AlphaGo、人工智能、深度学习解读以及应用
来源:互联网 发布:大数据 编辑:程序博客网 时间:2024/05/20 16:44
经过几天的比拼,AlphaGo最终还是胜出,创造了人机大战历史上的一个新的里程碑。几乎所有的人都在谈论这件事情,这使得把“人工智能”、“深度学习”的热潮推向了新的一个高潮。AlphaGo就像科幻电影里具有人的思维和情感的机器人一样,被极大地神话了,而且这让更多的人对人工智能产生了畏惧感。那么,AlphaGo的胜利真的意味着人工智能(AI)已经超越人类了吗? 答案肯定是No。
AlphaGo仍只是个机器,之所以它能够战胜李世石是完全依靠它强大的运算能力和模仿能力,但本身并不具备人类拥有的智慧。面对新的规律、不确定性、更复杂的环境,机器的作用还是有限的。相反,围棋的规则和搜索空间是确定的,不具备任何的不确定性,这也是为什么在这种问题上机器打败人类再也正常不过了。
很不幸的是,AlphaGo的胜利恰恰给很多浮躁的媒体们带来了非常有吸引力但具有误导性的素材,也给不少创业者们带来了一个不切实际的口号。当一个新的技术突破仿佛来临时,我们需要从一个更理性的角度去分析它的影响以及它对一个产业的作用。AlphaGo系统确实很厉害,但在技术上的颠覆还谈不上,从中我们能得到的重要结论是:强大的计算能力和工程能力是搭建优秀AI系统的必要条件。
全球顶尖机器学习专家Max Welling教授(也是我的合著者)对AlphaGo的评价是:
“It reflects the reality that if you want a system to work well you need to hack and engineer your way to good results... but it's awfully good!”
虽然AlphaGo的胜利确实非常振奋人心,但归根结底还是借助于优秀的系统,而不是所谓的颠覆性的“新技术”。我们不得不承认,所谓“真正的人工智能”离我们还非常遥远。当我们能够有勇气正视现状的时候,才能沿着合理的目标前行。
本文主要以科普为目的,力求让读者对AlphaGo的技术、人工智能和深度学习的现状有个比较更清晰的认识。在本文的最后,根据作者在P2P行业的从业经验,简单地举例说明了以目前的技术,人工智能可以在哪些领域里发挥作用。
1. AlphaGo的技术其实很简单
下面来自于自然期刊的论文 [1] 就AlphaGo的技术做了详细的描述,有兴趣的读者可以去细读一下。这篇论文投稿于去年,但公开刊登于今年的年初。我们可以看到论文里长长的作者名单列表,可以看出Google Deepmind为了这项工作确实花了不少血本,而且好几个人都是本领域最顶尖的学者。根据AlphaGo带来的这一波社会效应来看,很明显这些投入还是非常值的!
最近几天,我看到了几篇讲解AlphaGo技术的文章 [2] [3],虽然都写得很不错,但还是过于抽象化。另外,一位卡耐基梅陇大学博士生整理的关于AlphaGo的讲解比较清楚 [9],本文也参考了它那种解释问题的方式。总之在本文里,我会试图用更简单通俗的方式把AlphaGo的核心思想呈献给读者。
 最近几天,我看到了几篇讲解AlphaGo技术的文章 [2] [3],虽然都写得很不错,但还是过于抽象化。另外,一位卡耐基梅陇大学博士生整理的关于AlphaGo的讲解比较清楚 [9],本文也参考了它那种解释问题的方式。总之在本文里,我会试图用更简单通俗的方式把AlphaGo的核心思想呈献给读者。
最近几天,我看到了几篇讲解AlphaGo技术的文章 [2] [3],虽然都写得很不错,但还是过于抽象化。另外,一位卡耐基梅陇大学博士生整理的关于AlphaGo的讲解比较清楚 [9],本文也参考了它那种解释问题的方式。总之在本文里,我会试图用更简单通俗的方式把AlphaGo的核心思想呈献给读者。1.1 AlphaGo在技术上没有太多新意
首先,AlphaGo的胜利是不是意味着AI技术有了突破性的进展? 答案是否定的。其实,AlphaGo在算法层面上并没有太多新的东西,主要是通过把已有的技术整合在一起,并利用大量的训练数据和计算资源来提高准确性。归根结底,强大的计算平台和工程能力是核心。
下面的图表示AlphaGo主要用到的核心技术(这种组织方式可能并不完全准确,主要是为了更清楚地表达核心思想)。按照官方的定义,机器学习分为监督学习、无监督学习和强化学习,AlphaGo就用到了其中的两大块 - 监督学习和强化学习。类似的,AlphaGo用到了启发式搜索算法的一种 - 蒙特卡罗树搜索算法。这个算法是在一般AI游戏系统里非常常见。另外,深度学习模型里的深度卷积神经网络(DCNN)和优化里的一阶方法一起构成了AlphaGo的核心组件。当然,所有这些模块离不开Google强大的计算平台(CPU/GPU群)和强大的工程师团队。

1.2 为什么围棋的人工智能这么难?
