MATLAB资料结论
来源:互联网 发布:c语言中flag该怎么用 编辑:程序博客网 时间:2024/04/28 04:00
第五章 資料結構
5.1資料型式
在MATLAB中,其基本資料型式約有十五種,每種均可以陣列與矩陣表示。有些前面已經使用過,有些則屬使用者定義的範圍。一般的資料型式除整數,有單精度、雙精度、邏輯值、字母、細胞陣列、結構、函數握把值等等,視需要而定。數值的表示法則有整數、浮點、複數等等。對於任意數值屬於何種型式則可利用class函數進行檢驗,在指令窗中亦可利用whos函數顯示其大小與型式。
0 意見 ![]() 此文章的連結
此文章的連結
5.2多維陣列
5.2Multi-Dimensional Arrays
一般的矩陣多探討兩維。三維陣列雖僅增加一個維數,但型式就複雜許多。二維陣列以行、列表示,故在標示上,僅有兩個下標,如A(3,4)即為列3行4的表示法。若增加一維,則必須再增一個下標位置。而其所代表的意義變成另一層,而不是行列的觀念,增加之層次通常以頁數(pages)表示之。故A(3,4,1)變為第一頁,而A(3,4,2)為第二頁。其前兩標仍維持二維之行列觀念,故A(3,4,1)表示第一頁第三列第四行之元素,而A(3,4,2)表示第二頁第三列第四行之元素。
若要指出第一頁或第二頁所有的元素,則可以使用冒號代表。如A(:,:,1)、A(:,:,2)是。
>>A(:,:,1)=[1 2 3;4 5 6;7 8 9]; %第一頁輸入,結果不顯示
>>A(:,:,2)=magic(3) %第二頁輸入,並顯示整個矩陣之結果
>>A(:,:,1) =
1 2 3
4 5 6
7 8 9
>>A(:,:,2) =
8 1 6
3 5 7
4 9 2
輸入第一頁時其頁數可以省略,處理其餘頁數時則必須標明。通常要觀察一個多維矩陣之維數,可用ndims或size函數,只是兩個結果之表示法略有不同,例如:
>>ndims(A)
ans = 3
>>size(A)
ans = 3 3 2
多維矩陣之形成,亦可利用另一個函數cat(dim, C, D,…)進行增減,cat又稱為串接指令,可以將許多小矩陣依dim維度之安排進行組合。dim參數即表示所要做的矩陣維數。當dim=1時,表示產生一個[C;D]疊加的行向矩陣;dim=2時,則產生一個[C D]疊加的列向矩陣;而dim=3時,則產生一個分別由C與 D各佔一頁的三維矩陣。例如:
>>c=[1 2;3 4], d=[5 6;7 8]
c =
1 2
3 4
d =
5 6
7 8
>>cat(1,c,d)
ans =
1 2
3 4
5 6
7 8
>>cat(2,c,d)
ans =
1 2 5 6
3 4 7 8
>>cat(3,c,d)
ans(:,:,1) =
1 2
3 4
ans(:,:,2) =
5 6
7 8
在組成多頁之多維系統時,基本上其大小應一致,否則無法搭配。以下面之列為例,在第三維中,其二維之大小必須相同:
>>A=cat(3,[9 2;6 5],[7 1;2 8])
A(:,:,1) =
9 2
6 5
>>A(:,:,2) =
7 1
2 8
>>A=cat(3,[9 2 4;6 5 3],[7 1 2;2 8 4])
A(:,:,1) =
9 2 4
6 5 3
A(:,:,2) =
7 1 2
2 8 4
>>B=cat(3,[3 5;0 1; 1 4],[5 6;2 1;2 8])
B(:,:,1) =
3 5
0 1
1 4
>>B(:,:,2) =
5 6
2 1
2 8
若三維仍然不足,必須增加為四維時,則必須增加一個表示第四維之下標。在置放時,其第三維除非特別說別,均設為1,而其餘矩陣則依第四維之順序置入,亦即所輸入之資料是置於第三維之第一頁中:
>>C=cat(4,[4 2;6 5],[5 8;8 2])
C(:,:,1,1) =
4 2
6 5
C(:,:,1,2) =
5 8
8 2
>>C=cat(4,[1 2 5;4 5 7],[7 8 0;3 2 9])
C(:,:,1,1) =
1 2 5
4 5 7
>>C(:,:,1,2) =
7 8 0
3 2 9
若M與N為兩三維矩陣,今擬置於另一四維矩陣中時,其結果如下:
>>D=cat(4,A,B,cat(3,[1 2;3 4],[4 3;2 1]))
>> A=cat(3,[1 1;2 2],[3 3 ; 4 4])
A(:,:,1) =
1 1
