深度强化学习(DQN)实现CartPole
来源:互联网 发布:日英翻译软件 编辑:程序博客网 时间:2024/06/04 08:59
1 前言
终于到了DQN系列真正的实战了。今天我们将一步一步的告诉大家如何用最短的代码实现基本的DQN算法,并且完成基本的RL任务。这恐怕也将是你在网上能找到的最详尽的DQN实战教程,当然了,代码也会是最短的。
在本次实战中,我们不选择Atari游戏,而使用OpenAI Gym中的传统增强学习任务之一CartPole作为练手的任务。之所以不选择Atari游戏,有两点原因:一个是训练Atari要很久,一个是Atari的一些图像的处理需要更多的tricks。而CartPole任务则比较简单。
上图就是CartPole的基本任务示意图,基本要求就是控制下面的cart移动使连接在上面的杆保持垂直不倒。这个任务简化到只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个杆的位置和速度。
 上图就是CartPole的基本任务示意图,基本要求就是控制下面的cart移动使连接在上面的杆保持垂直不倒。这个任务简化到只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个杆的位置和速度。
上图就是CartPole的基本任务示意图,基本要求就是控制下面的cart移动使连接在上面的杆保持垂直不倒。这个任务简化到只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个杆的位置和速度。今天我们就要用DQN来解决这个问题。
2 完成前提
虽然之前的文章已经说了很多,但是为了完成这个练习,大家还是需要一定的基础的:
- 熟悉Python编程,能够使用Python基本的语法
- 对Tensorflow有一定的了解,知道基本的使用
- 知道如何使用OpenAI Gym
- 了解基本的神经网络MLP
- 理解DQN算法
看起来似乎是蛮有难度,但是如果你一步一步看过来的话,这些前提都很容易满足。
3 开始
先上一下最后的测试效果图:
也就是100%解决问题!
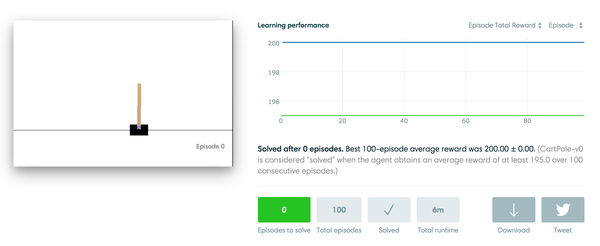 也就是100%解决问题!
也就是100%解决问题!链接:https://gym.openai.com/evaluations/eval_kBouPnRtQCezgE79s6aA5A
我们将要实现的是最基本的DQN,也就是NIPS 13版本的DQN:
面对CartPole问题,我们进一步简化:
 面对CartPole问题,我们进一步简化:
面对CartPole问题,我们进一步简化:- 无需预处理Preprocessing。也就是直接获取观察Observation作为状态state输入。
- 只使用最基本的MLP神经网络,而不使用卷积神经网络。
3.1 编写主程序
按照至上而下的编程方式,我们先写主函数用来执行这个实验,然后再具体编写DQN算法实现。
先import所需的库:
import gymimport tensorflow as tf import numpy as np import randomfrom collections import deque编写主函数如下:
# Hyper ParametersENV_NAME = 'CartPole-v0'EPISODE = 10000 # Episode limitationSTEP = 300 # Step limitation in an episodedef main(): # initialize OpenAI Gym env and dqn agent env = gym.make(ENV_NAME) agent = DQN(env) for episode in xrange(EPISODE): # initialize task state = env.reset() # Train for step in xrange(STEP): action = agent.egreedy_action(state) # e-greedy action for train next_state,reward,done,_ = env.step(action) # Define reward for agent reward_agent = -1 if done else 0.1 agent.perceive(state,action,reward,next_state,done) state = next_state if done: breakif __name__ == '__main__': main()我们将编写一个DQN的类,DQN的一切都将封装在里面。在主函数中,我们只需调用
agent.egreedy_action(state) # 获取包含随机的动作agent.perceive(state,action,reward,next_state,done) # 感知信息本质上就是一个输出动作,一个输入状态。当然我们这里输入的是整个transition。
然后环境自己执行动作,输出新的状态:
next_state,reward,done,_ = env.step(action)然后整个过程就反复循环,一个episode结束,就再来一个。
这就是训练的过程。
但只有训练显然不够,我们还需要测试。因此,在main()的最后,我们再加上几行的测试代码:
# Test every 100 episodes if episode % 100 == 0: total_reward = 0 for i in xrange(TEST): state = env.reset() for j in xrange(STEP): env.render() action = agent.action(state) # direct action for test state,reward,done,_ = env.step(action) total_reward += reward if done: break ave_reward = total_reward/TEST print 'episode: ',episode,'Evaluation Average Reward:',ave_reward if ave_reward >= 200: break测试中唯一的不同就是我们使用
action = agent.action(state)来获取动作,也就是完全没有随机性,只根据神经网络来输出,没有探索,同时这里也就不再perceive输入信息来训练。
OK,这就是基本的主函数。接下来就是实现DQN
3.2 DQN实现
3.2.1 编写基本DQN类的结构
class DQN(): # DQN Agent def __init__(self, env): #初始化 def create_Q_network(self): #创建Q网络 def create_training_method(self): #创建训练方法 def perceive(self,state,action,reward,next_state,done): #感知存储信息 def train_Q_network(self): #训练网络 def egreedy_action(self,state): #输出带随机的动作 def action(self,state): #输出动作主要只需要以上几个函数。上面已经注释得很清楚,这里不再加以解释。