这类人工智能问题的核心在于搜索。最简单粗暴的方法其实就是把所有的可能性罗列出来,然后从中选出最优的方案;比如在围棋的世界里,当我们知道每下一步走子带来的胜利的(精确的)概率时,这个问题其实就很容易解决。但不幸的是,在围棋的世界里这种“可能性”太多,用更准确的语言描述就是 - 搜索空间过于庞大。
举个简单的例子,给定一个棋盘,假设每次能投放的位置有30个且游戏持续了共50步,如果把所有的可能性罗列出来这数字近似于30的50次方。即使利用再多的硬件资源,把每种可能的情况都做一遍验证是不现实的。所以AlphaGo的核心技术就是在解决这样一个难题: 避免穷举这些所有的可能性,而是利用更聪明的方式(比如近似)来找到那些有可能促使胜利的策略(Strategy)。
1.3 AlphaGo简单的原理
假设白色棋子代表人,黑色棋子代表机器。对于给定的棋盘局面,训练出来的AlphaGo每次都会试图去选择最好的走子方案 a (也成为action),而且这种最优方案会让机器有更大的可能性获得胜利。在这里,我们假定S1为棋盘的初始状态,S2为AlphaGo选择走子方案a之后的状态。通过一系列的actions, 棋盘的状态会逐步变化:S1 -> S2 ->.... > SN...

如前所示,简单粗暴的方法就是评估所有的可能性,其实就是判断每一步走子带来的胜利的概率。需要注意的是,这不仅仅要考虑眼前的一步,还要考虑到游戏结束为止走过的所有的步子,这好比优秀的围棋选手会比其他选手能够多考虑接下来的几步。
如下图所示,当一个选手把白色棋子放在棋盘上的时候,对于机器来说它有80种可能的走子方案(9*9-1),这称之为广度(Breadth)。请注意,真实棋盘是19*19。还有,作者对围棋的规则不了解,如果在例子中有些不切实际的地方,请不要太在意。
 如下图所示,当一个选手把白色棋子放在棋盘上的时候,对于机器来说它有80种可能的走子方案(9*9-1),这称之为
如下图所示,当一个选手把白色棋子放在棋盘上的时候,对于机器来说它有80种可能的走子方案(9*9-1),这称之为
机器确认了下一步走子方案的时候,选手就可以选择剩下的79种走子方案。很容易看出,仅仅简单的两步就共产生了80*79种不同的组合。所以可以想象,当一个游戏的长度为N的时候(也称之为深度Depth),考虑所有的可能性是不现实的。细心的读者可以很容易注意到,总的可能性数目依赖于前面所提到的广度和深度。据说,这个数量级超过了整个宇宙中原子的数目。
所以我们的目标就是要降低搜索空间的大小(Reduce the search space)。既然搜索空间的大小依赖于搜索的广度和深度,我们的子目标就变得非常明确:就是要降低广度和深度。论文里提出的走棋网络(Policy Network)和估值网络(Value Network)其实就是可以用来减少广度和深度。另外,蒙特卡罗树搜索(Monte Carlo Tree Search)把上面几项技术整合在一起并帮助构建完整的AI系统。在论文中,作者还提到了快速走子(Fast rollout)的方法,但思想跟走棋网络类似,目的是为了极大地提高效率,在本文中不会过多地去介绍。
走棋网络(Policy Network)
走棋网络的目的是为了减少广度(Breadth)。也就是说,对于一个给定的棋盘状态,我们要尽量把需要考虑的范围减少,同时也要考虑最优的走子方案。如下图所示,通过走棋网络我们可以只选择可能性较大的走子方案,而不去考虑剩下的方案。从数学的角度来讲,对于给定的一个棋盘状态S,先计算概率分布p(a|S), 然后从中选择最为合理的走子方案。