2 2
A(:,:,2) =
3 3
4 4
>> B=cat(3,[11 22;33 44],[44 44;55 55])
B(:,:,1) =
11 22
33 44
B(:,:,2) =
44 44
55 55
>> D=cat(4,A,B,cat(3,[7 7; 8 8],[ 9 9; 2 2]))
D(:,:,1,1) =
1 1
2 2
D(:,:,2,1) =
3 3
4 4
D(:,:,1,2) =
11 22
33 44
D(:,:,2,2) =
44 44
55 55
D(:,:,1,3) =
7 7
8 8
D(:,:,2,3) =
9 9
2 2
其中,D(:,:,:,1)是置放M矩陣;D(:,:,:,2)是置放N矩陣;而D(:,:,:,3)則置放後面所串接之矩陣,其維數可以檢測如下:
>>ndims(C) = 4
ans = 4
要取出其中之陣列應用時,必須在整數的指標指到其對應之陣列,例如:第四層中之第二頁、第三層中之第二頁之第一列第二行為:
>>D(1,2,2,2)
ans = 6
>>D(1,2,2,3)
ans = 3
>>D(1,2,1,2)
ans = 5
為方便起見,超過二維之多維部份亦可用指標向量指向其頁數矩陣:
>>k=D(:,:,1,[1 3])
k(:,:,1,1) =
9 2
6 5
k(:,:,1,3) =
1 2
3 4
1 意見 ![]() 此文章的連結
此文章的連結
5.3細胞陣列
5.3Cell Array
細胞陣列與其他矩陣之情況略有不同,它在同一個陣列名稱下,儲存不同類型的資料陣列,諸如字串、文字、數值、複數、正整數陣列等,由於陣列之維數也容許不同,其應用的範圍更具彈性。有關細胞陣列之指令如下表:
產生細胞陣列可利用指定陳述法,或用cell指令先安排細胞陣列之大小,然後再將資料移轉至各細胞存放。指定陳述法係將資料直接指定給特定細胞元素,一次一個。 MATLAB 將自動建立對應之細胞陣列。
將資料指定給某特定細胞有兩種方式:即細胞索引(cell indexing)與內容索引(content indexing)。細胞索引是先在等號左邊以下標說明細胞之位置,並且用一般標準的括符()括起來,如A(2,3)是;而等號之右邊則必須將所要設定的內容利用大括等{}括起來,表示該位置所設定的內容。例如為產生一個2 x 2的細胞陣列A:
>>A(1,1) = {[3 4 5; 1 5 7; 3 5 4]};
>>A(1,2) = {'馮丁樹'};
>>A(2,1) = {2:3:11};
>>A(2,2) = {-5+4j};
>>A
A =
[3x3 double] '馮丁樹'
[1x4 double] [-5.0000+ 4.0000i]
由這裡可以看出,產生一個細胞陣列可以如一般的矩陣指定方式一樣,將內容逐一填入。由於細胞陣列A之內容格式可能不一,故任何資料均可存放。此外,細胞中若為矩陣,則僅以矩陣之大小及數值內容表示。要注意的是等號右邊需用大括符,不能使用矩陣的中括符。而{}表示為空集合,是一種合法的型式。若要知道其實際內容,可以使用celldisp指令:
>>celldisp(A)
A{1,1} =
3 4 5
1 5 7
3 5 4
A{2,1} =
2 5 8 11
A{1,2} =馮丁樹
A{2,2} = -5.0000 + 4.0000i
此時所有內容均可以列出。若要以圖示表示此細胞陣列之相關位置,亦可使用cellplot指令,這是一個繪圖式指令。它會將各細胞之元素用圖表示出,但矩陣之內容仍不顯示。
>>cellplot(A)
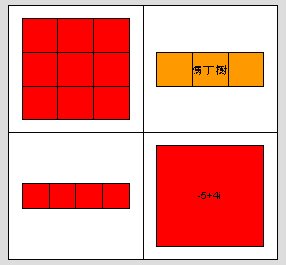
內容索引則是在等號左邊以大括符定其位置,在等號右邊則置入實際之內容。其方式如下:
>>A{1,1} = [3 4 5; 1 5 7; 3 5 4];
A{1,2} = '馮丁樹';
A{2,1} = [2:3:11];
A{2,2} = -5+4j;
>>A
A =
[3x3 double] '馮丁樹'
[1x4 double] [-5.0000+ 4.0000i]
結果相同。換言之,在設定時,大括符僅能使用一次,不是在等號之左邊,就是在右邊。若所設定的資料位址超過原來的範圍,該細胞陣列會自動擴張,以配合需求。例如前述之A細胞陣列大小為2 x 2,若另外加一項內容,則會變為 3x3:
>>A(3,3)={'美麗的夏天'}
A =
