频率,下面举例说明如何通过垃圾回收的统计信息来确定young代的大小。
尽管Minor GC消耗的时间和young代里面的存活的对象数量有直接关系,但是一般情况下,更小young代空间,更短的Minor GC时间。如果不考虑MinorGC的时间消耗,减少young代的大小会导致Minor GC变得更加频繁,由于更小的空间,用玩空间会用更少的时间。同理,提高young代的大小会降低MinorGC的频率。
当测试垃圾回收数据的时候,发现MinorGC的时间太长了,正确的做法就是减少young代的空间大小。如果MinorGC太频繁了就增加young代的空间大小。
上图是一个展示了MinorGC的例子,这个例子是运行在如下的HotSpot VM命令参数下的。
上图显示了Minor GC平均的消耗时间是0.05秒,平均的频率是2.147秒1次。当计算Minor GC的消耗时间和频率的时候,越多的数据参与计算,准确性会越高。并且应用要处于稳定运行状态下来收集Minor GC信息也是非常重要的。
下一步是比较MinorGC的平均时间和系统对延迟的要求,如果MinorGC的平均时间大于了系统的要求,减少young代的空间大小,然后继续测试,再收集数据以及重新评估。
如果MinorGC的频率大于了系统的要求,就增加young代的空间大小,然后继续测试,再收集以及重新评估。
也许需要数次重复才能够让系统达到延迟要求。当你改变young代的空间大小的时候,尽量保持old代的空间大小不要改变。
从上图的垃圾回收信息来看,如果应用的延迟要求是40毫秒的话,观察到的MinorGC的延迟是58毫秒,比系统的要求高出了不少。上面例子使用的命令选项是
意味着old代的空间大小是4096M,减小young代的空间大小的10%而且要保持old代的空间大小不变,可以使用如下选项。
注意的是young代的空间大小从2048M减少到1844M,整个Java堆的大小从6144M减少到5940M,两者都是减少了204m。
无论是young的空间调大还是调小,都需要重新收集垃圾回收信息和重新计算MinorGC的平均时间和频率,以达到应用的延迟要求,可能需要几个轮回来达到这个要求。
为了说明了增加young代的大小以降低MinorGC的频率,我们下面举一个例子。如果系统要求的频率是5秒一次,这个上面的例子中是2.147秒一次,也就是说它用了2.147秒,填充满了2048M空间,如果需要5秒一次的频率,那么就需要5/2.147倍的空间,即2048*5/2.147等于4700M。因此young代的空间需要调整到4700M。下面是一个示例来说明配置这个:
注意是-Xms和-Xmx也同步调整了。
另外一些调整young代的空间需要注意的事项:
1、old代的空间一定不能小于活动对象的大小的1.5倍。
2、young代的空间至少要有Java堆大小的10%,太小的Java空间会导致过于频繁的MinorGC。
3、当提高Java堆大小的时候,不要超过JVM可以使用的物理内存大小。如果使用过多的物理内存,会导致使用交换区,这个会严重影响性能。
如果在仅仅是MinorGC导致了延迟的情况下,你无法通过调整young代的空间来满足系统的需求,那么你需要重 新修改应用程序、修改JVM部署模型把应用部署到多个JVM上面(通常得要多机器了)或者重新评估系统的需求。
如果通过调整MinorGC能够满足应用的延迟需求,接下来就可以调整old代了,以达到最坏情况下的延迟和延迟频率的需求。下一节详细说明这个问题。
完善old代的大小
这一节的目标是评估由于Full GC引起的最差暂停时间和频率。
同前面一个节“完善young代大小”一样,垃圾回收的统计信息是必须的,在稳定状态下,Full GC的时间表明了应用最差的延迟,如果发生了多个Full GC,计算多个Full GC的平均消耗时间,更多数据能够更好的评估。
计算两次不同的FullGC之间的时间差,可以提供出FullGC的频率,下图用一个列子来说明两个FullGC:
如果没有FullGC,可以人为的去干预,前面说过,可以使用VisualVM来触发FullGC。另外,评估FullGC的频率需要知道对象的转移率,这个转移率说明对象从young代转移到old代。接下来的介绍如何评估转移率。
接下有个几个MinorGC的例子,他们被用来评估FullGC的频率。
从上面的例子可以看出:
1、Java堆的大小是6291456K或6144M
2、young代的大小是2097152K或2048M
3、old代的大小是6144M-2048M = 4096M
在这个例子中,活动对象的大小差不多是1370M。那么old代还有2726M剩余空间(4096M-1370M=2726M)。
填充完成2736M空间需要多长时间是由young代向old代的转移率决定的。这个转移率的计算通过查看每次MinorGC后old代的占用空间的增长情况以及MinorGC发生的时间。old代的空间占用是MinorGC之后Java堆中对象大小减去young代的大小,通过这个公式计算,可以看出在这个例子中每次MinorGC之后,old代的空间占用情况是:
1588635K,第一个MinorGC
1611428K,第二次MinorGC
1632106K,第三次MinorGC
1653117K,第四次MinorGC
每次的增量分别是
22793K,第一次和第二次的增量
20678K,第二次和第三次的增量
21011K,第三次和第四次的增量
平均每次MinorGC转移大概201494K或者叫21M。
如果剩余的空间都是按照设个转移率来转移到old代的话,且知道MinorGC的频率是每2.147秒一次。因此,这个转移率是201494K/2.147s差不多10M/s,那么一共的空间是2736M空间需要273.6s差不多4.5分钟一次。
因此,通过前面的案例分析,应用的最差延迟的频率是4.5分钟。这个评估可以通过让应用处于稳定运行状态超过4.5分钟来验证。
如果评估和观察的FullGC的频率高于了应用对最坏延迟频率的要求,那么可以提高old代的空间大小。如果改变old代的大小,保持young代的空间恒定,在优化young代的时候也说这个问题,两者应该独立优化,以保证有高效。
如果这步已经达到了你最坏延迟的要求,那么这一步调优延迟就算已经完成了,就可以进入下一步去调优“吞吐量”了。
如果你未能达到了应用对最坏延迟时间和频率的性能要求,由于FullGC的执行时间太长了,然后你可以把垃圾回收器切换CMS(concurrent garbage collection)。CMS有能力让垃圾回收尽量是多线程的,即让程序保持在运行状态。要使用CMS可以通过下面这条命令选项:-XX:+UseConcMarkSweepGC。
后面详细说明如何调优CMS。
五:优化延迟或者响应时间(2)
优化CMS(concurrent garbage collection)
使用CMS,old代的垃圾回收执行线程会和应用程序的线程最大程度的并发执行。这个提供了一个机会来减少最坏延迟的频率和最坏延迟的时间消耗。CMS没有执行压缩,所以可以避免old代空间的stop-the-world压缩(会让整个应用暂停运行)。
优化CMS的目标就是避开stop-the-world压缩垃圾回收,然而,这个说比做起来容易。在一些的部署情况下,这个是不可避免的,尤其是当内存分配受限的时候。
在一些特殊的情况下,CMS比其他类型的垃圾回收需要更多优化,更需要优化young代的空间,以及潜在的优化该什么时候初始化old代的垃圾回收循环。
当从吞吐量垃圾回收器(Throughput)迁移到CMS的时候,有可能会获得更慢的MinorGC,由于对象从young代转移到old会更慢 ,由于CMS在old代里面分配的内存是一个不连续的列表,相反,吞吐量垃圾回收器只是在本地线程的分配缓存里面指定一个指针。另外,由于old代的垃圾回收线程和应用的线程是尽可能的并发运行的,所以吞吐量会更小一些。然而,最坏的延迟的频率会少很多,由于在old代的不可获取的对象能够在应用运行的过程被垃圾回收,这样可以避免old代的空间溢出。