剩下的问题就变得很直观:用什么方法来计算p(a|S)? 答案就是用深度神经网络! AlphaGo系统会从已有的比赛历史中去学习顶级高手的走子方案。也就是说,给定一个棋盘状态,AlphaGo会试图去模仿专家的走法,并判断哪中走法最有利。
 剩下的问题就变得很直观:用什么方法来计算p(a|S)? 答案就是用深度神经网络! AlphaGo系统会从已有的比赛历史中去学习顶级高手的走子方案。也就是说,给定一个棋盘状态,AlphaGo会试图去模仿专家的走法,并判断哪中走法最有利。
剩下的问题就变得很直观:用什么方法来计算p(a|S)? 答案就是用深度神经网络! AlphaGo系统会从已有的比赛历史中去学习顶级高手的走子方案。也就是说,给定一个棋盘状态,AlphaGo会试图去模仿专家的走法,并判断哪中走法最有利。深度神经网络的一种 - 深度卷积神经网络(DCNN)用来做这件事情。DCNN是图像识别领域里最为常用的模型。在图像识别应用里,DCNN的输入为一幅图片,它的输出为图像的分类。类似的,在AlphaGo系统里,DCNN的输入是一个棋盘(可以把棋盘看做是一幅图,棋盘上的黑子和白子分别可以用1和-1来表示,剩下的空位置可以用0来表示),其实相当于一个矩阵。它的输出就是不同走子方案的概率分布,然后基于这个分布,可以做下一步的决策。
 深度神经网络的一种 - 深度卷积神经网络(DCNN)用来做这件事情。DCNN是图像识别领域里最为常用的模型。在图像识别应用里,DCNN的输入为一幅图片,它的输出为图像的分类。类似的,在AlphaGo系统里,DCNN的输入是一个棋盘(可以把棋盘看做是一幅图,棋盘上的黑子和白子分别可以用1和-1来表示,剩下的空位置可以用0来表示),其实相当于一个矩阵。它的输出就是不同走子方案的概率分布,然后基于这个分布,可以做下一步的决策。
深度神经网络的一种 - 深度卷积神经网络(DCNN)用来做这件事情。DCNN是图像识别领域里最为常用的模型。在图像识别应用里,DCNN的输入为一幅图片,它的输出为图像的分类。类似的,在AlphaGo系统里,DCNN的输入是一个棋盘(可以把棋盘看做是一幅图,棋盘上的黑子和白子分别可以用1和-1来表示,剩下的空位置可以用0来表示),其实相当于一个矩阵。它的输出就是不同走子方案的概率分布,然后基于这个分布,可以做下一步的决策。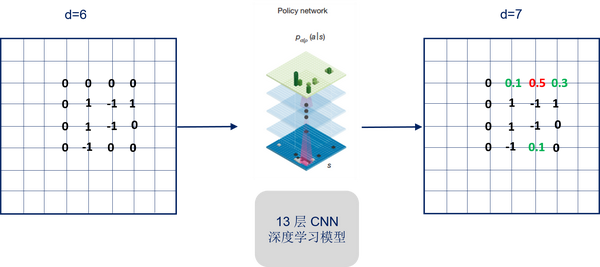
为了达到训练的目的,AlphaGo需要大量的训练样本,样本就是职业玩家的比赛记录。训练好的模型就可以用来模拟高手似的走法。整个样本的训练过程需要大量的计算资源,幸好这是Google的优势。然而,AlphaGo并没有停留在这一步,而是接着用强化学习(Reinforcement Learning)的方式来进一步提高系统的性能。
在这里,强化学习主要用来搜集更多的样本,从而提高系统的准确率。他们的做法很简单,就是把训练出来的模型俩俩做对抗,根据比赛的结果再更新模型的参数。所以这是机器和机器之间的较量,这种迭代会反复很多次。
如下图所示,通过这种迭代,最初的模型v1.0最后可能演变成了模型v1099。按照论文中的说法,这种通过不断地自我提升训练出来的模型在大部分情况下会胜出最初的专家模型。

估值网络(Value Network)
除了走棋网络,AlphaGo还采用了估值网络,这是一项锦上添花的技术,但并不是什么新的技术。从下面的表格中可以看出即使没有估值网络,AlphaGo的实力也不会太弱,至少在7d-8d之间的水平 [2]。但是相反的,如果没有走棋网络,AlphaGo的实力会大大折扣。