[3x3 double] '馮丁樹' []
[1x4 double] [-5.0000+ 4.0000i] []
[] [] '美麗的夏天'
細胞陣列的語法中,利用大括符形成細胞內容之結構,與中括符作為一般矩陣的結構功能一樣;唯一相異之處是大括符允許其內又有大括符的巢狀結構。因此,細胞陣列中亦可包括另一個細胞陣列。在大括符中,係利用逗點或空格表示行向斷點,用分號作為細胞間之列向斷點。例如:
>>C = {[5 1 2], [9 7]; [1 7 3 4], [8 6 3]}
C =
[1x3 double] [1x2 double]
[1x4 double] [1x3 double]
利用cell指令則可預先設定一個細胞陣列之空集合,以事先保留此細胞陣列之架構。其中cell(n)可產生一個n x n之空細胞陣列:
>>D=cell(3, 4)
D =
[] [] [] []
[] [] [] []
[] [] [] []
若採用多項輸入時,可以直接利用陣列的內容陳述,元素中若為矩陣則必須以矩陣之方式表示;若為文字,則必須加上撇號,其前後則用大括符括起來:
>>D={'天龍八部' '金庸' 1988 [200 220 450]
'紅樓夢' '曹雪芹' 1890 [150 180 160]
'西遊記' '吳承恩' 1880 [120 140 100]};
>>D
D =
'天龍八部' '金庸' [1988] [1x3 double]
'紅樓夢' '曹雪芹' [1890] [1x3 double]
'西遊記' '吳承恩' [1880] [1x3 double]
若要單項輸入或修改,則在等號左邊採用一般括符之索引;右邊則採用大括符置放每個細胞之資料:
>>D(3,3)={1885}
D =
'天龍八部' '金庸' [1988] [1x3 double]
'紅樓夢' '曹雪芹' [1890] [1x3 double]
'西遊記' '吳承恩' [1885] [1x3 double]
實際上其指定方式亦可依細胞陣列元素之總排序之行列順序(亦即依第一行、第二行、…等之順序)。就上述第(3,3)之位置而言,其總排序順位應為9,故:
>>D(9)={1880}
D =
'天龍八部' '金庸' [1988] [1x3 double]
'紅樓夢' '曹雪芹' [1890] [1x3 double]
'西遊記' '吳承恩' [1880] [1x3 double]
又可將西遊記的年代更正為1880了。若要更改某細胞元素內之矩陣中之特定元素,則必須先使用大括符{}先指定細胞之位址,再用標準括符()定矩陣之位置。例如要更改D(3,4)中的第二項140為240時:
>>D{3,4}(1,2)=240
D{3,4}
ans =
120 240 100
顯示該項已經改正。
呼叫的程序亦相同,例如位置D(2,2):
>>D(2,2)
ans =
'曹雪芹'
>>D(1:3)
ans =
'天龍八部' '紅樓夢' '西遊記'
>>D(7:9)
ans =
[1988] [1890] [1880]
注意使用標準括號僅取其位址,而非其內容,要求第9項之內容必須使用大括符:
>>D{9}
ans = 1880
使用大括符可以將其內容組成新的矩陣,以供後來之應用:
>>P=[D{10};D{11};D{12}]
P =
200 220 450
150 180 160
120 240 100
利用細胞索引可以取出次陣列,設定給另外變數:
>>B=D(:,1:3)
B =
'天龍八部' '金庸' [1988]
'紅樓夢' '曹雪芹' [1890]
'西遊記' '吳承恩' [1880]
若僅為單細胞元素之內容,則使用一般括號或大括號索引均可,但若要取其中之之一項或部份時,則必須先使用大括符定位,然後再用一般型式索取矩陣中之個別內容。
若要取得細胞陣列中某特定項之內容,並置放對應之新變數時,可使用deal指令,但兩邊之項目必須相對應:
>>[book, author]=deal(D(:,1),D(:,2))
book =
'天龍八部'
'紅樓夢'
'西遊記'
author =
'金庸'
'曹雪芹'
'吳承恩'
deal這個指令等於進行配對的意思,將等號右邊之對應的資料配給左邊的變數,有如等號,只是其功能在於可同時處理許多變數或一系列變數,故特別適用於細胞陣列或下節要談到的結構資料。若右邊的資料僅有一項,則會以同樣的資料配給左邊的所有參數。這些參數可能是獨立的參數,也可能是另一陣列。例如:
>> sys = {rand(3) ones(3,1) eye(3) zeros(3,1)};
>> sys
sys =
[3x3 double] [3x1 double] [3x3 double] [3x1 double]
>> [a,b,c,d] = deal(sys{:});
>> a
a =
0.9501 0.4860 0.4565
0.2311 0.8913 0.0185
0.6068 0.7621 0.8214
>> b
b =
1
1
1
>> c
c =
1 0 0
0 1 0
0 0 1
>> d
d =
0
0
0
在細胞陣列中,若要刪除某一細胞,只要送給該細胞一個空集合即可,即D(…)=[]。這種細胞陣列亦可利用reshape函數進行大小重排,但整排後之矩陣大小需為原矩陣可除盡之數。
實際上細胞陣列有什麼好處?基於其容許不同大小及型式的內容之特性,有些應用依需要而定。它可以取代一些以逗點分開的變數名單,其中包括函數輸出入名單、作業過程之展示及陣列之建構等。由於MATLAB處理細胞陣列有如分離的變數。如:
>>C={[1 2 1], [1 0 1]}
C =
[1x3 double] [1x3 double]
可以使用細胞陣列中之元素作為其他函數之輸入參數,例如將兩多項式之係數相乘:
>>d=conv(C{1},C{2})
d =
1 2 2 2 1
0 意見 ![]() 此文章的連結
此文章的連結
5.4 結構陣列
5.4 Structural Array
MATLAB之第五版以上也具有結構型之資料型式,可以利用欄位名稱輸入資料庫或直接呼叫,對於以後寫資料庫之擷取型式具有相當大的方便性。而結構陣列之存在,亦可不拘資料之屬性,可為一搬文字敘述或矩陣之型式。這種結構與一般資料庫之分類法則相同,應用時相當方便。
patient
.name ‘張三豐’
.billing 3,838.00
.test [12 01 70 180
3 20 65 150
5 30 79 150]
結構陣列之型式以一個病歷作說明:在一個資料庫下有欄位名稱,若以patient為資料庫之總稱時,其下有name、billing及test等三個欄位,第一個欄位為病人之姓名,第二欄為帳單,第三欄為其檢驗之記錄;後者因每一次有相同的實驗項目,故以矩陣表示。
要建立這些資料並不困難,可在指令窗下輸入:
>>patient.name='張三豐';
>>patient.billing=3838.00;
>>patient.test=[12 01 70 180;3 20 65 150;5 30 79 150];
輸入之後,只要打入patient,即有這筆記錄:
>>patient
patient =
name: '張三豐'
billing: 3838
test: [3x4 double]
最後一項是一矩陣,它僅顯示該矩陣之大小,未顯示其內容,若要知道其內容,可以下指令:
>>patient.test
ans =
12 1 70 180
3 20 65 150
5 30 79 150
由此可見,要知道其下之欄位內容,可以在名稱與欄位名稱間加一點即可,如:
>>patient.name
ans =張三豐
>>patient.billing
ans = 3838
在其他運算式中,若要參照某一欄位內容之值時,亦可採用同樣的語法取得該值。
上面之結構仍然僅能指向某一位病人而已,若有其他病人也需同樣的結構如何表示呢?此時必須在病人之參數加上指標,以表示不同的病人利用同樣的結構建檔。如下建立第二筆記錄:
>>patient(2).name='李四文';
>>patient(2).billing=2424.00;
>>patient(2).test=[11 05 75 200;4 20 80 160;6 30 55 140];
由於patient之內容不只一個,此時若要知道此一patient的資料如何,仍然可在指令窗下指令:
>>patient
patient =
1x2 struct array with fields:
name
billing
test
但其結果出人意外的與前面不同,主要是我們已將patient變成一個1x2 的結構性矩陣,而其下之欄位名稱則會加以標明,不再標出其內容,不過若下如下之指令,則會有所要的資料:
>>patient(2)
ans =
name: '李四文'
billing: 2424