使用CMS,如果old代能够使用的空间有限,单线程的stop-the-world压缩垃圾回收会执行。这种情况下,FullGC的时间会比吞吐量垃圾回收器的FullGC时间还要长,导致的结果是,CMS的绝对最差延迟会比吞吐量垃圾回收器的最差延迟严重很多。old代的空间溢出以及运行了stop-the-world垃圾回收必须被应用负责人重视,由于在响应上会有更长的中断。因此,不要让old代运行得溢出就非常重要了。对于从吞吐量垃圾回收器迁移到CMS的一个比较重要的建议就是提升old代20%到30%的容量。
在优化CMS的时候有几个注意点,首先,对象从young代转移到old代的转移率。其次,CMS重新分配内存的概率。再次,CMS回收对象时候产生的old代的分隔,这个会在可获得的对象中间产生一些空隙,从而导致了分隔空间。
碎片可以被下面的几种方法寻址。第一办法是压缩old代,压缩old代空间是通过stop-the-world垃圾回收压缩完成的,就像前面所说的那样,stop-the-world垃圾回收会执行很长时间,会严重影响应用的响应时间,应该避开。第二种办法是,对碎片编址,提高old代的空间,这个办法不能完全解决碎片的问题的,但是可以延迟old代压缩的时间。通常来讲,old代越多内存,由于碎片导致需要执行的压缩的时间久越长。努力把old的空间增大的目标是在应用的生命周期中,避免堆碎片导致stop-the-world压缩垃圾回收,换句话说,应用GC最大内存原则。另外一种处理碎片的办法是减少对象从young代移动到old的概率,就是减少MinorGC,应用MinorGC回收原则。
任期阀值(tenuring threshold)控制了对象该什么时候从young代移动到old代。任期阀值会在后面详细的介绍,它是HotSpot VM基于young代的占用空间来计算的,尤其是survivor(幸存者)空间的占用量。下面详细介绍一下survivor空间以及讨论任期阀值。
survivor空间
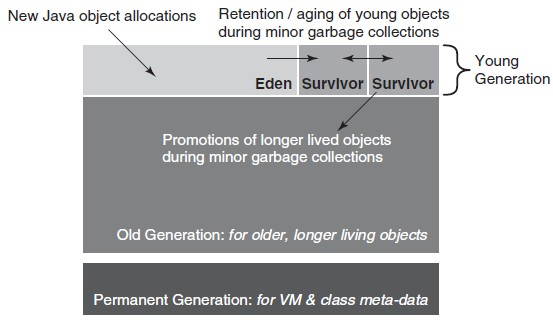
survivor空间是young代的一部分,如下图所示。young代被分成了一个eden区域和两个survivor空间。
两个survivor空间的中一个被标记为“from”,另外一个标记为“to”。新的Java对象被分配到Eden空间。比如说,下面的一条语句:
一个新的HashMap对象会被放到eden空间,当eden空间满了的时候,MinorGC就会执行,任何存活的对象,都从eden空间复制到“to” survivor空间,任何在“from” survivor空间里面的存活对象也会被复制到“to” survivor。MinorGC结束的时候,eden空间和“from” survivor空间都是空的,“to” survivor空间里面存储存活的对象,然后,在下次MinorGC的时候,两个survivor空间交换他们的标签,现在是空的“from” survivor标记成为“to”,“to” survivor标记为“from”。因此,在MinorGC结束的时候,eden空间是空的,两个survivor空间中的一个是空的。
在MinorGC过程,如果“to” survivor空间不够大,不能够存储所有的从eden空间和from suvivor空间复制过来活动对象,溢出的对象会被复制到old代。溢出迁移到old代,会导致old代的空间快速增长,会导致stop-the-world压缩垃圾回收,所以,这里要使用MinorGC回收原则。
避免survivor空间溢出可以通过指定survivor空间的大小来实现,以使得survivor有足够的空间来让对象存活足够的岁数。高效的岁数控制会导致只有长时间存活的对象转移到old代空间。
岁数控制是指一个对象保持在young代里面直到无法获取,所以让old代只是存储长时间保存的对象。
survivor的空间可以大小设置可以用HotSpot命令行参数:-XX:SurvivorRatio=<ratio>
<ratio>必须是以一个大于0的值,-XX:SurvivorRatio=<ratio>表示了每一个survivor的空间和eden空间的比值。下面这个公式可以用来计算survivor空间的大小
这里有一个+2的理由是有两个survivor空间,是一个调节参数。ratio设置的越大,survivor的空间越小。为了说明这个问题,假设young代的大小是-Xmn512m而且-XX:SurvivorRatio=6.那么,young代有两个survivor空间且空间大小是64M,那么eden空间的大小是384M。
同样假如young代的大小是512M,但是修改-XX:SurvivorRatio=2,这样的配置会使得每一个survivor空间的大小是128m而eden空间的大小是256M。
对于一个给定大小young代空间大小,减小ratio参数增加survivor空间的大小而且减少eden空间的大小。反之,增加ratio会导致survivor空间减少而且eden空间增大。减少eden空间会导致MinorGC更加频繁,相反,增加eden空间的大小会导致更小的MinorGC,越多的MinorGC,对象的岁数增长得越快。
为了更好的优化survivor空间的大小和完善young代空间的大小,需要监控任期阀值,任期阀值决定了对象会再young代保存多久。怎么样来监控和优化任期阀值将在下一节中介绍。
任期阀值
“任期”是转移的代名词,换句话说,任期阀值意味着对象移动到old代空间里面。HotSpot VM每次MinorGC的时候都会计算任期,以决定对象是否需要移动到old代去。任期阀值就是对象的岁数。对象的岁数是指他存活过的MinorGC次数。当一个对象被分配的时候,它的岁数是0。在下次MinorGC的时候之后,如果对象还是存活在young代里面,它的岁数就是1。如果再经历过一次MinorGC,它的岁数变成2,依此类推。在young代里面的岁数超过HotSpot VM指定阀值的对象会被移动到old代里面。换句话说,任期阀值决定对象在young代里面保存多久。
任期阀值的计算依赖于young代里面能够存放的对象数以及MinorGC之后,“to” servivor的空间占用。HotSpot VM有一个选项-XX:MaxTenuringThreshold=<n>,可以用来指定当时对象的岁数超过<n>的时候,HotSpot VM会把对象移动到old代去。内部计算的任期阀值一定不会超过指定的最大任期阀值。最大任期阀值在可以被设定为0-15,不过在Java 5 update 5之前可以设置为1-31。
不推荐把最大任期阀值设定成0或者超过15,这样会导致GC的低效率。
如果HotSpot VM它无法保持目标survivor 空间的占用量,它会使用一个小于最大值的任期阀值来维持目标survivor空间的占用量,任何比这个任期阀值的大的对象都会被移动到old代。话句话说,当存活对象的量大于目标survivor空间能够接受的量的时候,溢出发生了,溢出会导致对象快速的移动到old代,导致不期望的FullGC。甚至会导致更频繁的stop-the-world压缩垃圾回收。哪些对象会被移动到old代是根据评估对象的岁数和任期阀值来确定的。因此,很有必要监控任期阀值以避免survivor空间溢出,接下来详细讨论。
监控任期阀值
为了不被内部计算的任期阀值迷惑,我们可以使用命令选项-XX:MaxTenuringThreshod=<n>来指定最大的任期阀值。为了决定出最大的任期阀值,需要监控任期阀值的分布和对象岁数的分布,通过使用下面的选项实现
-XX:+PrintTenuringDistribution的输出显示在survivor空间里面有效的对象的岁数情况。阅读-XX:+PrintTenuringDistribution输出的方式是观察在每一个岁数上面,对象的存活的数量,以及其增减情况,以及HotSpot VM计算的任期阀值是不是等于或者近似于设定的最大任期阀值。
