【机器学习笔记】权衡 bias 和 variance
来源:互联网 发布:睿博数据 编辑:程序博客网 时间:2024/05/16 10:40
Training error & Generalization error
Training error 是说对于一个假设
Generalization error 是指对于一个假设
当样本数量
bias 和 variance
Generalization error可以用如下的式子表出(换种表示):
以回归模型为例,假设我们的一个预测模型,得出样本数据的期望为
bias
bias 是模型过于简单的时候,欠拟合, 模型表现出来的误差:
为了计算方便(去掉绝对值),我们在计算时用
variance
是指模型过于复杂时,过拟合表现出的误差;表现出来的一些特性仅仅适用于训练集,而一旦应用于其他数据集(测试集)就会出现较大误差
比如,我们用原来的训练集
ϵ
Generalization error 与 bias, variance的关系可以用下图表示:
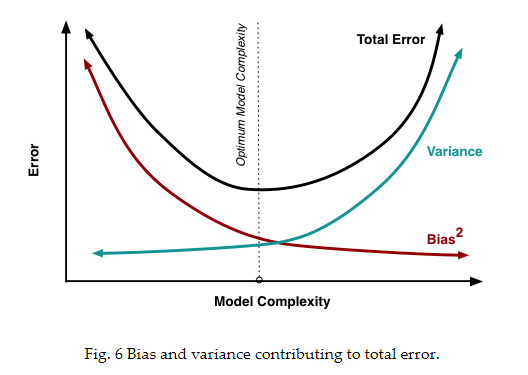
ERM(empirical risk minimization)
ERM(empirical risk minimization) 本质就是最小化经验误差
显式表示为:
经验误差为:
也就是之前说的training error.
算法的目的就是求得:
模型复杂度的影响:
我们先假定问题是PAC(probably approximately correct) 的(下一篇我会展开说明PAC,以及为什么得到下面那个式子),也就是说,我们可以通过优化训练误差来近似估计泛化误差,对于训练过程中,训练误差最小的
其中
我们可以近似理解为:
和上图类似,具体的影响如下图的曲线所表示。 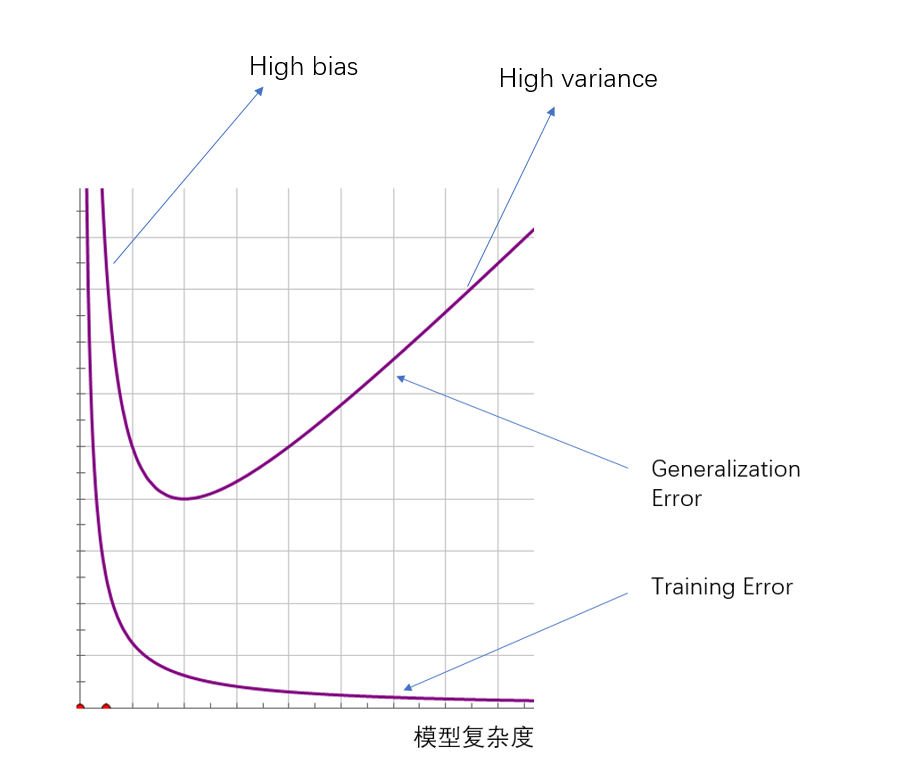
- 【机器学习笔记】权衡 bias 和 variance
- 机器学习算法中的偏差-方差权衡(Bias-Variance Tradeoff)
- 机器学习方差和偏差权衡(Understanding the Bias-Variance Tradeoff)
- 机器学习笔记十六:错误来源Bias和Variance
- 【机器学习】bias and variance
- 机器学习中的偏差(bias)和方差(variance)
- 机器学习:Bias(偏差),Error(误差),和Variance(方差)
- 机器学习:方差Variance与偏差Bias
- 机器学习笔记——偏差(bias)和方差(variance)及其与K折交叉验证的关系
- 机器学习基础(一)机器学习中的Bias(偏差),Error(误差),和Variance(方差)
- 学习笔记——Bias-variance
- 偏见方差的权衡(Bias Variance Tradeoff)
- bias与variance的权衡(tradeoff)
- 偏差-方差权衡(Bias-Variance Tradeoff)
- 机器学习入门系列03,Error的来源:偏差和方差(bias 和 variance)
- 机器学习中的bias和variance、欠拟合和过拟合
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- springMVC中前端将传递数据传递到后端后端的接收方式
- 关于c语言中获取时间及格式和操作
- 数据库隔离级别
- 【源码】canal和otter的高可靠性分析
- 23 查看真实基数--优化主题系列
- 【机器学习笔记】权衡 bias 和 variance
- 51nod 1432 独木舟(贪心)
- 递归函数逆序输出程序
- 学习tomcat(一)----用IDEA调试tomcat源码
- 关于二叉树二叉堆的一些基本概念
- LeetCode.121(122/123) Best Time to Buy and Sell Stock && II && III
- 常见浏览器兼容问题
- MFC VS2013 配置 opencv 出现无法打开afxcmn.h,afxdisp.h,afxext.h,SDKDDKVer.h,afxcontrolbars.h等等文件
- JAVA中jar包反编译再重新生成jar文件完整流程