test: [3x4 double]
>>patient(1)
ans =
name: '張三豐'
billing: 3838
test: [3x4 double]
至少目前應有張三豐及李四文兩筆病人的記錄。其餘可以採用類似方法增加筆數。基本上每一新記錄均需維持相同的欄位名稱及數量,才能組成一個結構。
雖然這些資料均以結構型式存於檔案中,但如前面所述,其單獨之變數仍可以取出隨意運用,如此可以增加變數應用之彈性,例如繪出張三豐之實驗之資料:
>>bar(patient(1).test)
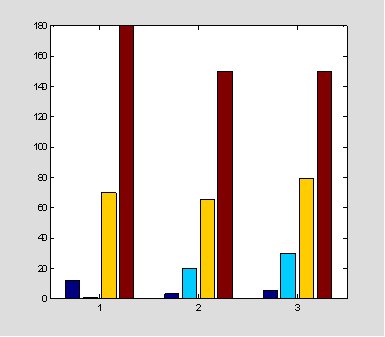
張三豐的病歷資料
故其內在之資料要如何處理,其情況與一般的手法相同,只是目前仍然不知道張三豐的病歷到底表示的是什麼而已。
若要瞭解這個檔案之欄位名稱,除直接打入該檔的名稱外,亦可用fieldnames這一個指令:
>>fieldnames(patient)
ans =
'name'
'billing'
'test'
其中之某欄位亦可利用rmfield這個指令去除掉:
>>patient2=rmfield(patient,'test')
patient2 =
1x2 struct array with fields:
name
billing
因此,基本結構patient2與patient相同,但少了test這個欄位。一次若要除去好幾個欄位時,則必須使用文字矩陣來處理。以往討論到矩陣時,均以數值為主,故矩陣內的項目均為數值格式,且用中括號[]作為範圍;碰到項目為文字型式時,其處理方式需以單一之文字為對象。若要採用長度不一的文字矩陣時,則各項之文字必須用撇號 ’ 號括起來,其矩陣亦必須以大括號{}作為範圍,如{'張三豐','李四文','陳五分'}是。故若要除去許多欄位時,可採用下面的方法:
>>patient2=rmfield(patient,{'test' 'billing'})
patient2 =
1x2 struct array with fields:
name
因此,patient2僅剩下name一欄了。當然欄位亦可無中生有,只要將要直接添加新欄位並設定一個值給它即可,如:
>>patient2(1).billing=20
patient2 =
1x2 struct array with fields:
name
billing
換言之,整個檔案均會增加一個欄位billing,而第二筆記錄欄位已存在,但仍為空值,因為尚有未該筆記錄之billing的內容:
>>patient2(2).billing
ans =
[]
>>patient2(1).billing
ans =
20
上述方法亦可用另一指令setfield來逹成:
>>setfield(patient2(2),'billing', 30)
ans =
name: '李四文'
billing: 30
事實上,結構化檔案亦可以利用struct指令來達成:
>>patient3=struct('name',{'陳五分','趙六錢'},'billing',{5656.00, 7878.00},'test',{[1 2],[3 4]})
patient3 =
1x2 struct array with fields:
name
billing
test
>>patient3(1)
ans =
name: '陳五分'
billing: 5656
test: [1 2]
>>patient3(2)
ans =
name: '趙六錢'
billing: 7878
test: [3 4]
上述指令之結構可能需要補充說明一下,以便發揮一指神功的效果。struct後面括號內包含的項目為各欄位及對應之值。當然這些值可能為文字,也可能為數值。基本上文字均需使用撇號 ’ 括起來。對應欄位後面應使用中括號[]括起來,裡面的項目內容若有好幾筆資料,則需用逗號分開。各筆若為矩陣,則需依矩陣的表示法輸入,並用中括號[]括起來。下面兩個例子可能給大家一些概念:
>>s = struct('greetings',{{'Hello, there','新年好,萬事如意'}},'lengths',[5 3])
s =
greetings: {'Hello, there' '新年好,萬事如意'}
lengths: [5 3]
>>s(1)
ans =
greetings: {'Hello, there' '新年好,萬事如意'}