简单地讲,估值网络是用来计算每种棋盘状态的“价值”。在这里,所谓的价值可以理解成胜负的概率,可以用0-1之间的数字来表示。
如图所示,当我们有不同选择的时候,可以去计算每一种选择之后的棋盘状态的分值,比如可以用V(S1), V(S2), V(S3)来表示。所以,我们的目标再次变得很清楚,也就是给定一个棋盘的状态S,计算出胜负的概率,这部分恰恰又是归功于深度学习网络。

为了搜集足够多的样本,AlphaGo采用了随机走子的方法。但在这里,生成样本是有讲究的,每一盘棋只取一个样本来训练以避免过拟合 [2]。原因很简单: 对于同一盘棋,不同输入(相似)都会产生同一个输出。这也是为什么论文提到了需要三千万局这种庞大的样本的原因。具体怎么做随机走子,可以参考论文。
有了样本,我们就可以做模型的训练。在这里,我们同样地用到了深度卷积神经网络。过程非常类似于训练走棋网络,所以就不多说了。模型的输出就是一个棋盘状态的估值(Value)。

有了走棋网络和估值网络,剩下的就要看怎么把它俩结合起来用。具体的效果请参考上面的表1。表里的lambda值决定两者之间的权重。
蒙特卡罗树搜索(Monte Carlo Tree Search)
蒙特卡罗树搜索算法在AI游戏系统里非常常见。在AlphaGo里,它用来把各个部分整合在一起。由于这是一个比较经典的AI算法 [4],在文本中不多做介绍。其实,光从名字就可以猜到它的作用是什么。这种算法用到了随机性,并会不断地去采样,然后利用采样的结果来近似地描述我们的目标。
作为简单的科普,怎么理解蒙特卡罗? 举个很简单的例子(只是为了说明大概的思想,不一定很恰当),比如我们想统计全国人口的平均身高,这时候最粗暴的方式就是把国内所有人的身高都测量一遍,然后计算它们的平均值。但如果根据蒙特卡罗的思想,我们其实可以在每个省份去采样一部分人群,然后用这部分人群的平均身高值来代替全国的平均身高值。所以自然地,当我们采样的样本数量增多时,就会变得越准确。

怎么才能在人机大战中赢得胜利?
下棋本身就是一种博弈的过程,其中充满了挑战。我们看到了AlphaGo连连击败李世石,虽然后者也赢回了一场比赛。这使得很多人开始相信了机器智能超过了人类。然而,AlphaGo只不过是在模拟专业围棋选手的走子方案,而且这种模拟依赖于历史比赛的记录。
怎么才能在面对AlphaGo的比赛中获得胜利呢? 答案其实很简单: 就是尝试走一些不同寻常的棋,而且这种走法很少出现在专业比赛当中。要知道, AlphaGo的学习都是基于历史比赛记录的,如果有一部分走子方法没有被这些历史记录覆盖到,那AlphaGo就很难有效地去应对。相反,如果按照常规的走法,那人胜出的概率会大大折扣,毕竟人在罗列和计算上还是比不过机器的。我相信不少专业棋手看到跟AlphaGo的比赛之后,都忍不住去跟它切磋一下,只要能够有效地做出一些不同寻常的走法,赢得比赛还是有可能的。
2. 深度学习到底是什么?
在AlphaGo的系统里,我们用到了走棋网络和估值网络,并且两个网络都用到了深度学习的技术。既然深度学习这么强大,它是不是意味着一个崭新的人工智能时代的到来? 不完全否定,深度学习的确很大程度地推动了人工智能的发展,它使得图像识别,语音识别这种核心领域得到突破性的进展。这也难怪,在学术圈子里逐步形成了 “深度学习“和“非深度学习”两个派别。但是不得不承认,它的发展目前仍然处于初级阶段,离我们想象中的智能还非常得遥远。
2.1 深度学习是什么?