-XX:+PrintTenuringDistribution在MinorGC的时候产生任期分布信息。它可以同其他选项一同使用,比如-XX:+PrintGCDateStamps,-XX:+PrintGCTimeStamps以及-XX:+PringGCDetails。当调整survivor空间大小以获得有效的对象岁数分布,你应该使用-XX:+PrintTenuringDistribution。在生产环境中,它同样非常有用,可以用来判断stop-the-world的垃圾回收是否发生。
下面是一个输出的例子:
Desired survivor size 8388608 bytes, new threshold 1 (max 15)
- age 1: 16690480 bytes, 16690480 total
在这里例子中,最大任期阀值被设置为15,(通过max 15表示)。内部计算出来的任期阀值是1,通过threshold 1表示。Desired survivor size 8388608 bytes表示一个survivor的空间大小。目标survivor的占有率是指目标survivor和两个survivor空间总和的比值。怎么样指定期望的survivor空间大小在后面会详细介绍。在第一行下面,会列出一个对象的岁数列表。每行会列出每一个岁数的字节数,在这个例子中,岁数是1的对象有16690480字节,而且每行后面有一个总的字节数,如果有多行输出的话,总字节数是前面的每行的累加数。后面举例说明。
在前面的例子中,由于期望的survivor大小(8388608)比实际总共survivor字节数(16690480)小,也就是说,survivor空间溢出了,这次MinorGC会有一些对象移动到old代。这个就意味着survivor的空间太小了。另外,设定的最大任期阀值是15,但是实际上JVM使用的是1,也表明了survivor的空间太小了。
如果发现survivor区域太小,就增大survivor的空间,下面详细介绍如何操作。
设定survivor空间
当修改survivor空间的大小的时候,有一点需要记住。当修改survivor空间大小的时候,如果young代的大小不改变,那么eden空间会减小,进一步会导致更频繁的MinorGC。因此,增加survivor空间的时候,如果young代的空间大小违背了MinorGC频率的需求,eden空间的大小同需要需要增加。换句话说,当survivor空间增加的时候,young代的大小需要增加。
如果有空间来增加MinorGC的频率,有两种选择,一是拿一些eden空间来增加survivor的空间,二是让young的空间更大一些。常规来讲,更好的选择是如果有可以使用的内存,增加young代的空间会比减少eden的空间更好一些。让eden空间大小保持恒定,MinorGC的频率不会改变,即使调整survivor空间的大小。
使用-XX:+PrintTenuringDistribution选项,对象的总字节数和目标survivor空间占用可以用来计算survivor空间的大小。重复前面的例子:
Desired survivor size 8388608 bytes, new threshold 1 (max 15)
- age 1: 16690480 bytes, 16690480 total
存活对象的总字节数是1669048,这个并发垃圾回收器(CMS)的目标survivor默认使用50%的survivor空间。通过这个信息,我们可以知道survivor空间至少应该是33380960字节,大概是32M。这个计算让我们知道对survivor空间的预估值需要计算对象的岁数更高效以及防止溢出。为了更好的预估survivor的可用空间,你应该监控应用稳定运行情况下的任期分布,并且使用所有的额外总存活对象的字节数来作为survivor空间的大小。
在这个例子,为了让应用计算岁数更加有效,survivor空间需要至少提升32M。前面使用的选项是:
那么为了保持MinorGC的频率不发生变化,然后增加survivor空间的大小到32M,那么修改后的选项如下:
当时young代空间增加了,eden空间的大小保持大概相同,且survivor的空间大小增减了。需要注意的时候,-Xmx、-Xms、-Xmn都增加了32m。另外,-XX:SurvivvorRatio=15让每一个survivor空间的大小都是32m (544/(15+2) = 32)。
如果存在不能增加young代空间大小的限制,那么增加survivor空间大小需要以减少eden空间的大小为代价。下面是一个增加survivor空间大小,每一个survivor空间从16m增减加到32m,那么会见减少eden的空间,从480m减少到448m(512-32-32=448,512-16-16=480)。
再次强调,减少eden空间大小会增加MinorGC的频率。但是,对象会在young代里面保持更长的时间,由于提升survivor的空间。
假如运行同样的应用,我们保持eden的空间不变,增加survivor空间的大小,如下面选项:
可以产生如下的任期分布:
Desired survivor size 16777216 bytes, new threshold 15 (max 15)- age 1: 6115072 bytes, 6115072 total
- age 2: 286672 bytes, 6401744 total
- age 3: 115704 bytes, 6517448 total
- age 4: 95932 bytes, 6613380 total
- age 5: 89465 bytes, 6702845 total
- age 6: 88322 bytes, 6791167 total
- age 7: 88201 bytes, 6879368 total
- age 8: 88176 bytes, 6967544 total
- age 9: 88176 bytes, 7055720 total
- age 10: 88176 bytes, 7143896 total
- age 11: 88176 bytes, 7232072 total
- age 12: 88176 bytes, 7320248 total
从任期分布的情况来看,survivor空间没有溢出,由于存活的总大小是7320248,但是预期的survivor空间大小是16777216以及任期阀值和最大任期阀值是相等的。这个表明,对象的老化速度是高效的,而且survivor空间没有溢出。
在这个例子中,由于岁数超过3的对象很少,你可能像把最大任期阀值设置为3来测试一下,即设置选项-XX:MaxTenuringThreshhold=3,那么整个选项可以设置为:
这个选项设置和之前的选项设置的权衡是,后面这个选择可以避免在MinorGC的时候不必要地把对象从“from” survivor复制到“to” survivor。在应用运行在稳定状态的情况下,观察多次MinorGC任期分布情况,看是否有对象最终移动到old代或者显示的结果还是和前面的结果类似。如果你观察得到和前面的任期分布情况相同,基本没有对象的岁数达到15,也没有survivor的空间溢出,你应该自己设置最大任期阀值以代替JVM默认的15。在这个例子中,没有长时间存活的对象,由于在他们的岁数没有到达15的时候就被垃圾回收了。这些对象在MinorGC中被回收了,而不是移动到old代里面。使用并发垃圾回收(CMS)的时候,对象从young代移动到old代最终会导致old的碎片增加,有可能导致stop-the-world压缩垃圾回收,这些都是不希望出现的。宁可选择让对象在“from” survivor和“to” survivor中复制,也不要太快的移动到old代。