lengths: [5 3]
顯然s內容僅有一項,但greetings內應有兩項:
>>s.greetings(1)
ans =
'Hello, there'
>>s.greetings(2)
ans =
'新年好,萬事如意'
再看看同一個例子,但稍做修改:
>>s = struct('greetings',{'Hello, there','新年好,萬事如意 '},'lengths',[5 3])
s =
1x2 struct array with fields:
greetings
lengths
>>s(1)
ans =
greetings: 'Hello, there'
lengths: [5 3]
>>s(2)
ans =
greetings: '新年好,萬事如意 '
lengths: [5 3]
此時s有兩筆記錄,且其lengths:均為 [5 3],足見不足的項目它會用同一個值補上去。
再看看它在說明中提供的例子:
>>ss = struct('type',{'big','little'},'color','red','x',{3 4})
ss =
1x2 struct array with fields:
type
color
x
>>ss(1)
ans =
type: 'big'
color: 'red'
x: 3
>>ss(2)
ans =
type: 'little'
color: 'red'
x: 4
這樣的結果會更清楚了,讀者應可從中體會其功能。下面是一個比較複雜的例子:
>>A=struct('data',{[3 4 7;8 0 1], [9 3 2; 7 6 5]}, ...
'personal',{struct('testyear',1999,'height',[163 178 172],...
'weight',[80 86 60]),struct('testyear',2000,'height',[157 168 159],...
'weight',[48 50 48])})
A =
1x2 struct array with fields:
data
personal
>>A(1)
ans =
data: [2x3 double]
personal: [1x1 struct]
>>A(1).data
ans =
3 4 7
8 0 1
>>A(1).personal
ans =
testyear: 1999
height: [163 178 172]
weight: [80 86 60]
>>A(2).personal
ans =
testyear: 2000
height: [157 168 159]
weight: [48 50 48]
其他相關指令如disp也可以看其結構:
>>disp(A)
1x2 struct array with fields:
data
personal
而函數isfield則可檢驗檔案結構內是否有某一特定欄位,如:
>>f=isfield(A,'data')
f =
1
下表為有關處理matlab結構之各函數:
- MATLAB资料结论
- Matlab资料
- 结论
- MATLAB资料输入输出
- matlab 资料分享
- matlab资料收藏
- MATLAB数学建模资料
- matlab 学习资料收集
- Matlab资料收纳
- Matlab积分相关资料
- MATLAB 史上最全的资料
- matlab入门学习资料
- matlab工具箱的相关资料。。。
- 自学MATLAB很好的资料
- 自学MATLAB很好的资料
- Matlab技术论坛精彩资料大汇总
- MATLAB学习资料合集下载
- MATLAB中双纵坐标资料整理
- MATLAB矩阵
- 2007全国税务信息化成果与技术交流论坛发言(速记)
- MATLAB关系控制
- MATLAB函数
- Fedora 9安装vmware tools解决方案
- MATLAB资料结论
- MATLAB自定义函数
- Felomeng翻译:IKVM的使用——将java程序转化为.net程序或类库
- MATLAB资料输入输出
- 程序员发展方向
- MATLAB多项式应用
- linux下的开源简繁转换工具cconv--支持词语转换
- MATLAB方程式求解
- How to use GCC to build DLL by DEF file in MinGW?