虽然很多人听说过深度学习,但发现很少人真正理解什么是深度学习。有很多媒体吹捧深度学习就是用来模拟人的大脑,从而实现所谓的人工智能。但很遗憾的是,我们离真正的智能还很遥远。作为一个从事AI领域的科技工程师和学者,我对人工智能本身报有很大的期望,但很清楚这需要一个漫长的过程。另外,把深度学习说成模拟大脑过于夸张,我觉得即便是神经科学家,他们对大脑运行机理的理解也不那么清楚。
还有一个问题,人工智能、机器学习、深度学习的关系又是怎样呢? 下面的图仅代表作者的观点。我们所说的人工智能的范围很广,机器学习是一门用来实现人工智能的核心技术,并且深度学习是机器学习中的一个子分支。
 还有一个问题,人工智能、机器学习、深度学习的关系又是怎样呢? 下面的图仅代表作者的观点。我们所说的人工智能的范围很广,机器学习是一门用来实现人工智能的核心技术,并且深度学习是机器学习中的一个子分支。
还有一个问题,人工智能、机器学习、深度学习的关系又是怎样呢? 下面的图仅代表作者的观点。我们所说的人工智能的范围很广,机器学习是一门用来实现人工智能的核心技术,并且深度学习是机器学习中的一个子分支。
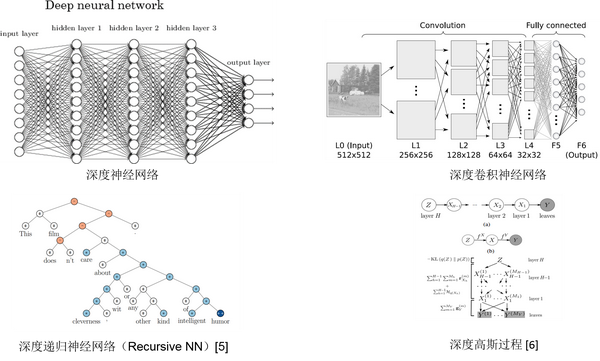
另外,所谓的深度学习是否特指某一种算法,比如深度卷积神经网络? 我的理解是,深度学习并不是特指某种机器学习算法或模型,而更像是一种方法论、思想和框架。它主要是以构建深层结构(deep architecture) 来学习多层次的表示(multiple levels of representation)。 比如很多算法都可以用来构建这种深层次结构,这些包括深度神经网络,深度卷积神经网络,深度递归神经网络(Recursive/Recurrent)等等。除了下面提到的一些深度学习模型,比如像深度强化学习(Deep Reinforcement Learning)在Robotics领域也很受欢迎。

2.2 深度学习为什么最近才流行?
其实构建多层次结构的想法在20多年前就已经有过。然而,由于种种原因,这种想法未能在当时取得理想的效果。那究竟是哪些改变把这门“旧学科“推向了一个新的风口? 总结起来,大概有几个原因:
硬件上的提高。深度学习模型需要大量的样本,这就避免不了大量的计算。然而,以前的硬件设备不足以训练出复杂的深度学习模型。目前,这种模型基本上都需要GPU技术的支持。
更多的数据。正是大数据有效地推动了深度学习的发展。
更有效的训练方法。这就要归功于无监督预训练(unsupervised pre-training)和dropout。尤其,无监督预训练是深度学习发展历史上的一个里程碑似的发现。因为有了它,模型才能够得以更有效地训练出来,使得准确率大幅提升。
对于无监督预训练和dropout技术,读者可以去参考相应的文献,在这里就不多做介绍。总之,现在我们拥有的大规模计算平台和大数据是促使深度学习发展的非常重要的因素!
2.3 深度学习的优势在哪里?
既然我们说到深度学习是一种构建多层次结构的框架,那自然而然的,我们会跟传统的机器学习模型做对比,我们可以称其为浅层模型(Shallow Model)。那深度学习跟浅层模型比有什么优势呢? 不少人会人为深度学习只不过是一层一层的叠加,除此之外没有什么太大的区别。但事实不是这样的,可以从几个方面说起。部分涉及到的技术点较多,如果对这部分理论不感兴趣,读者可以勇敢地跳到下一章节。
分布式表示(Distributed Representation)
这是深度学习模型最为重要的性质。举一个非常简单的例子,假设我们的词典上有16个单词,如果用传统的bag-of-words 的表示方法,我们可以用16维的向量来表示每个词,向量的每一位代表某个词的出现与否。然而,如果我们用分布式表示的思想,则也可以用四维的向量来代表每一个词,例如 (0,0,0,1), (0,0,1,0),..., (1,1,1,1) 。 通过这个例子,我想说明的一点是:对同一个输入,我们可以有不同的配置(configuration)。但具体哪种方式更好呢?