你可能需要重复数次监控任期分布、修改survivor空间大小或者重新配置young代的空间大小直到你对应用由于MinorGC引起的延迟满意为止。如果你发现MinorGC的时间太长,你可以通过减少young代的大小直到你满意为止。尽管,减少young代的大小,会导致更快地移动对象到old代,可能导致更多的碎片,如果CMS的并发垃圾回收能够跟上对象的转移率,这种情况就比不能满足应用的延迟需求更好。如果这步不能满足应用的MinorGC的延迟和频率需求,这个时候就有必要重新审视需求以及修改应用程序了。
如果满足对MinorGC延迟的需求,包括延迟时间和延迟频率,你可以进入下一步,优化CMS垃圾回收周期的启动,下节详细介绍。五:优化延迟或者响应时间(3)
CMS垃圾回收器周期
一旦young的空间大小(包含eden和survivor空间)已经完善得满足应用对MinorGC产生延迟要求,注意力可以转移到优化CMS垃圾回收器,降低最差延迟时间的时间长度以及最小化最差延迟的频率。目标是保持可用的old代空间和并发垃圾回收,避免stop-the-world压缩垃圾回收。
stop-the-world压缩垃圾回收是垃圾回收影响延迟的最差情况,对某些应用来说,恐怕无法完全避免开这些,但是本节提供的优化信息至少可以减少他们的频率。
成功的优化CMS垃圾回收器需要达到的效果是old代的里面的垃圾回收的效率要和young代转移对象到old代的效率相同,没有能够完成这个标准可以称为“比赛失败”,比赛失败的结果就是导致stop-the-world压缩垃圾回收。不比赛中失败的一个关键是让下面两个事情结合起来:1、old代有足够的空间。2、启动CMS垃圾回收周期开始时机——快到回收对象的速度比较转移对象来的速度更快。
CMS周期的启动是基于old代的空间大小的。如果CMS周期开始的太晚,他就会输掉比赛,没有能够快速的回收对象以避免溢出old代空间。如果CMS周期开始得太早,会造成不必要的压力以及影响应用的吞吐量。但是,通常来讲过早的启动总比过晚的启动好。
HotSpot VM自动地计算出当占用是多少时启动CMS垃圾回收周期。不过在一些场景下,对于避免stop-the-world垃圾回收,他做得并不好。如果观察到stop-the-world垃圾回收,你可以优化该什么时候启动CMS周期。在CMS垃圾回收中,stop-the-world压缩垃圾回收在垃圾回收日志中输出是“concurrent mode failure”,下面一个例子:
174.445: [GC 174.446: [ParNew: 66408K->66408K(66416K), 0.0000618
secs]174.446: [CMS ( concurrent mode failure): 161928K->162118K(175104K),
4.0975124 secs] 228336K->162118K(241520K)
如果你发现有concurrent mode failure你可以通过下面这个选项来控制什么时候启动CMS垃圾回收:
这个值指定了CMS垃圾回收时old代的空间占用率该是什么值。举例说明,如果你希望old代占用率是65%的时候,启动CMS垃圾回收,你可以设置-XX:CMSInitiatingOccupancyFraction=65。另外一个可以同时使用的选项是
-XX:+UseCMSInitiatingOccupancyOnly指定HotSpot VM总是使用-XX:CMSInitiatingOccupancyFraction的值作为old的空间使用率限制来启动CMS垃圾回收。如果没有使用-XX:+UseCMSInitiatingOccupancyOnly,那么HotSpot VM只是利用这个值来启动第一次CMS垃圾回收,后面都是使用HotSpot VM自动计算出来的值。
-XX:CMSInitiatingOccupancyFraction=<percent>这个指定的值,应该比垃圾回收之后存活对象的占用率更高,怎么样计算存活对象的大小前面在“决定内存占用”的章节已经说过了。如果<percent>不比存活对象的占用量大,CMS垃圾回收器会一直运行。通常的建议是-XX:CMSInitiatingOccupancyFraction的值应该是存活对象的占用率的1.5倍。举例说明一下,假如用下面的Java堆选项配置:
那么old代的空间大小是1024M(1536-512 = 1024m)。如果存活对象的大小是350M的话,CMS垃圾回收周期的启动阀值应该是old代占用空间是525M,那么占用率就应该是51%(525/1024=51%),这个只是初始值,后面还可能根据垃圾回收日志进行修改。那么修改后的命令行选项是:
该多早或者多迟启动CMS周期依赖于对象从young代转移到old代的速率,也就是说,old代空间的增长率。如果old代填充速度比较缓慢,你可以晚一些启动CMS周期,如果填充速度很快,那么就需要早一点启动CMS周期,但是不能小于存活对象的占用率。如果需要设置得比存活对象的占用率小,应该是增加old代的空间。
想知道CMS周期是开始的太早还是太晚,可以通过评估垃圾回收信息识别出来。下面是一个CMS周期开始得太晚的例子。为了更好阅读,稍微修改了输出内容:
注意FullGC在CMS-inital-mark之后很快就发生了。CMS-initial-mark是报告CMS周期多个字段中的一个。下面的例子会使用到更多的字段。[ParNew 742993K->648506K(773376K), 0.1688876 secs][ParNew 753466K->659042K(773376K), 0.1695921 secs][CMS-initial-mark 661142K(773376K), 0.0861029 secs][Full GC 645986K->234335K(655360K), 8.9112629 secs][ParNew 339295K->247490K(773376K), 0.0230993 secs][ParNew 352450K->259959K(773376K), 0.1933945 secs]
下面是一个CMS开始的太早了的情况:
[ParNew 390868K->296358K(773376K), 0.1882258 secs][CMS-initial-mark 298458K(773376K), 0.0847541 secs][ParNew 401318K->306863K(773376K), 0.1933159 secs][CMS-concurrent-mark: 0.787/0.981 secs][CMS-concurrent-preclean: 0.149/0.152 secs][CMS-concurrent-abortable-preclean: 0.105/0.183 secs][CMS-remark 374049K(773376K), 0.0353394 secs][ParNew 407285K->312829K(773376K), 0.1969370 secs][ParNew 405554K->311100K(773376K), 0.1922082 secs][ParNew 404913K->310361K(773376K), 0.1909849 secs][ParNew 406005K->311878K(773376K), 0.2012884 secs][CMS-concurrent-sweep: 2.179/2.963 secs][CMS-concurrent-reset: 0.010/0.010 secs][ParNew 387767K->292925K(773376K), 0.1843175 secs][CMS-initial-mark 295026K(773376K), 0.0865858 secs][ParNew 397885K->303822K(773376K), 0.1995878 secs]