我们知道,我们的DQN一个很重要的功能就是要能存储数据,然后在训练的时候minibatch出来。所以,我们需要构造一个存储机制。这里使用deque来实现。
self.replay_buffer = deque()3.2.2 初始化
def __init__(self, env): # init experience replay self.replay_buffer = deque() # init some parameters self.time_step = 0 self.epsilon = INITIAL_EPSILON self.state_dim = env.observation_space.shape[0] self.action_dim = env.action_space.n self.create_Q_network() self.create_training_method() # Init session self.session = tf.InteractiveSession() self.session.run(tf.initialize_all_variables())这里要注意一点就是egreedy的epsilon是不断变小的,也就是随机性不断变小。怎么理解呢?就是一开始需要更多的探索,所以动作偏随机,慢慢的我们需要动作能够有效,因此减少随机。
3.2.3 创建Q网络
我们这里创建最基本的MLP,中间层设置为20:
def create_Q_network(self): # network weights W1 = self.weight_variable([self.state_dim,20]) b1 = self.bias_variable([20]) W2 = self.weight_variable([20,self.action_dim]) b2 = self.bias_variable([self.action_dim]) # input layer self.state_input = tf.placeholder("float",[None,self.state_dim]) # hidden layers h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1) # Q Value layer self.Q_value = tf.matmul(h_layer,W2) + b2 def weight_variable(self,shape): initial = tf.truncated_normal(shape) return tf.Variable(initial) def bias_variable(self,shape): initial = tf.constant(0.01, shape = shape) return tf.Variable(initial)只有一个隐层,然后使用relu非线性单元。相信对MLP有了解的知友看上面的代码很easy!要注意的是我们state 输入的格式,因为使用minibatch,所以格式是[None,state_dim]
3.2.4 编写perceive函数
def perceive(self,state,action,reward,next_state,done): one_hot_action = np.zeros(self.action_dim) one_hot_action[action] = 1 self.replay_buffer.append((state,one_hot_action,reward,next_state,done)) if len(self.replay_buffer) > REPLAY_SIZE: self.replay_buffer.popleft() if len(self.replay_buffer) > BATCH_SIZE: self.train_Q_network()这里需要注意的一点就是动作格式的转换。我们在神经网络中使用的是one hot key的形式,而在OpenAI Gym中则使用单值。什么意思呢?比如我们输出动作是1,那么对应的one hot形式就是[0,1],如果输出动作是0,那么one hot 形式就是[1,0]。这样做的目的是为了之后更好的进行计算。
在perceive中一个最主要的事情就是存储。然后根据情况进行train。这里我们要求只要存储的数据大于Batch的大小就开始训练。
3.2.5 编写action输出函数
def egreedy_action(self,state): Q_value = self.Q_value.eval(feed_dict = { self.state_input:[state] })[0] if random.random() <= self.epsilon: return random.randint(0,self.action_dim - 1) else: return np.argmax(Q_value) self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/10000def action(self,state): return np.argmax(self.Q_value.eval(feed_dict = { self.state_input:[state] })[0])区别之前已经说过,一个是根据情况输出随机动作,一个是根据神经网络输出。由于神经网络输出的是每一个动作的Q值,因此我们选择最大的那个Q值对应的动作输出。
3.2.6 编写training method函数
def create_training_method(self): self.action_input = tf.placeholder("float",[None,self.action_dim]) # one hot presentation self.y_input = tf.placeholder("float",[None]) Q_action = tf.reduce_sum(tf.mul(self.Q_value,self.action_input),reduction_indices = 1) self.cost = tf.reduce_mean(tf.square(self.y_input - Q_action)) self.optimizer = tf.train.AdamOptimizer(0.0001).minimize(self.cost)这里的y_input就是target Q值。我们这里采用Adam优化器,其实随便选择一个必然SGD,RMSProp都是可以的。可能比较不好理解的就是Q值的计算。这里大家记住动作输入是one hot key的形式,因此将Q_value和action_input向量相乘得到的就是这个动作对应的Q_value。然后用reduce_sum将数据维度压成一维。