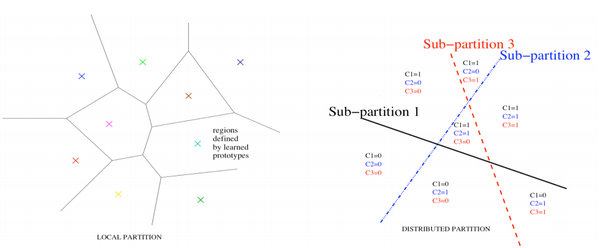
再举一个稍微复杂的例子,这是Bengio教授经常拿出来讲的例子。下面两幅图表示两种聚类的表达方式。我们可以把左图看成是一般的聚类方式,右图看成是基于分布式表示的聚类方式。在左图里,我们把整个空间分成了几个区域,每一个区域由一组参数来描述(characterize),所以我们共需要9组参数。 与此相比,在右图中,每一个区域由三个子模块来表达。 这个时候我们只需要三组参数,而且每一个区域都会共享这三组参数, 被称之为参数共享(parameter sharing)。 这个性质带来的一个重要的优点是 -- 非局部泛化(non-local generalization). 我们要知道机器学习的目的就是要在测试集上(test set)得到更好的泛化(better generalization)效果 。 在左图中,我们只能得到局部泛化(local generalization), 即便这样,为了达到局部泛化的目的,我们需要对每个区域有足够多的样本(training examples)来学习参数。除此之外,分布式表示可以有效地应对curse of dimensionality问题 。
学习多层次的表示(Multiple Levels of Representation)
这类似于人的大脑:人们总是先学到简单的概念(concept), 然后以这个为基础,不断地去学习更为复杂和具体(concrete)的概念。
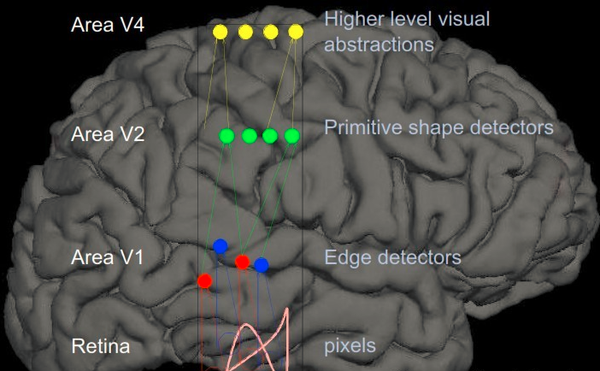
如下图所示,当我们把深度学习应用在图像时,第一层学出来的是各种滤波器(filter), 第二层学出来的是脸部的某一个部位,最上层(第三层)就已经可以学出具体的人脸了。 整个过程,从下到上,就是在不断地学习更为具体特征的过程。

自动学习特征
使用这种多层次结构可以帮助避免繁琐的人为特征设计(feature engineering)过程。在传统的图像识别方法里,我们首先要做的就是从图片中提取有效的特征(这些都是人为设计的),但问题是对于不同类型的识别任务,我们需要人为地去设计不同类型的特征,这就导致整个的过程非常繁琐。然而,在深度学习框架下,我们的输入就是图片的每个像素,并不需要做人为的特征提取 (当然,必要的预处理还是要做的)。
2.4 深度学习有多强大?
目前深度学习在图像识别和语音识别上得到了不错的发展,也有不少专家非常看好在自然语言处理上的发展。但个人而言,自然语言处理上的成果还是比较初级的。自然语言处理领域里,自动问答可能是很多人想去攻克的问题,因为它的应用面很广比如智能助手等。但遗憾的是,目前的技术还不足以构建通用性的问答系统。对于某一个垂直领域,简答的事情上还是可以实现自动化的。除了这些领域,深度学习在金融和医疗上也受到越来越多的关注,但相比图像识别这种应用,发展还是比较缓慢一些。
至于深度学习有多强大,我只能说目前能够满足日常生活里非常基础的智能化需求。但想达到那种科幻片里的效果,还是非常遥远的。并且我们对深度学习最根本原理的理解也不够透彻。
3. 金融上的应用
讲了很多技术方面的东西,接下来我们就简单地分析一下在金融行业里,深度学习这种AI技术能起到什么样的作用。虽然深度学习等技术不是什么传奇的工具,但如果能够正视技术的本质和可行性,其实有不少应用点是可以考虑进来的。本人在写这篇文章时在P2P行业里仅仅待满半年,所以也有可能在某些地方说得不切实际。如有疑问,请及时通知作者,尽快修正。
3.1 风险评估模型
它已成为消费信贷领域里最为重要的工具。通过评分模型的结果,我们可以对客户做借贷与否的决定,对各户的分类以及相应的授信。大部分模型都是基于用户本身的一些基本的变量,通过简单的机器学习算法比如逻辑回归(Logistic Regression),决策树(Decision Tree),随机森林(Random Forest)等,或者用他们的组合模型来做判断。在传统的风险评估模型里,用到的变量数目并不多(基本都是强变量),所以这种简单的模型也能够满足基本的需求。然而在P2P行业里,我们能够直接获取到的用户的历史数据有限,这跟传统的银行贷款是有区别的。