CMS-initial-mark表示CMS周期的开始, CMS-initial-sweep和CMS-concurrent-reset表示周期的结束。注意第一个CMS-initial-mark报告堆大小是298458K,然后注意,ParNew MinorGC报告在CMS-initial-mark和CMS-concurrent-reset之间只有很少的占用量变化,堆的占用量可以通过ParNew的->的右边的数值来表示。在这个例子中,CMS周期回收了很少的垃圾,通过在CMS-initial-mark和CMS-concurrent-reset之间只有很少的占用量变化可看出来。这里正确的做法是启动CMS周期用更大的old代空间占用率,通过使用参数
-XX:+UseCMSInitiatingOccupancyOnly和-XX:CMSInitiatingOccupancyFraction=<percent>。基于初始(CMS-initial-mark)占用量是298458K以及Java堆的大小是773376K,就是CMS发生的占用率是35%到40%(298458K/773376K=38.5%),可以使用选项来强制提高占用率的值。
下面是一个CMS周期回收了大量old代空间的例子,而且没有经历stop-the-world压缩垃圾回收,也就没有并发错误(concurrent mode failure)。同样的修改输出格式:
[ParNew 640710K->546360K(773376K), 0.1839508 secs][CMS-initial-mark 548460K(773376K), 0.0883685 secs][ParNew 651320K->556690K(773376K), 0.2052309 secs][CMS-concurrent-mark: 0.832/1.038 secs][CMS-concurrent-preclean: 0.146/0.151 secs][CMS-concurrent-abortable-preclean: 0.181/0.181 secs][CMS-remark 623877K(773376K), 0.0328863 secs][ParNew 655656K->561336K(773376K), 0.2088224 secs][ParNew 648882K->554390K(773376K), 0.2053158 secs][ParNew 489586K->395012K(773376K), 0.2050494 secs][ParNew 463096K->368901K(773376K), 0.2137257 secs][CMS-concurrent-sweep: 4.873/6.745 secs][CMS-concurrent-reset: 0.010/0.010 secs][ParNew 445124K->350518K(773376K), 0.1800791 secs][ParNew 455478K->361141K(773376K), 0.1849950 secs]
在这个例子中,在CMS周期开始的时候,CMS-initial-mark表明占用量是548460K。在CMS周期开始和结束(CMS-concurrent-reset)之间,ParNew MinorGC报告显著的减少了对象的占用量。尤其,在CMS-concurrent-sweep之前,占用量从561336K降低到了368901K。这个表明在CMS周期中,有190M空间被垃圾回收。需要注意的是,在CMS-concurrent-sweep之后的第一个ParNew MinorGC报告的占用量是350518K。这个说明超过190M被垃圾回收(561336K-350518K=210818K=205.88M)。
如果你决定优化CMS周期的启动,多尝试几个不同的old代占用率。监控垃圾回收信息以及分析这些信息可以帮助你做出正确的决定。
强制的垃圾回收
如果你想要观察通过调用System.gc()来启动的FullGC,当使用用CMS的时候,有两种方法来处理这种情况。
1、你可以请求HotSpot VM执行System.gc()的时候使用CMS周期,使用如下命令选项:
第一个选项在Java 6及更新版本中能够使用,第二选项在从Java 6 Update 4之后才有。如果可以,建议使用后者。
2、你可以请求HotSpot VM选项忽视强制的调用System.gc(),可以使用如下选项:
这个选项用来让其他垃圾回收器忽略System.gc()请求。
当关闭的强制垃圾回收需要小心,这样做可能对Java性能产生很大的影响,关闭这个功能就像使用System.gc()一样需要明确的理由。
在垃圾回收日志里面找出明确的垃圾回收信息是非常容易的。垃圾回收的输出里面包含了一段文字来说明FullGC是用于调用System.gc().下面是一个例子:
注意Full GC后面的(System)标签,这个说明是System.gc()引起的FullGC。如果你在垃圾回收日志里面观察到了明确的FullGC,想想为什么会出现、是否需要关闭、是否需要把应用源代码里面的相关代码删除掉,对CMS垃圾回收周期是否有意义。2010-12-16T23:04:39.452-0600: [Full GC (System)[CMS: 418061K->428608K(16384K), 0.2539726 secs]418749K->4288608K(31168K),[CMS Perm : 32428K->32428K(65536K)],0.2540393 secs][Times: user=0.12 sys=0.01, real=0.25 secs]
并发的Permanent代垃圾回收
FullGC发生可能是由于permanent空间满了引起的,监控FullGC垃圾回收信息,然后观察Permanent代的占用量,判断FullGC是否是由于permanent区域满了引起的。下面是一个由于permanent代满了引起的FullGC的例子:
2010-12-16T17:14:32.533-0600: [Full GC[CMS: 95401K->287072K(1048576K), 0.5317934 secs]482111K->287072K(5190464K),[CMS Perm : 65534K->58281K(65536K)], 0.5319635 secs][Times: user=0.53 sys=0.00, real=0.53 secs]
注意permanent代的空间占用量,通过CMS Perm :标签识别。permanent代空间大小是括号里面的值,65536K。在FullGC之前permanent代的占用量是->左边的值,65534K,FullGC之后的值是58281K。可以看到的是,在FullGC之前,permanent代的占用量以及基本上和permanent代的容量非常接近了,这个说明,FullGC是由Permanent代空间溢出导致的。同样需要注意的是,old代还没有到溢出空间的时候,而且没有证据说明CMS周期启动了。
HotSpot VM默认情况下,CMS不会垃圾回收permanent代空间,尽管垃圾回收日志里面有CMS Perm标签。为让CMS回收permanent代的空间,可以用过下面这个命令选项来做到:
如果使用Java 6 update 3及之前的版本,你必须指定一个命令选项:
你可以控制permanent的空间占用率来启动CMS permanent代垃圾回收通过下面这个命令选项:
这个参数的功能和-XX:CMSInitiatingOccupancyFraction很像,他指的是启动CMS周期的permanent代的占用率。这个参数同样需要和-XX:+CMSClassUnloadingEnabled配合使用。如果你想一直使用-XX:CMSInitiatingPermOccupancyFraction的值作为启动CMS周期的条件,你必须要指定另外一个选项:
CMS暂停时间优化
在CMS周期里面,有两个阶段是stop-the-world阶段,这个阶段所有的应用线程都被阻塞了。这两阶段是“初始标记”阶段和“再标记”阶段,尽管初始标记解决是单线程的,但是通过不需要花费太长时间,至少比其他垃圾回收的时间短。再标记阶段是多线程的,线程数可通过命令选项来控制:
在Java 6 update 23之后,默认值是通过Runtime.availableProcessors()来确定的,不过是建立在返回值小于等于8的情况下,反之,会使用Runtime.availableProcessors()*5/8作为线程数。如果有多个程序运行在同一个机器上面,建议使用比默认线程数更少的线程数。否则,垃圾回收可能会引起其他应用的性能下降,由于在同一个时刻,垃圾回收器使用太多的线程。
在某些情况下设置下面这个选项可以减少再标记的时间:
这个选项强制HotSpot VM在FullGC之前执行MinorGC,在再标记步骤之前做MinorGC,可以减少再标记的工作量,由于减少了young代的对象数,这些对象能够在old代获取到的。
如果应用有大量的引用或者finalizable对象需要处理,指定下面这个选项可以减少垃圾回收的时间:
这个选项可以用HotSpot VM的任何一种垃圾回收器上,他会是用多个的引用处理线程,而不是单个线程。这个选项不会启用多线程运行方法的finalizer。他会使用很多线程去发现需要排队通知的finalizable对象。
下一步
这一步结束,你需要看看应用的延迟需要是否满足了,无论是使用throughput垃圾回收器或者并发垃圾回收器。如果没有能够满足应用的需要,那么回头看看需求是否合理或者修改应用程序。如果满足了应用的需求,那么我们就进入下一步——优化吞吐量。
六:优化吞吐量
如果你已经进行完了前面的步骤了,那么你应该知道这是最后一步了。在这一步里面,你需要测试应用的吞吐量和为了更高的吞吐量而优化JVM。 这一步的输入就是应用的吞吐量性能要求。应用的吞吐量是在应用层面衡量而不是在JVM层面衡量,因此,应用必须要报告出一些吞吐量指标或者应用的某些操作的吞吐量性能指标。观察到的吞吐量指标然后用可以用来和应用需要的性能指标进行比较,如果达到或者超过要求,那么这一步就完成了。如果你需要更好的吞吐量的话,有一些JVM优化可以去做。
这一步的另外一个输入就是,有多少内存可以供应用使用,就想前面说的GC最大化内存原则,越多可用的内存,性能就更好。这条原则不仅仅适用于吞吐量优化,同样适用于延迟优化。
应用的吞吐量需求可能是无法满足的。如果是这种情况,那么就需要重新审视应用吞吐量的需求,应用就需要修改或者改变部署模型。如果上面的一种或者多种情况发生了,那么你需要重新进行前面的优化步骤。
在前面的步骤里面,你可能使用吞吐量垃圾回收器解决了问题(通过-XX:+UseParallelOldGC或者-XX:+UsePrallelGC),或者你调整到并发垃圾回收器(CMS)来解决的问题。如果使用的CMS来解决的问题,下面有一些选项来提升应用的吞吐量,下面详细介绍。如果是使用的吞吐量垃圾回收器,我们将在CMS之后介绍。
CMS吞吐量优化
能够用来提升CMS吞吐量的选项数量有限,下面列出一些可以单独使用或者联合使用的选项:
1、使用一些额外的命令选项,在后面的“额外的性能命令行选项”中详细介绍。
2、增加young代的空间大小,增加young代的空间大小,可以减少MinorGC的频率,就能够减少在一段时间里面MinorGC占用的时间。
3、增加old代的空间大小,增加old代的空间,可以减少CMS垃圾回收的频率,减少潜在的碎片,可以减少
stop-the-world垃圾回收。
4、进一步优化young代堆大小,已经在前面的“优化延迟和响应时间”里面说过了,以及如何优化eden空间任务后和survivor空间大小以减少对象从young代移动到old也在前面已经说过了。需要注意的是,当优化eden和survivor空间大小的时候考虑到一些权衡。
5、优化CMS周期的启动,也在前面说过了。
任何上面提到的优化,或者组合使用上面的选择,都是减少垃圾回收器占用CPU时间,把CPU留给应用计算。前面两种选择,提供一种可能性来提升吞吐量,但是会有stop-the-world垃圾回收的风险,会增加延迟。
作为指导,不考虑CMS,MinorGC的次数应该减少10%,你可能只能降低1%-3%。通常来讲,如果只能减少3%甚至更少,那么能够提升的吞吐量空间恐怕就有限了。
吞吐量垃圾回收器优化
优化吞吐量垃圾回收器的目标是避免FullGC或者理想情况下,避免在稳定状态下FullGC。这个需要优化对象的岁数,这个可以通过制定survivor空间优化完成。你可以让eden空间更大,可以减少MinorGC的次数。我知道当对象的任期或者岁数达到一定值的时候就会移动到old代,而这个任期就是对象经历MinorGC的次数,MinorGC的次数越少,对象任期增长越慢,就有可能被MinorGC回收掉,而不是进入old代。
使用HotSpot VM的吞吐量垃圾回收器,可以通过-XX:+UseParallelOldGC和-XX:+UsePrallelGC,这样可以提供最好的吞吐量。吞吐量垃圾回收器利用了一种叫做自适应大小的特性,自适应大小是基于对象的分配和存活率来自动改变eden空间和survivor空间大小,目的是优化对象的岁数分布。自适应大小的企图是提供易用性,容易优化JVM,以致于提供可靠的吞吐量。自适应大小在大多数应用下,能够很好的工作,但是关闭自适应大小以及优化eden空间和survivor空间以及old代空间是一个探索提升应用吞吐量的一种办法。关闭自适应大小会改变应用的程序的灵活性,尤其是在修改应用程序,以及随着时间的推移应用的数据发生了变化。
关闭自适应大小可以使用选项:
注意在“-XX”后面的“-”表明关闭UseAdapivieSizePolicy提供的特性。只有吞吐量垃圾回收器支持这个选项。在其他的垃圾回收器上使用这个选项是无用的。
另外一个可选的命令行选项,可以产生关于survivor空间占用更详细的信息,关于survivor空间是否溢出,对象是否从young代移动到old代,选项是-XX:+PrintAdaptiveSizePolicy。这个选项最好和-XX:+PrintGCDetails以及-XX:+PrintGCDateStamps或者-XX:+PrintGCTimeStamps一起使用。下面是一个垃圾回收的例子-XX:+PrintGCDateStamps, -XX:PrintGCDetails, -XX:-UseAdaptiveSizePolicy (关闭自适应大小), 以及-XX:+PrintAdaptiveSizePolicy:
2010-12-16T21:44:11.444-0600:
[GCAdaptiveSizePolicy::compute_survivor_space_size_and_thresh:survived: 224408984promoted: 10904856overflow: false[PSYoungGen: 6515579K->219149K(9437184K)]8946490K->2660709K(13631488K), 0.0725945 secs][Times: user=0.56 sys=0.00, real=0.07 secs]
和以前不同的是,以GCAdaptiveSizePolicy开头的一些额外信息输出来了,survived标签表明“to” survivor空间的对象字节数。在这个例子中,survivor空间占用量是224408984字节,但是移动到old代的字节数却有10904856字节。overflow表明young代是否有对象溢出到old代,换句话说,就是表明了“to” survivor是否有足够的空间来容纳从eden空间和“from”survivor空间移动而来的对象。为了更好的吞吐量,期望在应用处于稳定运行状态下,survivor空间不要溢出。