3.2.7 编写training函数
def train_Q_network(self): self.time_step += 1 # Step 1: obtain random minibatch from replay memory minibatch = random.sample(self.replay_buffer,BATCH_SIZE) state_batch = [data[0] for data in minibatch] action_batch = [data[1] for data in minibatch] reward_batch = [data[2] for data in minibatch] next_state_batch = [data[3] for data in minibatch] # Step 2: calculate y y_batch = [] Q_value_batch = self.Q_value.eval(feed_dict={self.state_input:next_state_batch}) for i in range(0,BATCH_SIZE): done = minibatch[i][4] if done: y_batch.append(reward_batch[i]) else : y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i])) self.optimizer.run(feed_dict={ self.y_input:y_batch, self.action_input:action_batch, self.state_input:state_batch })首先就是进行minibatch的工作,然后根据batch计算y_batch。最后就是用optimizer进行优化。
4 整个程序
以上便是编写DQN的全过程了。是不是很简单呢,下面再把整个程序放出如下:
import gymimport tensorflow as tfimport numpy as npimport randomfrom collections import deque# Hyper Parameters for DQNGAMMA = 0.9 # discount factor for target QINITIAL_EPSILON = 0.5 # starting value of epsilonFINAL_EPSILON = 0.01 # final value of epsilonREPLAY_SIZE = 10000 # experience replay buffer sizeBATCH_SIZE = 32 # size of minibatchclass DQN(): # DQN Agent def __init__(self, env): # init experience replay self.replay_buffer = deque() # init some parameters self.time_step = 0 self.epsilon = INITIAL_EPSILON self.state_dim = env.observation_space.shape[0] self.action_dim = env.action_space.n self.create_Q_network() self.create_training_method() # Init session self.session = tf.InteractiveSession() self.session.run(tf.initialize_all_variables()) def create_Q_network(self): # network weights W1 = self.weight_variable([self.state_dim,20]) b1 = self.bias_variable([20]) W2 = self.weight_variable([20,self.action_dim]) b2 = self.bias_variable([self.action_dim]) # input layer self.state_input = tf.placeholder("float",[None,self.state_dim]) # hidden layers h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1) # Q Value layer self.Q_value = tf.matmul(h_layer,W2) + b2 def create_training_method(self): self.action_input = tf.placeholder("float",[None,self.action_dim]) # one hot presentation self.y_input = tf.placeholder("float",[None]) Q_action = tf.reduce_sum(tf.mul(self.Q_value,self.action_input),reduction_indices = 1) self.cost = tf.reduce_mean(tf.square(self.y_input - Q_action)) self.optimizer = tf.train.AdamOptimizer(0.0001).minimize(self.cost) def perceive(self,state,action,reward,next_state,done): one_hot_action = np.zeros(self.action_dim) one_hot_action[action] = 1 self.replay_buffer.append((state,one_hot_action,reward,next_state,done)) if len(self.replay_buffer) > REPLAY_SIZE: self.replay_buffer.popleft() if len(self.replay_buffer) > BATCH_SIZE: self.train_Q_network() def train_Q_network(self): self.time_step += 1 # Step 1: obtain random minibatch from replay memory minibatch = random.sample(self.replay_buffer,BATCH_SIZE) state_batch = [data[0] for data in minibatch] action_batch = [data[1] for data in minibatch] reward_batch = [data[2] for data in minibatch] next_state_batch = [data[3] for data in