在P2P行业里,除了那些基本的强变量,我们也会去使用很多的弱变量来帮助做决策。这种弱变量来源多样化,有些来自用户的行为数据,有些来自用户的浏览记录... 这些强变量和弱变量组合在一起就构成了一个高维的特征向量,它们之间存在着非常复杂的非线性关系。这些条件使得深度学习模型在风险评估上拥有独一无二的优势。
但是很难有两全其美。由于深度学习模型本身较差的可解释性,训练出来的模型在很多使用方的眼里是个黑盒子。
3.2 反欺诈
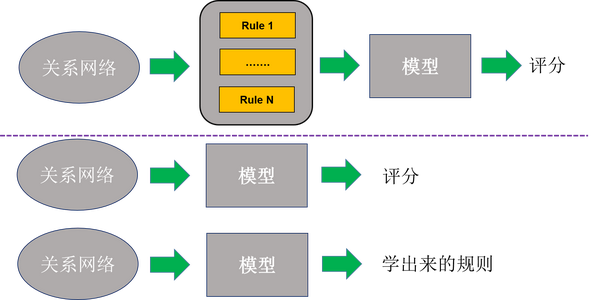
反欺诈一直是风控里最为重要的环节。 特别在复杂的国内市场的环境下,减少欺诈风险是对每一个金融公司来说尤其得重要,并且传统的反欺诈手段很难再适用于P2P这种新型行业,我们不得不用更先进的手段去发现欺诈风险。很多欺诈风险隐藏在复杂的关系网络里,所以分析这种网络变得格外必要。
行业里,最常用的做法就是从已有的关系网络里人为地去提取欺诈规则,然后根据这些规则的结果给出最后的欺诈评分。这种工作不仅需要敏锐的头脑和想象力,还需要充分的数据验证过程和业务知识。欺诈其实也是个博弈的过程,作为风控方,我们需要不断地去修改反欺诈手段来迎合变化多端的欺诈风险。这不得不让风控团队不断地去设计和部署新的规则。然而,整个过程非常耗时,而且需要全程的人为干涉。我们想做的是一种全自动化的手段,就是不通过规则的提取而直接使用模型来准确地给出一个欺诈评分,或者让机器自动提取出一些反欺诈规则。这部分工作需要依靠深度学习模型,但前提条件是有足够多的数据,包括丰富的关系。
3.3 用人工智能来取代分析员的工作
最近,很多人在讨论美国一家比较有意思的公司,叫做Kensho。这是一家金融人工智能公司。它的目的很简单,就是要让机器完成分析师的工作,如果这个能够实现,这将是颠覆性的。举个简单的例子,比如一个新的事件a发生,如果机器能够快速地把跟事件a相关的信息关联出来,这将会减少分析师大量的工作。再比如,如果机器能够准确地判断股票升跌之间的关系,这也将对股民是一个非常有价值的信息。
然而,实现这些功能,需要克服以下几个难点:
海量文本的挖掘。这里包括各大新闻、财经类网站、论坛、财务报表等。其实最大的难点在于信息的自动关联以及相关性强度的判断。这部分需要强大的自然语言处理(NLP)技术来做支持,在这方面,深度学习是一个很好的选择。
数据稀疏性的处理。很多事件在历史上发生的次数并不多,比如空难等。这种历史数据的不足会使得系统的性能有所折扣。在这种情况下,怎么把其他相关的信息结合在一起显得非常得重要。
相关性的推理。当我们得到一个完整的因果关系网络以后,就可以用推理的手段去进一步去丰富它。举个例子,比如股票A影响股票B的价格波动,股票B影响股票C的价格波动,那我们自然而然地去问股票A跟C的相关性有多大。 在关系推理的工作上,深度学习也得到了不错的进展。
关系的量化其实这是一个很难的问题,就是如何量化某一个关系。我们从文本中不难挖掘A和B之间是否有因果关系,但却很难定义他俩之间的量化程度。还有就是,当把这些量化指标结合到因果关系网络里的时候,推理也会变得更难。
3.4 舆情分析
通过一些网上的新闻或论坛里发表的帖子来判断对某一件事情的舆情是很有帮助的。人们常常讨论用它来做股票的预测,具体效果好不好,因为我还没有亲自做过调研就不多讲了。还有一个最常用的应用就通过对产品舆情的监控来判断消费者的满意程度以及对产品的建议。对一个公司来说,这种信息是非常有价值的。
基于文本的舆情分析并不是一个新的问题。早在10多年前很多人就开始探讨这个问题。随着深度学习的发展,基于深度学习的舆情分析技术也受到了不少关注,在预测的准确率上也有所提高。所以,我还是比较看好深度学习在舆情分析领域里的作用。
3.5 高频交易
很多人觉得人工智能在长期的投资上帮不了什么忙,这个我比较同意,毕竟金融市场随机性太大。但在高频交易上,它还是能够帮上很多忙的。但纵观深度学习的发展,它在这些领域里的应用还是有限的,至少我还没有看到过太多这方面的案例。但鉴于深度学习逐步进入医疗领域等迹象,我还是比较看好高频交易上的应用。
4. 结语
写了这么多,主要还是为了介绍目前人工智能的现状,能让读者对这个领域有个更清晰的认识。总的来说,虽然AlphaGo的结果很振奋人心,但它毕竟不是什么颠覆性的新科技,只是把已有的技术以更好的方式组织在一起并做出了一套智能化的系统。机器在棋牌上胜过人类一点都不奇怪,因为这些问题都是有着明确的规则和有限的搜索空间,就看谁能够更快地找到最优解罢了。