为了开始优化,你应该关闭自适应大小以及获取在垃圾回收器日志里面额外的survivor空间统计信息,使用这两个选项-XX:-UseAdaptiveSizePolicy以及-XX:+PrintAdaptiveSizePolicy。这样提供了一些初始化的信息,以帮助做出优化决定。假如之前使用下面的命令行选项:
那么,就应该如下一组命令行选项,来关闭自适应大小和捕获survivor空间统计信息:
首先在应用稳定运行状态下寻找FullGC信息,包括日期和时间戳可以用来识别出应用是否从启动状态进入了稳定状态。举例,如果你知道应用启动需要30秒时间,那么在应用启动30秒之后才观察垃圾回收。
观察FullGC信息,你可能会发现有一些短存活时间的对象移动到了old代空间,如果FullGC发生了,首先要确定是old代的空间是FullGC之后存活对象的1.5倍。如果有需要,增加old代的空间来保持1.5倍的指标,这样,可以保证old代有足够的空间来处理不在预期内的转移率(导致短的存活时间的对象移动到old代)或者一些未知的情况——导致了对象的转移过快,拥有这样的额外空间,可以延迟甚至可能能够阻止FullGC的发生。
在确定了old代有足够的空间之后,就需要观察MinorGC的状况。首先需要观察survivor空间是否溢出,如果survivor空间溢出了,那么overflow标签会是true,否则,overload字段会是false。下面是一个survivor空间溢出的例子:
2010-12-18T10:12:33.322-0600:
如果survivor空间溢出,对象会再达到任期阀值或者消亡之前被移动到old代。换句话说,对象过快的移动到old代。频繁的survivor空间溢出会导致FullGC,下面说如何优化survivor。[GCAdaptiveSizePolicy::compute_survivor_space_size_and_thresh:survived: 446113911promoted: 10904856overflow: true[PSYoungGen: 6493788K->233888K(9437184K)]7959281K->2662511K(13631488K), 0.0797732 secs][Times: user=0.59 sys=0.00, real=0.08 secs]
优化survivor空间
优化survivor空间的目标是保持或者老化短时间存活动的对象在young代中,一直到不得不移动到old代中。开始查看每一个MinorGC,尤其是存活的对象字节数。需要注意一点的是,为了避免应用启动的时候对象对后面分析的干扰,可以考虑放弃应用刚进入稳定状态的前面5到10个MinorGC信息。
每次MinorGC之后的存活对象数量可以通过-XX:+PrintAdaptiveSizePolicy来查看。在下面的例子中,survivor对象的字节数是224408984。
2010-12-16T21:44:11.444-0600:[GCAdaptiveSizePolicy::compute_survivor_space_size_and_thresh:survived: 224408984promoted: 10904856overflow: false[PSYoungGen: 6515579K->219149K(9437184K)]8946490K->2660709K(13631488K), 0.0725945 secs][Times: user=0.56 sys=0.00, real=0.07 secs][GCAdaptiveSizePolicy::compute_survivor_space_size_and_thresh:survived: 224408984promoted: 10904856overflow: false[PSYoungGen: 6515579K->219149K(9437184K)]8946490K->2660709K(13631488K), 0.0725945 secs][Times: user=0.56 sys=0.00, real=0.07 secs]
使用最大存活对象数量以及知道目标survivor空间的占用量,你可以决定出最差survivor空间大小,以使得让对象老化得更加高效。如果目标survivor空间的占用率没有通过-XX:TargetSurvivorRatio=<percent>指定,那么目标survivor空间的占用率是50%。
首先为最差的场景优化survivor空间,这个需要找出在MinorGC之后最大的存活对象数量,注意可以忽略应用进入稳定状态前面的5到10个MinorGC。可以通过awk或者perl脚本来完成这项工作。
调整survivor空间的大小,不是仅仅修改survivor空间的大小以使得比存活的对象字节数更大那么简单。需要记住的是,如果不增加young代的空间大小,而增加survivor空间的大小,会减少eden空间的大小,这样会导致频繁的MinorGC,从而是的对象的老化速度加快,更快的进入old代,又会导致FullGC。所以,需要同步增加young代的空间大小。如果不增加old的空间,那么就有可能造成频繁的FullGC甚至内存溢出错误。因此,如果有可以获取的空间,需要同步增加Java堆的空间。
同样建议,HotSpot Vm使用默认的目标survivor空间占用率(50%),如果使用了-XX:TargetSurvivorRatio=<percent>,会使用<percent>作为MinorGC之后目标survivor空间占用率。如果survivor空间的占用率可能超过这个目标值,会在对象达到最大岁数之前把对象移动到old代去。
通过一个例子详细说明,考虑用下面的命令选项:
总共的Java堆空间是13g,young代是4g,old代是9g,survivor空间的大小是4g/(6+2)=512M。假如一个应用的存活对象是470M,由于没有明确指定-XX:TargetSurvivorRatio=<percent>,那么默认的目标survivor空间占用率是50%,那么最小的survivor空间应该是940M,也就是最坏的情况,需要设置940M的survivor空间。
从上面的例子来看,4g的young代空间被分隔成两个512M的survivor空间和一个3g的eden空间。刚才分析的最坏情况分配给survivor的空间是940M,差不多和1g相当。为了保持对象老化速率,即保持MinorGC的频率,eden空间需要保持在3g。因此,young代需要给每一个survivor空间1g内存以及3g的eden空间,那么young代需要增加到5g,也就是说young代需要增加1g空间,需要把-Xmn4g选项改成-Xmn5g选项。比较的理想的情况是,同步把Java堆的空间也增加1g。但是如果内存不够用,需要保证old代空间大小至少是存活对象的1.5倍。
假设应用的内存需求满足,增加survivor空间占用后的命令选项是:
old空间还是9g,young代的空间是5g,比之前大了1g,eden还是3g,每一个survivor空间是1g。
你可能需要重复多次设定大小,直到满足内存占用的条件下到达吞吐量的峰值。吞吐的峰值一般都是在对象最有效的老化的时候的达到的。
通常的建议是,吞吐量垃圾回收器的垃圾回收的开销应该小于5%。如果你只能把这个开销降低1%甚至更少,你可能需要使用除本章描述之外的特别努力和很大的开销来优化JVM。
优化Parallel GC线程
吞吐量垃圾回收器的线程数的优化同样基于有多少应用运行在同一个系统里面以及硬件平台。就像前面的“优化CMS”里面提到的,如果是多个应用运行在同一个系统上面,建议使用比垃圾回收器默认使用的线程数更少的线程数,使用选项是-XX:ParallelGCThreads=<n>.