minibatch] # Step 2: calculate y y_batch = [] Q_value_batch = self.Q_value.eval(feed_dict={self.state_input:next_state_batch}) for i in range(0,BATCH_SIZE): done = minibatch[i][4] if done: y_batch.append(reward_batch[i]) else : y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i])) self.optimizer.run(feed_dict={ self.y_input:y_batch, self.action_input:action_batch, self.state_input:state_batch }) def egreedy_action(self,state): Q_value = self.Q_value.eval(feed_dict = { self.state_input:[state] })[0] if random.random() <= self.epsilon: return random.randint(0,self.action_dim - 1) else: return np.argmax(Q_value) self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/10000 def action(self,state): return np.argmax(self.Q_value.eval(feed_dict = { self.state_input:[state] })[0]) def weight_variable(self,shape): initial = tf.truncated_normal(shape) return tf.Variable(initial) def bias_variable(self,shape): initial = tf.constant(0.01, shape = shape) return tf.Variable(initial)# ---------------------------------------------------------# Hyper ParametersENV_NAME = 'CartPole-v0'EPISODE = 10000 # Episode limitationSTEP = 300 # Step limitation in an episodeTEST = 10 # The number of experiment test every 100 episodedef main(): # initialize OpenAI Gym env and dqn agent env = gym.make(ENV_NAME) agent = DQN(env) for episode in xrange(EPISODE): # initialize task state = env.reset() # Train for step in xrange(STEP): action = agent.egreedy_action(state) # e-greedy action for train next_state,reward,done,_ = env.step(action) # Define reward for agent reward_agent = -1 if done else 0.1 agent.perceive(state,action,reward,next_state,done) state = next_state if done: break # Test every 100 episodes if episode % 100 == 0: total_reward = 0 for i in xrange(TEST): state = env.reset() for j in xrange(STEP): env.render() action = agent.action(state) # direct action for test state,reward,done,_ = env.step(action) total_reward += reward if done: break ave_reward = total_reward/TEST print 'episode: ',episode,'Evaluation Average Reward:',ave_reward if ave_reward >= 200: breakif __name__ == '__main__': main()上面的代码就153行,我在github上加了网络的存储以及训练曲线的显示,代码200行左右!
5 小结
分析代码不是一件容易的事,这里我主要就是介绍编写的流程。具体代码还需要大家去理解吧!相信大家如果看懂了这150行代码,也就很清楚的知道DQN是怎么回事了。谢谢大家!
文章转自:https://zhuanlan.zhihu.com/p/21477488?utm_source=tuicool&utm_medium=referral
- 深度强化学习(DQN)实现CartPole
- 深度强化学习 ( DQN ) 初探
- 深度强化学习 ( DQN ) 初探
- 实现DQN算法玩CartPole
- 深度强化学习初窥之DQN
- 深度强化学习——DQN
- 深度强化学习中的DQN系列算法
- 深度强化学习——DQN
- 论文结果难复现?本文教你完美实现深度强化学习算法DQN
- 论文结果难复现?本文教你完美实现深度强化学习算法DQN
- 强化学习之DQN
- 【DQN】解析 DeepMind 深度强化学习 (Deep Reinforcement Learning) 技术
- 强化学习系列<4>DQN
- 重磅 | 详解深度强化学习,搭建DQN详细指南(附论文)
- 深度强化学习中的NAF算法-连续控制(对DQN的改进)
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
- 【强化学习】DQN(Deep reinforcement learning) Basic
- 强化学习系列:Deep Q Network (DQN)
- C++多态、编译时多态和运行时多态、纯虚函数
- 调试别人bug的小技巧
- 细数代码签名证书的作用
- 困惑多年的组合公式终于明白了!
- Hbase安装部署(伪分布式安装)
- 深度强化学习(DQN)实现CartPole
- MySQL数据库优化
- 陕西中新法律服务中心在西安市正式成立
- 使用远程工具和密钥验证登陆
- 前端编码规范
- dom
- C# typeof() 和 GetType()区别
- http://www.cnblogs.com/sqshine/archive/2009/01/09/1372442.html
- java的split方法的转义字符