然而,在现实生活里,很多的问题充满着噪声和随机性,比如股价的波动、自动驾驶需要面对的复杂的路况等等。目前的AI技术离真正的AI还非常遥远,推动这项工程需要工业界和学术界人士的紧密的合作。
对于工业界应用来说,其实最重要的就是要正视目前的技术能力和瓶颈,从而提出更加合理的应用场景和产品设计方案。
参考文献
[1] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[2] 田渊栋 AlphaGo的分析 AlphaGo的分析 - 远东轶事 - 知乎专栏
[3] Dan Mass. How AlphaGo works. How AlphaGo Works
[4] Monte Carlo tree search
[5] Socher, Richard, et al. "Recursive deep models for semantic compositionality over a sentiment treebank." Proceedings of the conference on empirical methods in natural language processing (EMNLP). Vol. 1631. 2013.
[6] Damianou, Andreas C., and Neil D. Lawrence. "Deep gaussian processes."arXiv preprint arXiv:1211.0358 (2012). *
[7] van den Oord, Aaron, and Benjamin Schrauwen. "Factoring variations in natural images with deep gaussian mixture models." Advances in Neural Information Processing Systems. 2014.
[8] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." Science 313.5786 (2006): 504-507.
[9] How AlphaGo Works
- AlphaGo、人工智能、深度学习解读以及应用
- AlphaGo:人工智能与深度学习
- 【深度】专业解读“深度强化学习“:从AlphaGo到AlphaGoZero
- 深度解读 AlphaGo 算法原理
- 深度解读 AlphaGo 算法原理
- 深度 | David Silver全面解读深度强化学习:从基础概念到AlphaGo
- 深度 | David Silver全面解读深度强化学习:从基础概念到AlphaGo
- 深度学习之google deepmind的alphago AI人工智能算法技术演变历程
- 深度学习之Google Deepmind的alphago人工智能算法技术演变历程
- 无先验从零开始深度学习AlphaGo zero
- 深度学习(人工智能)
- 深度学习的应用以及初识Tensorflow
- AlphaGo算法框架解读
- 随想:人工智能与深度学习
- 人工智能+Python深度学习是什么?
- 深度学习开篇简介-人工智能
- 什么是人工智能、机器学习、深度学习、数据挖掘以及数据分析?<一>
- 什么是人工智能、机器学习、深度学习、数据挖掘以及数据分析?<二>
- 测试二2
- virtualBox挂载文件夹
- jsp 自定义标签
- HDFS 读取、写入、遍历目录获取文件全路径、append文件创建或者写入报错问题分析
- Axure编写产品需求书PRD最佳实践
- AlphaGo、人工智能、深度学习解读以及应用
- 线程5种状态及常见问题
- php调用python
- lombook插件安装
- netstat查看正在监听的端口
- android RSA非对称式加密
- MyBatis学习总结(一)——MyBatis快速入门
- 幸运的编号
- C语言中static关键字的作用