另外,由于大量的垃圾回收线程同时执行,垃圾回收可能会严重影响其他应用的性能。由于Java 6 Update 23之后,默认的垃圾回收线程是执行Runtime.availableProcessors()获得的,如果这个方法的返回值小于等于8,那么就用这个返回值,如果比8更大,那么就取这个值的5/8。如果运行多个应用,可以根据应用的情况来分配线程数,如果应用的消耗是相当的,那么就用CPU的内核数除以应用数得到每一个应用可以分配的线程。如果应用的load不相当,那么就可以根据应用的实际情况来衡量和分配。
下一步
如果你到这一步都还没有能够达到吞吐量的要求,那么可以尝试后面的“额外的性能选项”,如果还是无法达到,就只能修改应用或者JVM部署结构了。如果进行了修改应用或者修改了部署结构,你需要重新做前面的各个步骤。
可能会用到的一些边缘场景,下面一节介绍。
七:其他
边缘问题 在某些场景下,按照前面的一步步优化指导无法产生效果。这一节说明一下这些情况。
一些应用分配了一些少量的非常大的长时间存活的对象。这样的场景需要需要young代的空间比old代更大。
一些应用会经历很少的对象转移。这样的场景可能需要old代的空间远远大于存活对象的大小,由于old的占用量增长率很小。
一些应用有小延迟需求,会使用CMS垃圾回收器,而且使用小young代空间(以致于MinorGC时间更短),以及大的old代空间。在这种配置下,对象会快速的从young代移动到old代,替代了高效老化对象。另外,CMS垃圾回收移动后的对象,碎片的可能性通过大的old代空间来解决。
下一节介绍一些其他的HotSpot VM选项来提升应用的性能。
其他一些的性能命令行选项
几个可选的前面有提到的命令选项可以用来提升Java应用的延迟和吞吐量性能,这些选项是通过JIT编译器代码优化以及其他的HotSpot VM优化能力。下面介绍这些特性以及相适应的命令选项。
最新和最大优化
当新的性能优化集成到HotSpot VM中之后,可以通过-XX:+AggressiveOpts选项来启用。
通过选项来引入新的优化,可以把最新及最大的优化和以及经过长时间使用证明是稳定的优化分离开。应用通常更希望获得更好的稳定性,毕竟最新的优化可能会导致未知的问题。但是如果应用需要提升任何可以提升的性能优化的时候,可以使用命令选项来启用这些优化。
当新的优化被证明是稳定的之后,他们会被默认使用,也许需要升级几个版本之后才会变成默认。
使用-XX:+AggressiveOpts命令选项之后,需要考虑到性能的提升,同样也需要考虑到性能提升所带来的不稳定风险。
逃避分析
逃避分析是一个种分析Java对象范围的技术,在特殊情况下,一个线程分配的对象可能被另外一个线程使用,这个对象就叫着“逃避”。如果对象没有逃避,额外的优化技术可以应用,因此,这种优化技术叫做逃避分析。
在HotSpot VM里面的逃避分析优化可以通过命令行选项:
这是在Java 6 update 14中引入的,而且自动启用通过-XX:+AggressiveOpts。在Java 6 update 23中是默认开启的。
通过逃避分析,HotSpot VM JIT编译器,可应用下面的优化技术:
1、对象爆炸:对象爆炸是一种对象的属性存储在Java堆以外而且可能潜在的消失。比如说,对象属性可以直接被放置到内存的寄存器里面或者对象被分配栈里面而不是堆里面。
分等级替换:分等级替换是一种用来减少内存使用的优化技术,考虑下面的Java类,表现为保存长方形的长和宽:
public class Rectangle {int length;int width;}
HotSpot VM可以优化内存分配和使用非逃避的Rectangle类的实例通过把长和宽都直接存储到CPU的寄存器而不是分配Rectangle对象,结果是当时需要使用长和宽属性的时候,不需要再复制到CPU的寄存器。这个可以减少内存的读取。
2、线程栈分配:顾名思义,线程栈分配是一种把对象分配到线程栈中,而不是Java堆里面的优化技术。一个对象永远不逃避,就可以放置到线程栈框架里面,由于没有其他线程需要看到这个对象。线程栈分配可以减少对象分配到Java堆,可以减少GC的频率。
3、消灭同步:如果线程分配的对象从来不会逃避,而且这个线程锁定了这个对象,这个锁可能会被JIT编译器消灭,毕竟没有其他线程会使用这个对象。
4、消灭垃圾回收读写障碍:如果线程分配的对象从来不会逃避,只会被当前线程使用,所以在其他对象里面存储它的地址不需要障碍。读或者写障碍只有在对象会被其他线程使用的时候才有需要。
有偏见的锁
有偏见的锁是使得锁更偏爱上次使用到它线程。在非竞争锁的场景下,即只有一个线程会锁定对象,可以实现近乎无锁的开销。
有偏见的锁,是在Java 5 update 6引入的。通过HotSpot VM的命令选项-XX:+UseBiasedLocking启用。
Java 5 HotSpot JDK需要明确的命令来启用这个特性,在使用-XX:+AggressiveOpts选项,有偏见的锁会Java 5中会被自动启用。在Java 6中是默认启用的。
各种经历告诉我们这个特性对大多数应用还是非常有用的。然后,有一些应用使用这个属性不一定能够表现的很好,比如,锁被通常不被上次使用它的同一个线程使用。对于Java应用来说,由于stop-the-world安全点操作需要取消偏见,这样可以通过使用-XX:-UseBiaseLocking来获得好处。如果你不清楚你的应用是什么情况,可以通过分别设置这两个选项来测试。
大页面
在计算机系统中,内存被分为固定大小的区块,这个区块就叫做页(page)。内存的存取是通过程序把虚拟内存地址转换成物理内存地址实现的。虚拟到物理地址是在一个块表里面映射的。为了减少每次存取内存的时候使用页表的消耗,通常会使用一种快速的虚拟到物理地址转换的缓存。这个缓存叫做转换后备缓冲区(translation lookaside buffer),简称TLB。
通过TLB来满足虚拟到物理地址的映射请求,会比遍历页表来找到映射关系快很多,一个TLB通常包含指定数量的条目。一个TLB条目是一个基于页大小虚拟到物理地址映射,因此,更大的页大小允许一个条目或者一个TLB有更大的内存地址范围。在TLB中有更广泛的地址,更少的地址转换请求在TLB中不命中,就可以减少遍历页表(page table)操作。使用大页的目的就是减少TLB的不命中。
Oracle solariz,Linux 以及Windows都支持HotSpot VM使用大页。通常处理器可以支持几种页大小,不过不同的处理器各不相同。另外,操作系统配置需要使用大页。
下面说说怎么样在Linux下使用大页(Large Page)
Linux下的大页面
在写作本书的时候,在Linux下使用大页,除使用-XX:+UseLargePages命令选项以外,需要修改操作系统配置。Linux的修改操作具体和发行版本以及内核有关系。为了合理的启用Linux下的大页,可以征询Linux管理员的意见或者阅读Linux发行文档。一旦使用了Linux操作系统配置已经修改,-XX:+UseLargePage命令行选项就必须要使用了。比如:
如果大页没有被合理设置,HotSpot VM同样会接受-XX:+UseLargePages是一个有效的选项,不过会报告无法获取大页,而且会退回操作系统的默认页大小。
PS:打完收工,其实翻译挺无聊和挺累的
转载:http://blog.csdn.net/zhoutao198712/article/details/7783038
阅读全文
0 0
- 一步步优化JVM
- 一步步优化JVM七:其他
- 一步步优化JVM七:其他
- 一步步优化JVM<七>:其他
- 一步步优化JVM三:GC优化基础
- 一步步优化JVM三:GC优化基础
- 一步步优化JVM六:优化吞吐量
- 一步步优化JVM六:优化吞吐量[转]
- 一步步优化JVM三:GC优化基础
- 一步步优化JVM六:优化吞吐量
- 一步步优化JVM<三>:GC优化基础
- 一步步优化JVM<六>:优化吞吐量
- 一步步优化JVM二:JVM部署模型和JVM Runtime
- 一步步优化JVM二:JVM部署模型和JVM Runtime
- 一步步优化JVM二:JVM部署模型和JVM Runtime
- 一步步优化JVM<二>:JVM部署模型和JVM Runtime
- 一步步优化JVM五:优化延迟或者响应时间(1)
- 一步步优化JVM五:优化延迟或者响应时间(2)
- Python崛起, JavaScript称霸!GitHub年度报告,2017年编程语言之争~
- Python 2.7+win10 64位,安装PIL库提示未找到注册的解决办法
- 关于Charles无法抓包问题
- Mycat从入门到放弃
- 新浪微博简单搜索接口
- 一步步优化JVM
- 高德地图添加多个点标注的点击事件
- SDN究竟如何改变了路由器技术的发展
- html前端面试题
- 做人,不可打破的天规!切记
- Android SO文件的兼容和适配
- mysql中utf8和utf8mb4区别
- SSM之Mybatis缓存
- Android 加载html5页面出现乱码


