redis学习系列(三-5)--redis基础类型初探(有序集合对象)
来源:互联网 发布:怎样快速提升淘宝信誉 编辑:程序博客网 时间:2024/05/17 09:08
有序集合对象使用的编码是ziplist或者skiplist
ziplist
有序结合的ziplist使用的是压缩列表作为底层实现,每个集合元素使用的紧靠的压缩列表节点存储,第一个节点保存成员,第二个元素保存元素的分值。
因此压缩列表内集合元素按照分值大小排序,分值较小放置靠近表头,分值较大放置在表尾的位置
下例子中分值是 8 6 7 4
127.0.0.1:6379> zadd p 8 apple 6 ba 7 ch 4 uu
(integer) 4
127.0.0.1:6379> type p
zset
127.0.0.1:6379> zrange p 0 -1
1) "uu"
2) "ba"
3) "ch"
4) "apple"
127.0.0.1:6379> obejct encoding p
(error) ERR unknown command 'obejct'
127.0.0.1:6379> object encoding p
"ziplist"
127.0.0.1:6379>
![digraph { label = "\n 图 8-15 有序集合元素在压缩列表中按分值从小到大排列"; // node [shape = record]; ziplist [label = " zlbytes | zltail | zllen | <banana> \"banana\" | <banana_price> 5.0 | <cherry> \"cherry\" | <cherry_price> 6.0 | <apple> \"apple\" | <apple_price> 8.5 | zlend "]; node [shape = plaintext]; banana [label = "分值最少的元素"]; cherry [label = "分值排第二的元素"]; apple [label = "分值最大的元素"]; // edge [style = dashed] banana -> ziplist:banana [label = "成员"]; banana -> ziplist:banana_price [label = "分值"]; cherry -> ziplist:cherry; cherry -> ziplist:cherry_price; apple -> ziplist:apple; apple -> ziplist:apple_price;}](http://redisbook.com/_images/graphviz-8d7b7d0e78ad9d445ff14834e9e9618234395d46.png)
skiplist
skiplist编码的有序集合对象使用的是zset结构作为底层实现,一个zet包含一个字典和一个跳跃表
咋读一遍,我大概知道了 *zsl便于 范围操作, 而 *dict 便于精确查询*zsl
跳跃表,按照分值大小从小到大保存所有集合元素,每个跳跃表都保存了一个集合元素,跳跃表节点的object属性保存了元素的成员,节点的score保存了元素的分值,通过此
可以进行范围操作,例如zrange
*dict
dict为有序集合创建了一个从成员到分值的映射,字典中的每个键值对都保存了一个元素集合,键保存了元素的成员,字典的值保存了元素的分值,因此通过这个字典,程序可以用O(1)复杂度查询到指定成员的分值,ZSCORE就是根据这个特性实现的
有序集合每个元素的成员都是一个字符串对象,每个元素的分值都是一个double类型的浮点数,值得一提的是虽然使用了两种结构来保存数据,但是两种结构都会通过指针来共享相同元素的成员和分值,因此不会浪费额外的内存
另外书中也介绍了为什么同时使用了跳跃表和字典来实现有序集合
1.如果单纯使用跳跃表,那么跳跃表的有点会存在,也就是范围操作会快很多,但是没有了字典,通过分值查询这一操作的复杂度将从O(1)上升为O(logN)
2.如果单纯使用字典,那么分值查询会很快,O(1),但是范围操作会需要先执行排序,至少需要O(N\logN),另外需要额外的O(N)的内存空间,不合算。
至于跳跃表,内部实现有点复杂,暂时不去看了,知道一下
![digraph { rankdir = LR; // node [shape = record]; zset [label = " <head> zset | <dict> dict | <zsl> zsl "]; dict [label = " <head> dict | ... | <ht0> ht[0] | ... "]; ht0 [label = " <head> dictht | ... | <table> table | ... "]; table [label = " <banana> StringObject \n \"banana\" | <apple> StringObject \n \"apple\" | <cherry> StringObject \n \"cherry\" "]; node [shape = plaintext]; apple_price [label = "8.5"]; banana_price [label = "5.0"]; cherry_price [label = "6.0"]; // zset:dict -> dict:head; dict:ht0 -> ht0:head; ht0:table -> table:head; table:apple -> apple_price; table:banana -> banana_price; table:cherry -> cherry_price; // node [shape = record, width = "0.5"]; // l [label = " <header> header | <tail> tail | level \n 5 | length \n 3 "]; subgraph cluster_nodes { style = invisible; header [label = " <l32> L32 | ... | <l5> L5 | <l4> L4 | <l3> L3 | <l2> L2 | <l1> L1 "]; bw_null [label = "NULL", shape = plaintext]; level_null [label = "NULL", shape = plaintext]; A [label = " <l4> L4 | <l3> L3 | <l2> L2 | <l1> L1 | <backward> BW | 5.0 | StringObject \n \"banana\" "]; B [label = " <l2> L2 | <l1> L1 | <backward> BW | 6.0 | StringObject \n \"cherry\" "]; C [label = " <l5> L5 | <l4> L4 | <l3> L3 | <l2> L2 | <l1> L1 | <backward> BW | 8.5 | StringObject \n \"apple\" "]; } subgraph cluster_nulls { style = invisible; n1 [label = "NULL", shape = plaintext]; n2 [label = "NULL", shape = plaintext]; n3 [label = "NULL", shape = plaintext]; n4 [label = "NULL", shape = plaintext]; n5 [label = "NULL", shape = plaintext]; } // l:header -> header; l:tail -> C; header:l32 -> level_null; header:l5 -> C:l5; header:l4 -> A:l4; header:l3 -> A:l3; header:l2 -> A:l2; header:l1 -> A:l1; A:l4 -> C:l4; A:l3 -> C:l3; A:l2 -> B:l2; A:l1 -> B:l1; B:l2 -> C:l2; B:l1 -> C:l1; C:l5 -> n5; C:l4 -> n4; C:l3 -> n3; C:l2 -> n2; C:l1 -> n1; bw_null -> A:backward -> B:backward -> C:backward [dir = back]; zset:zsl -> l:header; // HACK: 放在开头的话 NULL 指针的长度会有异样 label = "\n 图 8-17 有序集合元素同时被保存在字典和跳跃表中";}](http://redisbook.com/_images/graphviz-75ee561bcc63f8ea960d0339768aec97b1f570f0.png)
另外copy了一张网图,便于理解,其实跳跃表比一般单链表快的原因,就是它能跳跃着寻找这个元素,而不是传统的O(n)。
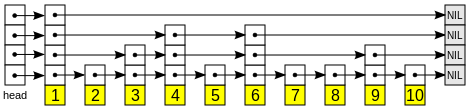
Redis作者为了适合自己功能的需要,对原来的跳跃表进行了一下修改:
1、 允许重复的score值:多个不同的元素(member)的score值可以相同
2、 进行元素对比的时候,不仅要检查score值,还需要检查member:当score值相等时,需要比较member域进行比较。
3、 结构保存一个tail指针:跳跃表的表尾指针
4、 每个节点都有一个高度为1层的前驱指针,用于从底层表尾向表头方向遍历
编码的转换
ziplist使用条件:
1.有序集合保存的数量小于128个,
2.有序集合保存的所有元素的长度都小于54字节。
可以通过配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 来修改配置
因为有序集合键的值为有序集合对象, 所以用于有序集合键的所有命令都是针对有序集合对象来构建的, 表 8-11 列出了其中一部分有序集合键命令, 以及这些命令在不同编码的有序集合对象下的实现方法。
表 8-11 有序集合命令的实现方法
ziplist 编码的实现方法zset 编码的实现方法ziplistInsert 函数, 将成员和分值作为两个节点分别插入到压缩列表。先调用 zslInsert 函数, 将新元素添加到跳跃表, 然后调用 dictAdd 函数, 将新元素关联到字典。ZCARD调用 ziplistLen 函数, 获得压缩列表包含节点的数量, 将这个数量除以 2 得出集合元素的数量。访问跳跃表数据结构的 length 属性, 直接返回集合元素的数量。ZCOUNT遍历压缩列表, 统计分值在给定范围内的节点的数量。遍历跳跃表, 统计分值在给定范围内的节点的数量。ZRANGE从表头向表尾遍历压缩列表, 返回给定索引范围内的所有元素。从表头向表尾遍历跳跃表, 返回给定索引范围内的所有元素。ZREVRANGE从表尾向表头遍历压缩列表, 返回给定索引范围内的所有元素。从表尾向表头遍历跳跃表, 返回给定索引范围内的所有元素。ZRANK从表头向表尾遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。从表头向表尾遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。ZREVRANK从表尾向表头遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。从表尾向表头遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。ZREM遍历压缩列表, 删除所有包含给定成员的节点, 以及被删除成员节点旁边的分值节点。遍历跳跃表, 删除所有包含了给定成员的跳跃表节点。 并在字典中解除被删除元素的成员和分值的关联。ZSCORE遍历压缩列表, 查找包含了给定成员的节点, 然后取出成员节点旁边的分值节点保存的元素分值。直接从字典中取出给定成员的分值。- redis学习系列(三-5)--redis基础类型初探(有序集合对象)
- redis学习系列(三-4)--redis基础类型初探(集合对象)
- redis学习系列(三-2)--redis基础类型初探(列表对象)
- redis学习系列(三-3)--redis基础类型初探(hash对象)
- redis学习系列(三-1)--redis基础类型初探(字符串)
- Redis学习笔记(六)类型之有序集合
- redis数据类型(五)有序集合类型
- Redis学习笔记(七)——Redis常用命令入门——有序集合类型
- Redis数据类型之有序集合类型--Redis系列六
- Redis命令学习-SortedSet(有序集合)
- Redis系列学习笔记6 有序集合
- Redis对象-5-有序集合对象
- Redis-Redis实战(有序集合)
- Redis研究(八)—有序集合类型 1
- Redis研究(九)—有序集合类型 2
- Redis教程(六) 有序集合(soted set / zset)类型
- Redis教程(六) 有序集合(soted set / zset)类型
- Redis系列~有序集合(sorted set)(十)
- 性能优化问题?
- Unity中如何利用一个协程和www类实现简单的图片下载
- Vagrant 导出自己的box
- TCP-IP协议详解
- c++学习笔记之数组及vector
- redis学习系列(三-5)--redis基础类型初探(有序集合对象)
- Java项目配置文件读取的两个方式
- JS函数节流防抖
- Android RecyclerView 使用完全解析 体验艺术般的控件
- Linux下监视NVIDIA的GPU使用情况
- 聚类算法学习----之----sklearn.cluster.KMeans
- QD价值体现?
- 玩转算法面试-查找
- lintOptions


